Serving open-source large language models efficiently on Vertex AI Model Garden
Xiang Xu
Software Engineer
Pengchong Jin
Software Engineer
Google Cloud is dedicated to providing customers with the best technologies, whether they are powered by Google's own advancements or come from our open source community. We have over 100 open-source models in Vertex AI’s Model Garden, including Meta’s Llama 2 and Code-Llama.
Today, we are excited to announce an updated LLM-efficient serving solution that improves serving throughput in Vertex AI. Our solution is built on the popular open-source vLLM libraries and is competitive with the current state-of-the-art LLM serving solutions in the industry.
In this blog, we will describe our solution in detail with benchmark results and provide you with the Colab notebook example to help you get started.
Our solution
Our solution is based on the integration of the state-of-the-art open-source LLM serving framework vLLM, which includes features such as:
- Optimized transformer implementation with PagedAttention
- Continuous batching to improve the overall serving throughput
- Tensor parallelism and distributed serving on multiple GPUs
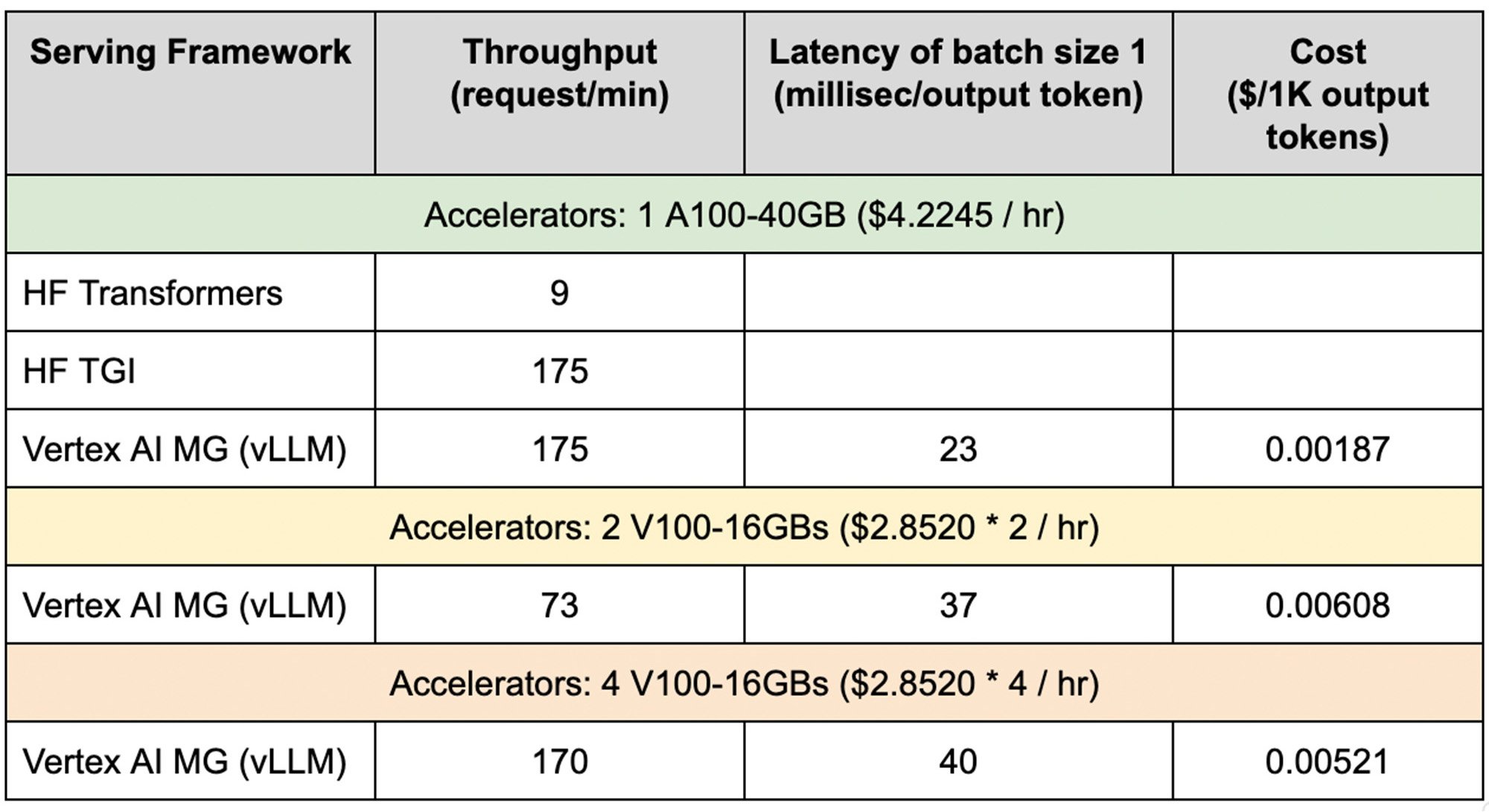
We conducted benchmark experiments of our solution on Vertex AI, where we fully reproduced the benefit of vLLM on Vertex AI Online Prediction. The benchmark results are below.
We used OpenLLaMA 13B, the open-sourced reproduction of Llama, as our model architecture for evaluation. We compared our serving solution (Vertex Model Garden vLLM) with HuggingFace Transformers (HF Transformers), the most popular LLM library and HuggingFace Text Generation Inference (HF TGI), another state-of-the-art LLM serving library but not open sourced. We sampled 1000 prompts of different input/output lengths in the ShareGPT dataset and measured the serving throughput.
From our benchmark results, the Vertex AI serving stack achieved up to 19X higher throughput compared to HF Transformers and on par performance with the state-of-the-art HF TGI. This means that users can serve more requests at a lower cost. We also showed that it is possible to serve LLMs using multiple GPUs in a single node and included these benchmark results. We further tested the same solution on the latest Llama 2 and Code Llama and it produced similar results.
Get started with custom serving from Vertex AI Model Garden
We have provided the Colab notebook example in Vertex AI Model Garden, which shows how to deploy open-source foundation models on Vertex.
An example of deploying the OpenLLaMA models to Vertex AI with vLLM serving can be accessed here. We provide a pre-built vLLM serving docker image. Deploying Llama 2 and Code Llama follows similar steps. You can easily call the Vertex AI SDK API to deploy models using the docker image:
After the model has deployed to Vertex AI, you will be able to send requests with a prompt to the endpoint and get a response:
NOTE: These code snippets are just for demonstration, please refer to the notebook for the entire process to deploy the model.