Protect data from disasters using new Asynchronous Replication
David Seidman
Group Product Manager
Dengkui Xi
Engineering Manager
In today's business landscape, data availability and integrity are paramount. Disasters, whether natural or man-made, can disrupt operations and pose a significant risk to critical information.
To address this, today we are introducing Persistent Disk Asynchronous Replication, which enables disaster recovery for Compute Engine workloads by replicating data between Google Cloud regions, providing a sub-1 min Recovery Point Objective (RPO) and low Recovery Time Objective (RTO).
Simplicity is central to the design of this solution. Replication is managed with a few API calls — there are no required VM agents, no dedicated replication VMs, no constraints on supported guest operating systems, and no performance overhead on the workload. PD Async Replication works at the block infrastructure level, delivering a fast, common infrastructure foundation to protect against disasters. It is designed to be simple to onboard, operate, and monitor, and can be used in combination with other forms of data protection, including disk clones, regional (synchronous replication) disks, and snapshots. Replication is performed directly from a primary disk in the region where you run your workload, to a recovery disk you create in a secondary region.
“Persistent Disk Asynchronous Replication delivers the solid foundation we need for infrastructure-based Disaster Recovery, and helps us meet our regulatory requirements for low RPO/RTO data protection. PD Async Replication supports our full lifecycle of DR testing, failover and failback.” - Nicola Carotti, Head of Cloud Center of Excellence, Intesa Sanpaolo
Setting up replication
You can enable PD Async Replication on your existing PD disks with just two calls in the API, gcloud, or Google Cloud console. First, create a new blank disk in the secondary region with a reference to the primary disk you want to protect. Then, start replication from the primary disk with a reference to the secondary disk. From that point on, data is automatically replicated between disks, typically with an RPO of less than a minute, depending on the change rate of the disk. This setup workflow helps to ensure that an explicit action is taken in both regions before any data is transferred. You don't need to reconfigure your network to use PD Async Replication.
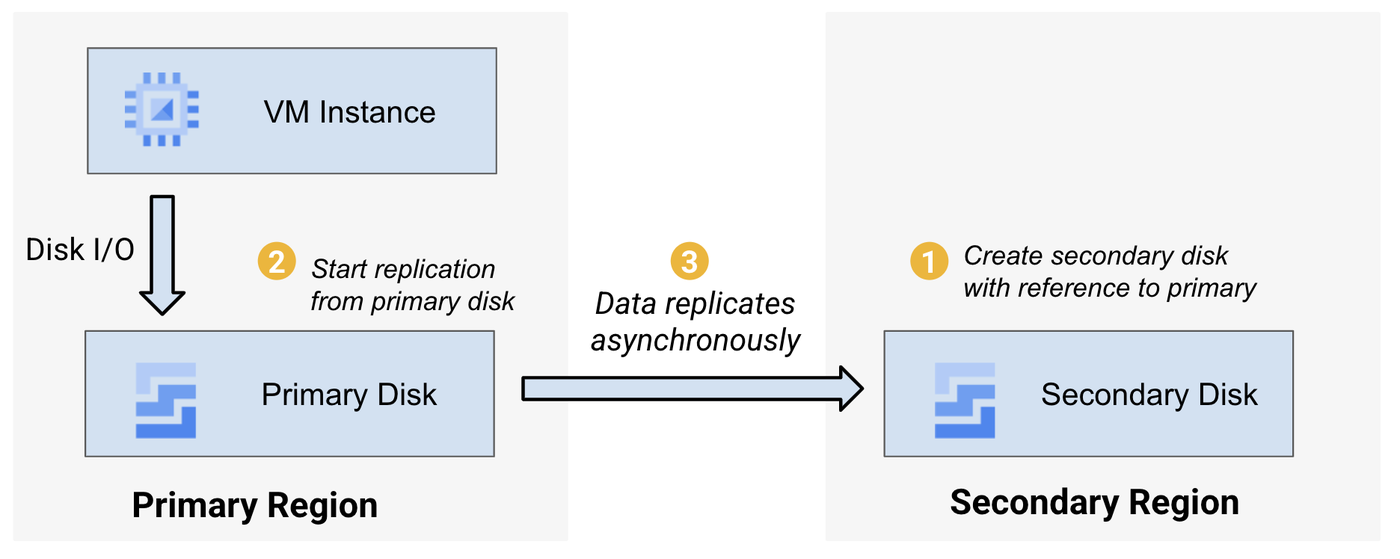
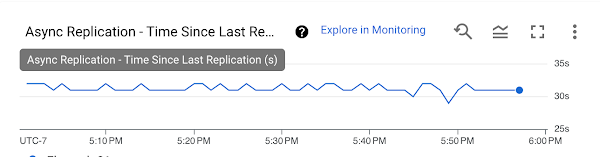
Once PD Async Replication is running, you can observe the time since last replication and the network bytes sent in Cloud Monitoring. It is up to the operations teams responsible for a workload to decide when a disaster has occurred in the primary region and when to initiate a failover. To begin the failover, stop replication between disks and attach the secondary disk to a VM in the secondary region; you can accomplish this within minutes. To restore the workload back to the primary region after a previous failover to the secondary region, create a new replication pair back to the primary region so that the workload can failback. By replicating data between data centers in different regions, you create resilient data replicas that safeguard against localized disruptions caused by natural disasters or other localized events.
Use consistency groups for complex stateful workloads
In cases where workloads have distributed, dependent data across disks and VM instances, consistency groups allow for coordinated management of dependent data. With consistency groups, PD Async Replication enables simultaneous and atomic data replication by automatically synchronizing the replication period across all disks in the group. This helps to ensure that data is consistent between primary and secondary disks, for successful workload recovery in the event of a disaster.
Testing disaster recovery
To help ensure that recovery procedures will work in a real disaster, we recommend running tests periodically in the secondary region. You can do this without disrupting or disconnecting PD Async Replication by bulk-cloning the secondary disks with a consistency group applied, even while they are receiving new data.
Deploy for high availability and disaster recovery
Regional Persistent Disk (Regional PD) and PD Async Replication are designed to be used together for workloads that require both high availability (HA) and disaster recovery. You can configure a Regional PD to be the primary or secondary async disk, which can work in combination with a zonal disk in the primary or secondary region. In a scenario where an outage occurs in just one zone in the primary region where Regional PD is configured, the disk will continue to replicate from the remaining healthy zone to the secondary region. Note that PD Async Replication is set up between two distinct disks, while each Regional PD is a single disk that stores data in two zones and is attachable in two zones.
Improve your HA and DR posture
By leveraging PD Async Replication and consistency groups, businesses gain robust data protection and recovery capabilities. This approach helps you safeguard critical data against disasters, minimize downtime, provide data consistency, and enhance fault tolerance. With the power of asynchronous replication and consistency groups, you can help build a resilient platform that provides continuous access to data even in the face of unforeseen disruptions.
You can access PD Async Replication through the console, Compute Engine API, gcloud tool, Terraform, and Cloud Monitoring. You can learn more by reading the public documentation.

