Announcing Cloud HPC Toolkit blueprint for AI/ML with the NeMo Framework on A3 VMs
Sam Skillman
Senior Systems and Solutions Architect, HPC
Annie Ma-Weaver
Group Product Manager, Google Cloud HPC
Many AI/ML workloads, including training large language models (LLMs), demand state-of-the-art high performance computing (HPC) systems. Many people doing LLM development and training are familiar with traditional HPC systems and schedulers such as Slurm, but need help optimizing these systems for AI/ML needs. We make it straightforward to create HPC systems on Google Cloud, ready for your most demanding models, using the Cloud HPC Toolkit.
The Cloud HPC Toolkit is a Google product that helps simplify the creation and management of HPC systems for AI/ML and traditional HPC workloads. The Toolkit includes a variety of features that:
- Provision and configure HPC clusters quickly and easily
- Install and manage AI/ML software stacks
- Optimize HPC clusters for AI/ML workloads
- Monitor HPC clusters
Today we’re excited to share a new Cloud HPC Toolkit blueprint for ML workloads. This blueprint helps you spin up a HPC system running on A3 VMs with NVIDIA H100 Tensor Core GPUs that is ready for training large language models (LLMs) and other AI/ML workloads, incorporating Google Cloud’s best practices to ensure high training performance.
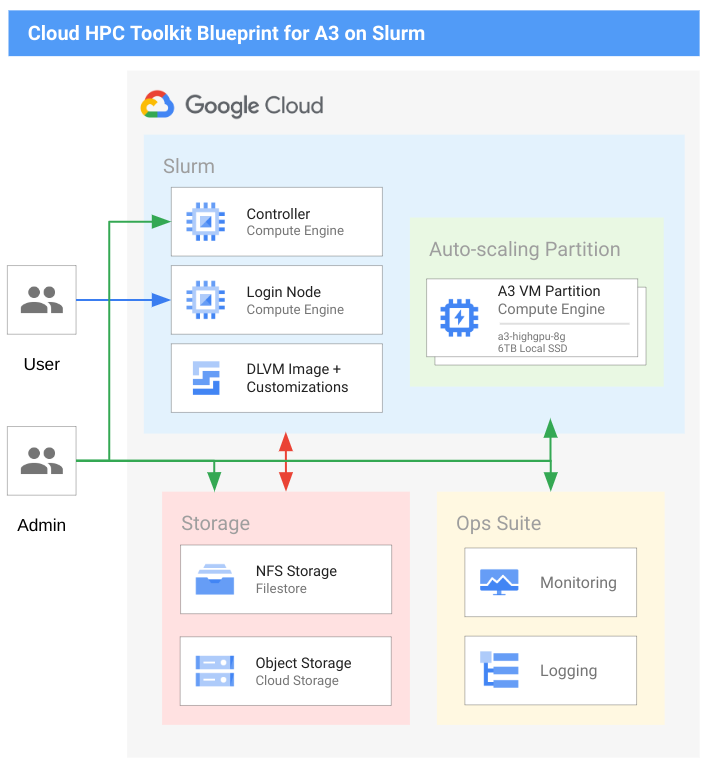
In particular, deploying large-scale HPC and AI/ML clusters with NVIDIA GPUs requires careful coordination of multiple infrastructure components including networking configuration. The Cloud HPC Toolkit makes it simple to accomplish this through an easy-to-use blueprint with best practices already in place. The ML blueprint provides the following components and capabilities:
- Configure and enable 1 Tbps networking via five NICs with a customized Deep Learning VM image
- Shared storage using fully managed Filestore (NFS)
- Popular open-source scheduler Slurm
- Creation of management VMs for login node and controller functions
- Setup of an auto-scaling partition with A3 VMs (8 X NVIDIA H100 GPUs) and 6TB Local SSD per VM
- Pre-configured user environment that includes Conda, Tensorflow, NVIDIA Drivers, NVIDIA CUDA, NVIDIA Enroot/Pyxis, NVIDIA TensorRT and Pytorch
Deploying an A3 cluster and running the NVIDIA NeMo Framework
To deploy an A3 cluster, follow the instructions found here. From there, you can follow the standard Playbooks and NVIDIA NeMo Launcher Guide in the NVIDIA NeMo Framework User Guide. In addition, there are a few modifications for higher-performance networking across A3 VMs that you’ll need to enable to utilize the GPUDirect-TCPX functionality. For an example of how to make those modifications and launch a basic example of NeMo Framework Pre-Training, see the README in the HPC Toolkit Repository, part of which is copied below:
From here, you may find it simpler to customize the configuration files for your cluster and the specific NeMo Framework workloads you wish to perform, as opposed to using command line arguments. For example, real workloads would use real training data and you may want to explore all tuning and configuration parameters for your use case.
Come visit the Google Cloud booth #808 at NVIDIA GTC 2024 to learn more about our products, tools and infrastructure for your AI/ML needs. Learn more about HPC Toolkit in our dedicated session. We’ll be running demos of the ML blueprint in our booth and have experts available to answer your questions. We look forward to meeting you!
