Exploring synthetic data generation with BigQuery DataFrames and LLMs
Shobhit Singh
Software Engineer BigQuery
Firat Tekiner
Senior Staff Product Manager Data and AI
In the realm of big data analytics, a common challenge has been the separation between data processing and machine learning workflows. Traditionally, data engineers would use tools like Apache Spark for large-scale data processing in data warehouses like BigQuery, while data scientists would leverage libraries like pandas and scikit-learn for machine learning tasks. This disjointed approach led to inefficiencies, data duplication, and delays in deriving insights from data.
At the same time AI's success hinges on vast amounts of data. Therefore, generation and management of synthetic data — fabricated data that mimics real-world data — has become a critical operation for any business. Synthetic data is generated either algorithmically to model datasets used in production or through ML algorithms training such as generative AI. This synthetic data can emulate operational or production data, facilitating the training of machine learning (ML) models or the evaluation of mathematical models.
BigQuery DataFrames as a solution
BigQuery DataFrames bridges the gap between data processing and machine learning by providing a unified, scalable, and cost-efficient platform for both tasks. This empowers organizations to accelerate their data-driven initiatives, improve collaboration between teams, and unlock the full potential of their data. BigQuery DataFrames is an open-source python package providing pandas-like DataFrame and scikit-learn-like ML library for big data. It utilizes BigQuery and the rest of Google Cloud as the storage and compute platform under the hood. It provides easy compute extensibility by integrating with Google Cloud Functions, and generative AI capabilities, including the state-of-the-art generative AI models, by integrating with Vertex AI. This versatile set of capabilities allow BigQuey DataFrames to be used for developing scalable AI applications.
BigQuery DataFrames allows you to generate artificial data at scale and mitigates a number of issues around moving the data outside of your ecosystem or using third-party solutions. When dealing with sensitive personal data, synthetic data offers a privacy-preserving alternative. It allows you to share and collaborate on datasets without exposing individuals' private information. In addition, this allows deploying analytical models into production. Synthetic data also provides a safe environment for testing and validation. You can simulate edge cases, outliers, and rare events that might not be present in your real dataset. In addition, before making changes to your data warehouse schema or ETL processes, synthetic data allows you to simulate the impact of those changes, preventing costly errors and downtime.
BigQuery DataFrames and synthetic data generation in action
Synthetic data generation is a need that arises in many applications where:
- Real data generation is slow and expensive
- Sharing original data has a high governance bar compared with synthetic data, i.e., there are stringent rules, regulations, and oversight
- Larger scale data is needed for simulations
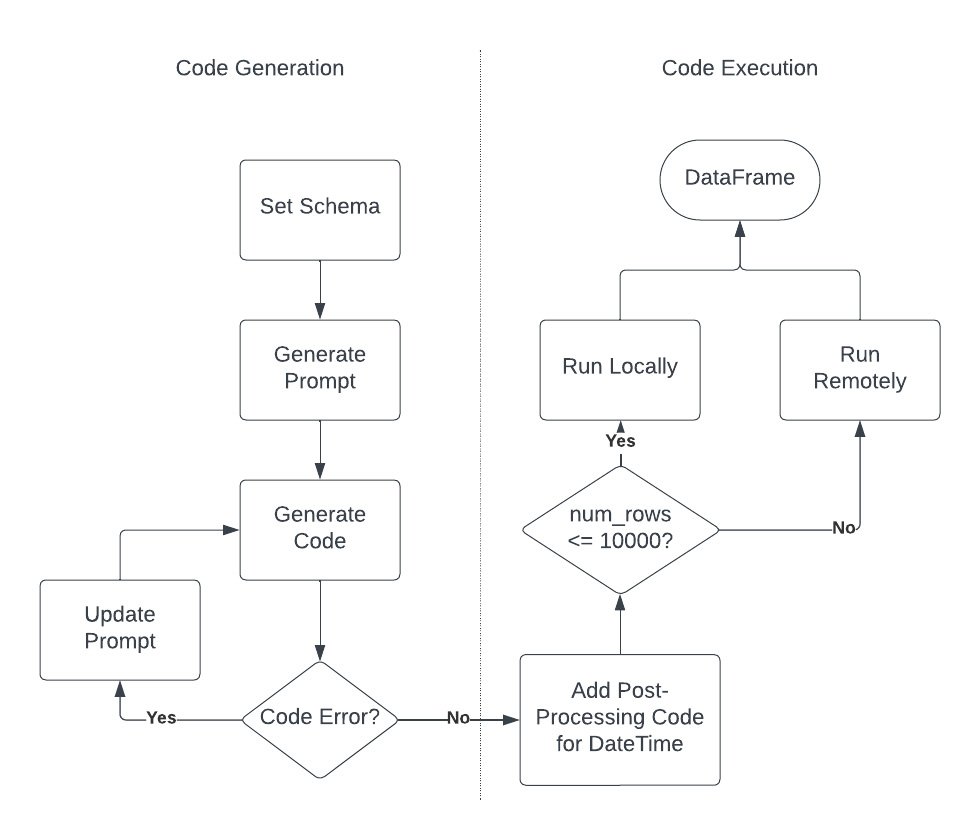
Let's see the integration of BigQuery DataFrames together with LLMs to generate synthetic data right inside BigQuery using BigQuery DataFrames. This process has two main stages and number of substages as below:
Code generation
1. Set the Schema and provide instructions to the LLM
1.1 The user knows the schema of the data they need
1.2 They have a high level sense of the code that could generate such data
1.3 They express the intent to generate code to generate such data on a small scale in a natural language (NL) prompt
1.4 Enrich the prompt with hints to guide the LLM to generate correct code
2. Send the prompt to the LLM and get generated code
Code execution
3. Review and execute the code, loop back to step 1.1 if needed (human-in-the-loop)
4. Deploy the code as a remote_function and execute it at the desired scale
5. Post process to produce the data in the desired shape
Setting up and initializing the library
To begin, let’s install, import and initialize the BigQuery DataFrames library.
Then, let’s use the GeminiTextExtractor to generate code that can generate the intended data, using the Vertex AI integration underneath.
Step 1 - Generate synthetic data from user-specified schema
Step 1.1 - Specify high-level schema information
Let’s say you want to generate demographic data with name, age and gender, and you want Latin American names that are gender inclusive. We express this intent in the prompt. We also include additional information to guide the LLM to generate the right code:
Step 1.2 - Call the LLM to generate the code
Notice that we intend to generate code to create 100 rows of the intended data before scaling it later. Since we already defined the schema, now let’s call into the LLM to generate the code:
The generated code looks like this:
Step 2 - Execute code
In the previous step we provided all the guidance needed to the LLMs together with the description of the schema of the dataset we wish to generate. In this step, we verify and execute the code. This process is important because it brings the human in the loop and adds another step to validate the output to be generated.
Step 2.1 - Local verification of the generated code with a small sample
The code that was generated in the previous stage looks alright. But first let’s verify that it executes correctly:
At this point, if the generated code hadn’t run or we wanted to fine-tune the data distribution, we would go back to the prompt and try updating it and follow the steps again. We could include the generated code and the issue we want to fix as additional information in the LLM prompt.
Step 2.2 - Deploy the code as a remote function
The data looks like a good fit based on what we wanted it to do, therefore, we can move forward and deploy the code as a remote function.
Remote functions support scalar transformation, so we can use an indicator (in this case we pick integer) input, and produce a string output, which is the dataframe produced by the code serialized as json. We also need to specify any external package dependency, which in our case are faker and pandas.
Step 2.2.1 - Scale the data generation
Let’s say we want to generate one million rows of synthetic data. Since our generated code produces 100 rows in one run, we can initialize an indicator dataframe with 1M/100 = 10K indicator rows. Then we can apply the remote function to produce 100 synthetic data rows for each indicator row.
Step 2.2.1 - Flatten the JSON
At this point each item in df["json_data"] is a json serialized array of 100 records. Let’s flatten that into one record per row using direct SQL.
There you have it, one million synthetic data rows in the result_df DataFrame that are ready to use, or to save in a BigQuery table for future use (using the to_gbq method). The costs involved in this exercise are that of the BigQuery, Vertex AI, Cloud Functions, Cloud Run, Cloud Build and Artifact Registry services. See BigQuery DataFrames pricing for more details. BigQuery jobs processed ~62MB bytes and used ~276K slot milliseconds in total.
Generating synthetic data from an existing table schema
In the previous step we demonstrated how synthetic data can be generated through a supplied schema. We could also generate synthetic data for an existing table. For example, you might be creating a copy of the production dataset for development purposes. While doing that you are looking to maintain similar data distribution together with the schema. In order to achieve this you would have to craft the LLM prompt from the column names, types, and any column descriptions in the existing table. In addition, data profiling metrics could be derived from the existing data in the table and added to the prompt, some examples being:
-
Any data distribution for the numeric columns. You could use DataFrame.describe to get the column statistics.
-
Any hints for the data format for the string or date/time columns. You could use DataFrame.sample or Series.sample.
-
Any hints about the unique values in a categorical column. You could use Series.unique.
Generating a fact table for an existing dimension table
We could generate a synthetic fact table for an existing dimension table, which then could then be joined back to the dimension table. For example, if you have a table usersTable with schema (userId, userName, age, gender), you could generate a transactionsTable with schema (userId, transactionDate, transactionAmount) where the userId is the key relationship. The steps to achieve this would be as follows:
-
Create LLM prompt to generate data for schema (transactionDate, transactionAmount)
-
(Optional) To give a more natural distribution to the fact data, indicate in the prompt that the code should generate a random number of rows, say between 0 and 100 instead of fixed 100. You would have to compensate batch_size for that, which in this case should be set to 50 (assuming symmetrical distribution). Expect that the final data generated may be a bit off from the desired_num_rows due to randomness.
-
Initialize the indicator dataframe with userId from the usersTable instead of the range used in the case of supplied schema.
-
Run the remote function of the LLM-generated code on the indicator dataframe as we did in the case of the supplied schema.
-
Select userId in addition to (transactionDate, transactionAmount) in the final result.
Conclusions and resources
In this demonstration, we explored the use of BigQuery DataFrames for generating synthetic data, a crucial element in today's AI landscape. Due to data privacy concerns and the need for large datasets, synthetic data offers a valuable alternative for training machine learning models and testing systems. BigQuery DataFrames provides a powerful platform for this task, integrating seamlessly with your data warehouse and Vertex AI, including the advanced Gemini model. This allows you to generate data directly within your data warehouse, eliminating the need for third-party solutions or data movement.
We showed a step-by-step process for generating synthetic data using BigQuery DataFrames and LLMs. This involves:
-
Code generation: Defining the desired data schema and using natural language prompts to instruct the LLM to generate the corresponding code.
-
Code execution: Deploying the code as a remote function and executing it at scale to generate large volumes of synthetic data.
You can find the complete Colab Enterprise notebook source code here.
In addition, we highlighted the versatility of our approach, by also providing three options on how it can be used to:
-
Generate data from a user-specified schema: Ideal when the real data is expensive to produce or has high governance restrictions.
-
Generate data based on an existing table schema: Useful for creating development datasets that mimic production data.
-
Generate a fact table for an existing dimension table: Enables the creation of synthetic transactional data linked to existing entities.
By leveraging BigQuery DataFrames and LLMs, organizations can efficiently generate synthetic data, addressing data privacy concerns and accelerating AI development.
To learn more about these new features, check out the documentation.
Googlers Jiaxun Wu and Manoj Gunti contributed to this blog post. Many Googlers contributed to make these features a reality.

