How PLAID put the 'real' in real-time user analytics with Bigtable

Jun Kusahana
Senior Software Engineer, PLAID
Editor’s note: Today we hear from PLAID, the company behind KARTE, a customer experience platform (CxP) that helps businesses provide real-time personalized and seamless experiences to their users. PLAID recently re-architected its real-time user analytics engine using Cloud Bigtable, achieving latencies within 10 milliseconds. Read on to learn how they did it.
Here at PLAID, we rely on many Google Cloud products to manage our data in a wide variety of use cases: AlloyDB for PostgreSQL for relational workloads, BigQuery for enterprise data warehousing, and Bigtable, an enterprise-grade NoSQL database service. Recently, we turned to Bigtable again to help us re-architect our core customer experience platform — a real-time user analytics engine we call “Blitz.”
To say we ask a lot of Blitz is understatement: our high-traffic environment receives over 100,000 events per second, which Blitz needs to process within a few hundred milliseconds end-to-end. In this blog post, we’ll share how we re-architected Blitz with Bigtable and achieved truly real-time analytics under heavy write traffic. We’ll delve into the architectural choices and implementation techniques that allowed us to accomplish this feat, namely, implementing a highly scalable, low-latency distributed queue.
What we mean by real-time user analytics
But first, let’s discuss what we mean when we say ‘real-time user analytics’. In a real-time user analytics engine, when an event occurs for a user, different actions can be performed based on event history and user-specific statistics. Below is an example of an event data and a rule definition that filters to a specific user for personalized action.
Figure 1: Event Data
Figure 2: Pseudo-code for rule definition
This is pseudo-code for a rule to verify whether "userId-xxx" is a user who is a "member", has an average purchase price of 10,000 yen or more in a year, had a session count of 10 or more last week, but who purchased little to nothing.
When people talk about real-time analytics, they usually mean near-real-time, where statistics can be seconds or even minutes out-of-date. However, being truly real-time requires that user statistics are always up-to-date, with all past event histories reflected in the results available to the downstream services. The goal is very simple, but it’s technically difficult to keep user statistics up-to-date — especially in a high-traffic environment with over 100,000 events per second and required latency within a few hundred milliseconds.
Our previous architecture
Our previous analytics engine consisted of two components: a real-time analytics component (Track) and a component that updates user statistics asynchronously (Analyze).
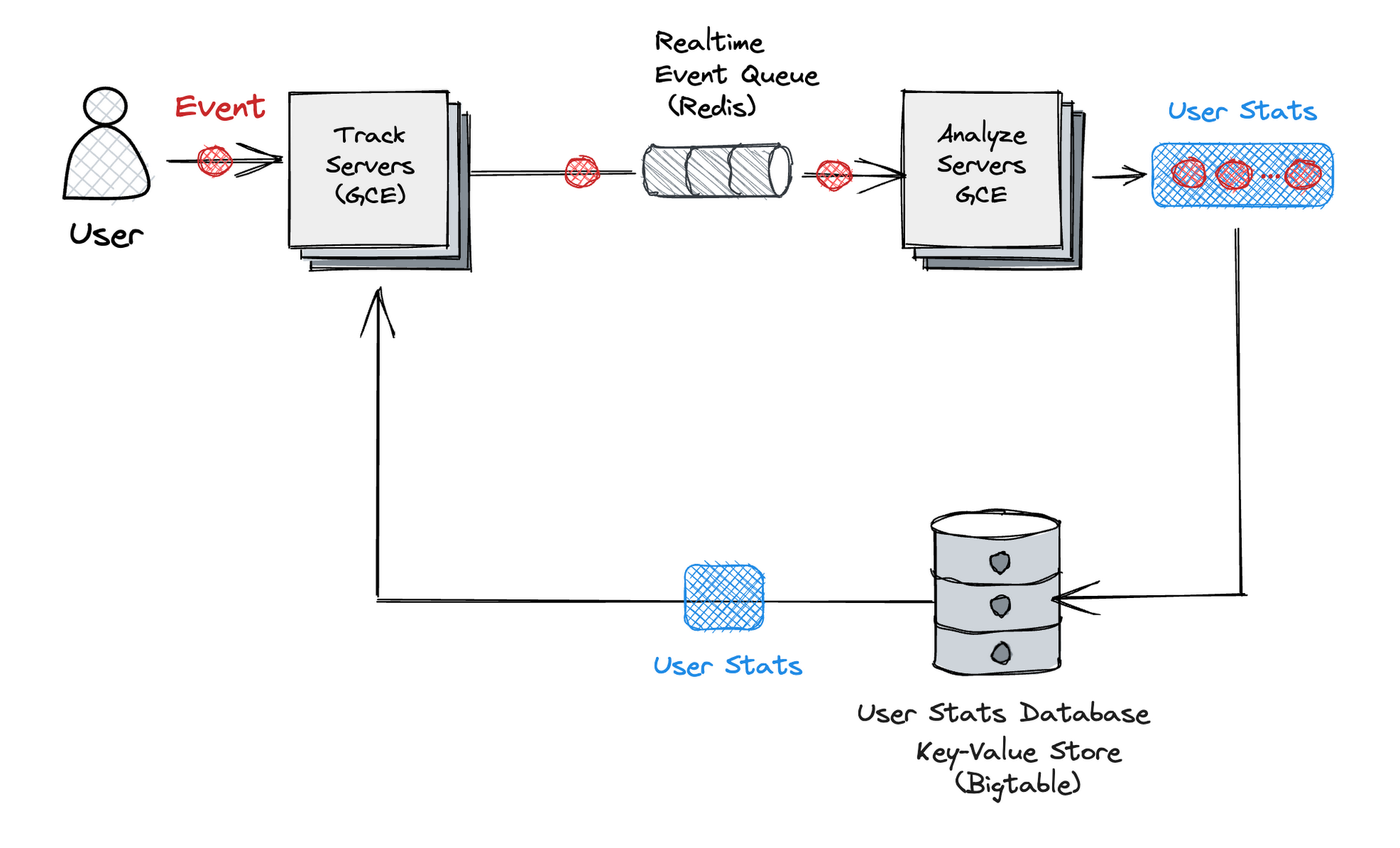
The key points of this architecture are:
In the real-time component (Track), the user statistics generated in advance from the key-value store are read-only, and no writing is performed to it.
In Analyze, streaming jobs roll up events over specific time windows.
However, we wanted to meet the following strict performance requirements for our distributed queue:
High scalability - The queue must be able to scale with high-traffic event numbers. During peak daytime hours, the reference value for the write requests is about 30,000 operations per second, with a write data volume of 300 MiB/s.
Low latency that achieves both fast writes and reads within 10 milliseconds.
But the existing messaging services could not meet both high-scalability and low-latency requirements simultaneously — see Figure 4 below.

Our new real-time analytics architecture
Based on the technical challenges explained above, Figure 5 below shows the architecture after the revamp. Changes from the existing architecture include:
We divided the real-time server into two parts. Initially, the frontend server is responsible for writing events to the distributed queue.
The real-time backend server reads events from the distributed queue and performs analytics.
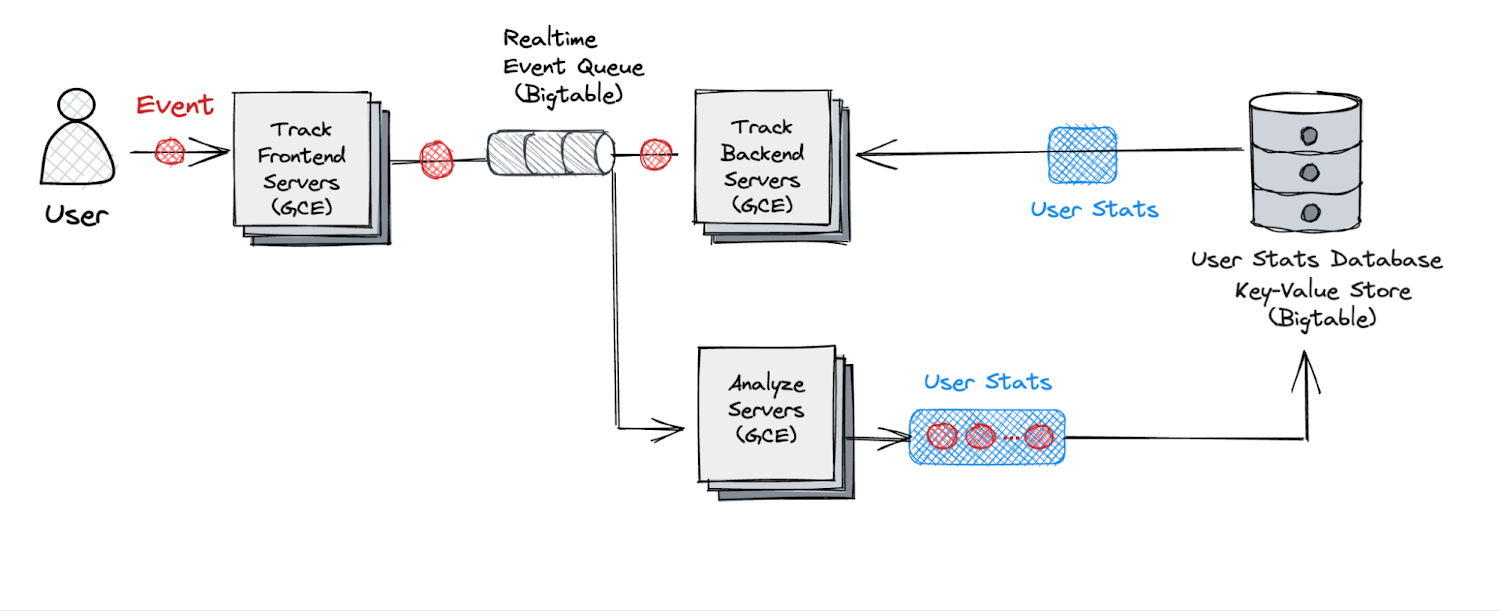
In order to meet both our scalability and latency goals, we decided to use Bigtable, which we already used as our low-latency key-value store, to implement our distributed queue. Here’s the specific method we used.
Bigtable is mainly known as a key-value store that can achieve latencies in the single-digit milliseconds and be scaled horizontally. What caught our attention is the fact that performing range scans in Bigtable that specify the beginning and end of row keys is also fast.
The specific schema for the distributed queue can be described as follows:
The key point is the event timestamp added at the end. This allows us to perform range scans by specifying the start and end of the event timestamps.
Furthermore, we were able to easily implement a feature to delete old data from the queue by setting a time-to-live (TTL) using Bigtable garbage collection feature.
By implementing these changes, the real-time analytics backend server was able to ensure that the user's statistics remain up-to-date, regardless of any unreflected events.
Additional benefits of Bigtable
Scalability and low latency weren’t the only things that implementing a distributed queue with Bigtable brought to our architecture. It was also cost-effective and easy to manage.
Cost efficiency
Thanks to the excellent throughput of the SSD storage type and a garbage collection feature that keeps the amount of data constant by deleting old data, we can operate our real-time distributed queue at a much lower cost than we initially anticipated. In comparison to running the same workload on Pub/Sub, our calculations show that we operate at less than half the cost.
Less management overhead
From an infrastructure operation perspective, using the Bigtable auto-scaling feature reduces our operational cost. In case of a sudden increase in requests to the real-time queue, the Bigtable cluster can automatically scale out based on CPU usage. We have been operating this real-time distributed queue for over a year reliably with minimal effort.
Supercharging our real-time analytics engine
In this blog post, we shared our experience in revamping our core real-time user analytics engine, Blitz, using Bigtable. We successfully achieved a consistent view of the user in our real-time analysis engine under high traffic conditions. The key to our success was the innovative use of Bigtable to implement a distributed queue that met both our high scalability and low latency requirements. By leveraging the power of Bigtable low-latency key-value store and its range scan capabilities, we were able to create a horizontally scalable distributed queue with latencies within 10ms.
We hope that our experience and the architectural choices we made can serve as a valuable reference for global engineers looking to enhance their real-time analytics systems. By leveraging the power of Bigtable, we believe that businesses can unlock new levels of performance and consistency in their real-time analytics engines, ultimately leading to better user experiences and more insightful decision-making.
Looking for solutions to up your real-time analytics game? Find out how Bigtable is used for a wide-variety of use cases from content engagement analytics and music recommendations to audience segmentation, fraud detection and retail analytics.

