Non hai potuto partecipare a Next '24? Tutte le sessioni sono ora disponibili on demand. Guarda ora.
Architettura di supercomputing integrata
AI Hypercomputer
Hardware, software e consumo ottimizzati per l'AI, combinati per migliorare produttività ed efficienza.

Panoramica
Hardware ottimizzato per le prestazioni
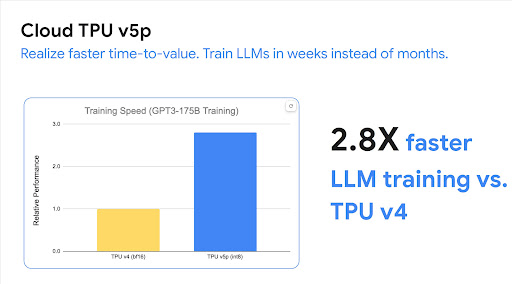
La nostra infrastruttura ottimizzata per le prestazioni, che include Google Cloud TPU, GPU Google Cloud, Google Cloud Storage e la rete Jupiter sottostante fornisce in modo coerente tempi di addestramento più rapidi per modelli all'avanguardia su larga scala, grazie alle caratteristiche di scalabilità potente dell'architettura che portano al miglior rapporto prezzo/prestazioni per la pubblicazione di modelli di grandi dimensioni.
Apri software
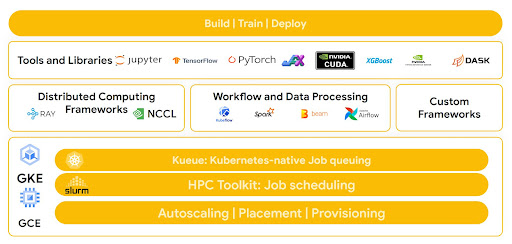
La nostra architettura è ottimizzata per supportare gli strumenti e le librerie più comuni, come Tensorflow, Pytorch e JAX. Inoltre, consente ai clienti di sfruttare tecnologie come le configurazioni Cloud TPU Multislice e Multihost e i servizi gestiti come Google Kubernetes Engine. Ciò consente ai clienti di fornire un deployment pronto all'uso per carichi di lavoro comuni come il framework NVIDIA NeMO orchestrato da SLURM.
Consumo flessibile
I nostri modelli di consumo flessibili consentono ai clienti di scegliere costi fissi con sconti per impegno di utilizzo o modelli on demand dinamici per soddisfare le loro esigenze aziendali.Dynamic Workload Scheduler aiuta i clienti a ottenere la capacità di cui hanno bisogno senza esagerare con l'allocazione, in modo che paghino solo per quello di cui hanno bisogno. Inoltre, gli strumenti di ottimizzazione dei costi di Google Cloud aiutano ad automatizzare l'utilizzo delle risorse per ridurre le attività manuali per i tecnici.
Come funziona
Google è leader nell'intelligenza artificiale con l'invenzione di tecnologie come TensorFlow. Sapevi che puoi sfruttare la tecnologia di Google per i tuoi progetti? Scopri la storia dell'innovazione di Google nell'infrastruttura AI e come puoi sfruttarla per i tuoi carichi di lavoro.
Google è leader nell'intelligenza artificiale con l'invenzione di tecnologie come TensorFlow. Sapevi che puoi sfruttare la tecnologia di Google per i tuoi progetti? Scopri la storia dell'innovazione di Google nell'infrastruttura AI e come puoi sfruttarla per i tuoi carichi di lavoro.
Utilizzi comuni
Esegui addestramento sull'IA su larga scala
Addestramento su IA potente, scalabile ed efficiente
L'addestramento multislice di Cloud TPU è una tecnologia full stack che consente l'addestramento rapido, semplice e affidabile di modelli di IA su larga scala su decine di migliaia di chip TPU.

Character AI sfrutta Google Cloud per fare lo scale up
"Abbiamo bisogno delle GPU per generare risposte ai messaggi degli utenti. Inoltre, man mano che aumentano gli utenti sulla nostra piattaforma, abbiamo bisogno di più GPU per gestirli. Quindi, su Google Cloud possiamo sperimentare per trovare la piattaforma giusta per un particolare carico di lavoro. È fantastico avere la flessibilità necessaria per scegliere le soluzioni più redditizie." Myle Ott, Ingegnere fondatore, Character.AI




Risorse aggiuntive
Addestramento su IA potente, scalabile ed efficiente
L'addestramento multislice di Cloud TPU è una tecnologia full stack che consente l'addestramento rapido, semplice e affidabile di modelli di IA su larga scala su decine di migliaia di chip TPU.
Esempi di clienti
Character AI sfrutta Google Cloud per fare lo scale up
"Abbiamo bisogno delle GPU per generare risposte ai messaggi degli utenti. Inoltre, man mano che aumentano gli utenti sulla nostra piattaforma, abbiamo bisogno di più GPU per gestirli. Quindi, su Google Cloud possiamo sperimentare per trovare la piattaforma giusta per un particolare carico di lavoro. È fantastico avere la flessibilità necessaria per scegliere le soluzioni più redditizie." Myle Ott, Ingegnere fondatore, Character.AI
Pubblica applicazioni basate sull'IA
Sfrutta framework aperti per offrire esperienze basate sull'IA
L'ecosistema software aperto di Google Cloud ti consente di creare applicazioni con gli strumenti e i framework con cui ti trovi meglio, sfruttando al contempo i vantaggi in termini di rapporto prezzo/prestazioni dell'architettura degli AI Hypercomputer.

Priceline: aiutare i viaggiatori a organizzare esperienze uniche
"Lavorare con Google Cloud per incorporare l'AI generativa ci consente di creare un Concierge di viaggio su misura all'interno del nostro chatbot. Vogliamo che i nostri clienti vadano oltre la pianificazione di un viaggio aiutandoli a rendere unica la loro esperienza di viaggio." Martin Brodbeck, CTO, Priceline




Risorse aggiuntive
Sfrutta framework aperti per offrire esperienze basate sull'IA
L'ecosistema software aperto di Google Cloud ti consente di creare applicazioni con gli strumenti e i framework con cui ti trovi meglio, sfruttando al contempo i vantaggi in termini di rapporto prezzo/prestazioni dell'architettura degli AI Hypercomputer.
Esempi di clienti
Priceline: aiutare i viaggiatori a organizzare esperienze uniche
"Lavorare con Google Cloud per incorporare l'AI generativa ci consente di creare un Concierge di viaggio su misura all'interno del nostro chatbot. Vogliamo che i nostri clienti vadano oltre la pianificazione di un viaggio aiutandoli a rendere unica la loro esperienza di viaggio." Martin Brodbeck, CTO, Priceline
Gestisci i modelli in modo economico su larga scala
Massimizzare il rapporto prezzo/prestazioni per gestire l'IA su larga scala
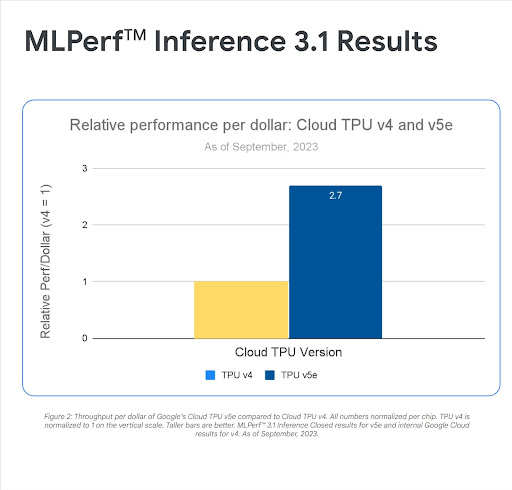
Le istanze VM di Cloud TPU v5e e G2 che forniscono GPU NVIDIA L4 consentono un'inferenza economica ad alte prestazioni e a costi contenuti per un'ampia gamma di carichi di lavoro AI, tra cui i più recenti LLM e modelli di AI generativa. Entrambi offrono significativi miglioramenti per quanto riguarda il rapporto prezzo/prestazioni rispetto ai modelli precedenti e l'architettura degli ipercomputer IA di Google Cloud consente ai clienti di scalare i propri deployment a livelli leader del settore.

Assembly AI sfrutta Google Cloud per l'efficienza dei costi
"I nostri risultati sperimentali dimostrano che Cloud TPU v5e è l'acceleratore più conveniente su cui eseguire l'inferenza su larga scala per il nostro modello. Offre prestazioni per dollaro 2,7 volte superiori rispetto a quelle di G2 e prestazioni per dollaro 4,2 volte superiori rispetto alle istanze A2." Domenic Donato,
VP di tecnologia, AssemblyAI


Risorse aggiuntive
Massimizzare il rapporto prezzo/prestazioni per gestire l'IA su larga scala
Le istanze VM di Cloud TPU v5e e G2 che forniscono GPU NVIDIA L4 consentono un'inferenza economica ad alte prestazioni e a costi contenuti per un'ampia gamma di carichi di lavoro AI, tra cui i più recenti LLM e modelli di AI generativa. Entrambi offrono significativi miglioramenti per quanto riguarda il rapporto prezzo/prestazioni rispetto ai modelli precedenti e l'architettura degli ipercomputer IA di Google Cloud consente ai clienti di scalare i propri deployment a livelli leader del settore.
Esempi di clienti
Assembly AI sfrutta Google Cloud per l'efficienza dei costi
"I nostri risultati sperimentali dimostrano che Cloud TPU v5e è l'acceleratore più conveniente su cui eseguire l'inferenza su larga scala per il nostro modello. Offre prestazioni per dollaro 2,7 volte superiori rispetto a quelle di G2 e prestazioni per dollaro 4,2 volte superiori rispetto alle istanze A2." Domenic Donato,
VP di tecnologia, AssemblyAI











