統合型スーパーコンピューティング アーキテクチャ
AI ハイパーコンピュータ:
AI により最適化されたハードウェア、ソフトウェア、使用量の組み合わせにより、生産性と効率が向上。

概要
パフォーマンスが最適化されたハードウェア
Google Cloud TPU、Google Cloud GPU、Google Cloud Storage、基盤となる Jupiter ネットワークなどのパフォーマンス最適化インフラストラクチャを利用することで、アーキテクチャの優れたスケーリング特性によって最先端の大規模なモデルのトレーニングを一貫して最速で行うことができ、大規模モデルの提供において最良のコスト パフォーマンスを実現できます。
オープン ソフトウェア
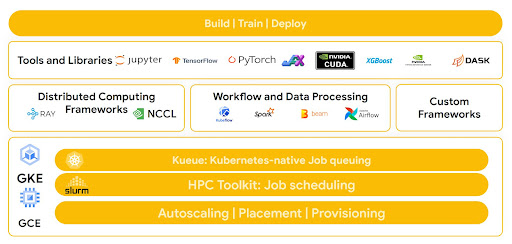
Google のアーキテクチャは、Tensorflow、Pytorch、JAX などの最も一般的なツールやライブラリをサポートするように最適化されています。さらに、Cloud TPU マルチスライスおよびマルチホスト構成などのテクノロジーや、Google Kubernetes Engine などのマネージド サービスも利用できます。これにより、SLURM によってオーケストレートされた NVIDIA NeMO フレームワークのような、一般的なワークロードにターンキー デプロイを実現できます。
柔軟な消費
Google の柔軟な利用モデルにより、お客様は確約利用割引付きの固定費用または動的なオンデマンド モデルを選択して、ビジネスニーズを満たすことができます。Dynamic Workload Scheduler を使用することで、お客様は過剰に割り当てることなく必要な容量だけを確保し、必要な分だけを支払うことができます。さらに、Google Cloud の費用最適化ツールを使用すると、リソースの使用を自動化してエンジニアの手作業を削減できます。
仕組み
Google は、TensorFlow などの技術の発明を使用する AI のリーダーです。ご自身のプロジェクトで Google のテクノロジーを利用できることをご存じですか?AI インフラストラクチャにおける Google のイノベーションの歴史と、それをワークロードに活用する方法を学びます。
Google は、TensorFlow などの技術の発明を使用する AI のリーダーです。ご自身のプロジェクトで Google のテクノロジーを利用できることをご存じですか?AI インフラストラクチャにおける Google のイノベーションの歴史と、それをワークロードに活用する方法を学びます。
一般的な使用例
大規模な AI トレーニングの実行
強力かつスケーラブルで効率的な AI トレーニング
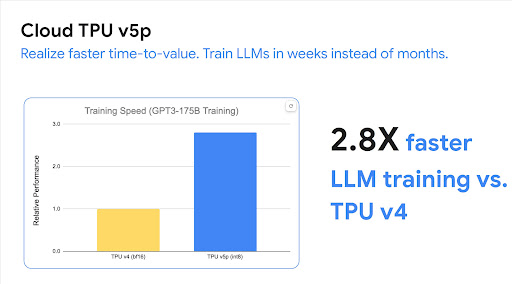
Cloud TPU マルチスライス トレーニングは、数万個の TPU チップで高速かつ容易に信頼性の高い大規模な AI モデルのトレーニングを行えるフルスタック テクノロジーです。

Character AI は Google Cloud を活用してスケールアップを実現
「ユーザーのメッセージに対する回答を生成するには GPU が必要です。また、プラットフォームのユーザー数が増えるにつれ、それに応えるための GPU も増え続けています。そのため、Google Cloud では、特定のワークロードに適したプラットフォームを見つけるためにテストを実施することができます。最も価値のあるソリューションを柔軟に選択できることは素晴らしいことです。」 Character.AI、創設エンジニア、Myle Ott 氏




参考情報
強力かつスケーラブルで効率的な AI トレーニング
Cloud TPU マルチスライス トレーニングは、数万個の TPU チップで高速かつ容易に信頼性の高い大規模な AI モデルのトレーニングを行えるフルスタック テクノロジーです。
お客様の事例
Character AI は Google Cloud を活用してスケールアップを実現
「ユーザーのメッセージに対する回答を生成するには GPU が必要です。また、プラットフォームのユーザー数が増えるにつれ、それに応えるための GPU も増え続けています。そのため、Google Cloud では、特定のワークロードに適したプラットフォームを見つけるためにテストを実施することができます。最も価値のあるソリューションを柔軟に選択できることは素晴らしいことです。」 Character.AI、創設エンジニア、Myle Ott 氏
AI を活用したアプリケーションの提供
オープン フレームワークを活用して AI を活用したエクスペリエンスを提供
Google Cloud のオープン ソフトウェア エコシステムでは、使い慣れたツールとフレームワークでアプリケーションを構築しながら、AI ハイパーコンピュータ アーキテクチャのコスト パフォーマンスのメリットを活用できます。

Priceline: 旅行者がユニークな体験をキュレートできるよう支援
現在は、Google Cloud を使って生成 AI を組み込むことで、chatbot 内に独自の旅行コンシェルジュを作成できます。お客様に旅行の計画という枠を超えていただけるよう、ユニークな旅行体験のキュレートをサポートしています。」Priceline、CTO、Martin Brodbeck 氏




参考情報
オープン フレームワークを活用して AI を活用したエクスペリエンスを提供
Google Cloud のオープン ソフトウェア エコシステムでは、使い慣れたツールとフレームワークでアプリケーションを構築しながら、AI ハイパーコンピュータ アーキテクチャのコスト パフォーマンスのメリットを活用できます。
お客様の事例
Priceline: 旅行者がユニークな体験をキュレートできるよう支援
現在は、Google Cloud を使って生成 AI を組み込むことで、chatbot 内に独自の旅行コンシェルジュを作成できます。お客様に旅行の計画という枠を超えていただけるよう、ユニークな旅行体験のキュレートをサポートしています。」Priceline、CTO、Martin Brodbeck 氏
費用対効果に優れた大規模なモデル サービング
AI を大規模に提供してコスト パフォーマンスを最大化する
NVIDIA L4 GPU を提供する Cloud TPU v5e および G2 VM インスタンスにより、最新の LLM や生成 AI モデルなどの幅広い AI ワークロードに対して、高パフォーマンスで費用対効果の高い推論が可能になります。どちらも、以前のモデルよりもコスト パフォーマンスが大幅に向上します。また、Google Cloud の AI ハイパーコンピュータ アーキテクチャにより、お客様はデプロイを業界をリードするレベルにスケーリングできます。

Assembly AI は Google Cloud を活用して費用対効果を改善
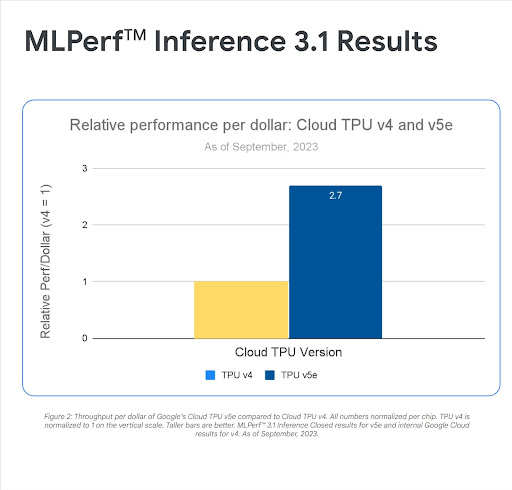
「テストの結果、モデルの大規模な推論を実行する場合に最も費用対効果が高かったアクセラレータは Cloud TPU v5e であることが判明しました。G2 インスタンスに比べて 1 ドルあたり 2.7 倍のパフォーマンスを、A2 インスタンスに比べて 1 ドルあたり 4.2 倍のパフォーマンスを達成しました」Domenic Donato 氏
AssemblyAI、テクノロジー担当バイス プレジデント


参考情報
AI を大規模に提供してコスト パフォーマンスを最大化する
NVIDIA L4 GPU を提供する Cloud TPU v5e および G2 VM インスタンスにより、最新の LLM や生成 AI モデルなどの幅広い AI ワークロードに対して、高パフォーマンスで費用対効果の高い推論が可能になります。どちらも、以前のモデルよりもコスト パフォーマンスが大幅に向上します。また、Google Cloud の AI ハイパーコンピュータ アーキテクチャにより、お客様はデプロイを業界をリードするレベルにスケーリングできます。
お客様の事例
Assembly AI は Google Cloud を活用して費用対効果を改善
「テストの結果、モデルの大規模な推論を実行する場合に最も費用対効果が高かったアクセラレータは Cloud TPU v5e であることが判明しました。G2 インスタンスに比べて 1 ドルあたり 2.7 倍のパフォーマンスを、A2 インスタンスに比べて 1 ドルあたり 4.2 倍のパフォーマンスを達成しました」Domenic Donato 氏
AssemblyAI、テクノロジー担当バイス プレジデント












