Serverless data architecture for trade surveillance at Deutsche Bank
Vladimir Elvov
Lead Customer Engineer, Data & Analytics, Google Cloud
Selim Muhiuddin
Director, Investment Bank Data Architect, Deutsche Bank AG
Ensuring compliance with regulatory requirements is crucial for every bank’s business. While financial regulation is a broad area, detecting and preventing market manipulation and abuse is absolutely mission-critical for an investment bank of Deutsche Bank’s size. This is called trade surveillance.
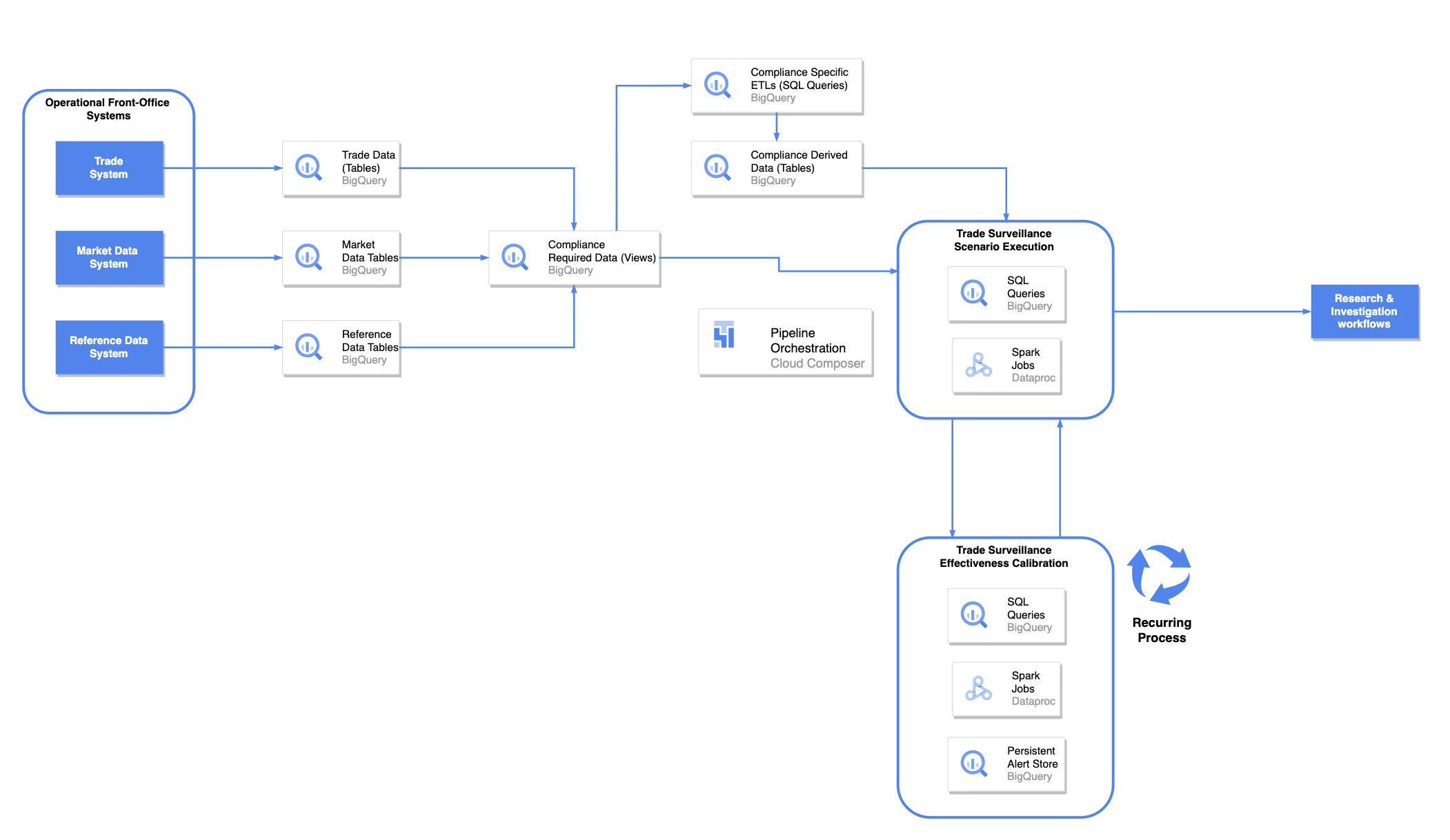
At Deutsche Bank, the Compliance Technology division is responsible for the technical implementation of this control function. To do this, the Compliance Technology team retrieve data from various operational systems in the front office and performs scenario calculations to monitor the trades executed by all of the bank’s business lines. If any suspicious patterns are detected, a compliance officer receives an internal alert to investigate the issue for resolution.
The input data comes from a broad range of systems, but the most relevant are market, trade, and reference data. Historically, provisioning data for compliance technology applications from front-office systems required the team to copy data between, and often even within, many different analytical systems, leading to data quality and lineage issues as well as increased architectural complexity. At the same time, executing trade surveillance scenarios includes processing large volumes of data, which requires a solution that can store and process all the data using distributed compute frameworks like Apache Spark.
A new architectural approach
Google Cloud can help solve the complex issues of processing and sharing data at scale across a large organization with its comprehensive data analytics ecosystem of products and services. BigQuery, Google Cloud’s serverless data warehouse, and Dataproc, a managed service for running Apache Spark workloads, are well positioned to support data-heavy business use cases, such as trade surveillance.
The Compliance Technology team decided to leverage these managed services from Google Cloud in their new architecture for trade surveillance. In the new architecture, the operational front-office systems act as publishers that present their data in BigQuery tables. This includes trade, market and reference data that is now available in BigQuery to various data consumers, including the Trade Surveillance application. As the Compliance Technology team doesn’t need all the data that is published from the front-office systems, they can create multiple views derived from only the input data that includes the required information needed to execute trade surveillance scenarios.
Scenario execution involves running trade surveillance business logic in the form of various different data transformations in BigQuery, Spark in Dataproc, and other applications. This business logic is where suspicious trading patterns, indicating market abuse or market manipulation, can be detected. Suspicious cases are written to output BigQuery tables and then processed through research and investigation workflows, where compliance officers perform investigations, detect potential false positives, or file a Suspicious Activity Report to the regulator if the suspicious case indicates a compliance violation.
Surveillance alerts are also retained and persistently stored to calculate how effective the detection is and improve the rate of how many false positives are actually detected. These calculations are run in Dataproc using Spark and in BigQuery using SQL. They are performed periodically and fed back into the trade surveillance scenario execution to further improve the surveillance mechanisms. Orchestrating the execution of ETL processes to derive data for executing trade surveillance scenarios and effectiveness calibrations is done through Cloud Composer, a managed service for workflow orchestration using Apache Airflow.
Here is a simplified view of what the new architecture looks like:
This is how the Compliance Technology team at Deutsche Bank describes the new architecture:
“This new architecture approach gives us agility and elasticity to roll out new changes and behaviors much faster based on market trends and new emerging risks as e.g. cross product market manipulation is a hot topic our industry is trying to address in line with regulator’s expectations.”
– Asis Mohanty, Global Head, Trade Surveillance, Unauthorized Principal Trading Activity Technology, Deutsche Bank AG
“The serverless BigQuery based architecture enabled Compliance Technology to simplify the sharing of data between the front- and back-office whilst having a zero-data copy approach and aligning with the strategic data architecture.”
– Puspendra Kumar, Domain Architect, Compliance Technology, Deutsche Bank AG
The benefits of a serverless data architecture
As the architecture shows above, trade surveillance requires various input sources of data. A major benefit of leveraging BigQuery for sourcing this data is that there is no need to copy data to make it available for usage by data consumers in Deutsche Bank. A more simplified architecture improves data quality and lowers cost by minimizing the amount of hops the data needs to take.
The main reason for not having to copy data is due to the fact that BigQuery does not have separate instances or clusters. Instead, every table is accessible by a data consumer as long as the consumer app has the right permissions and references the table URI in its queries (i.e., the Google Cloud project-id, the dataset name, and the table name). Thus, various consumers can access the data directly from their own Google Cloud projects without having to copy it and physically persist it there.
For the Compliance Technology team to get the required input data to execute trade surveillance scenarios, they simply need to query the BigQuery views with the input data and the tables containing the derived data from the compliance-specific ETLs. This eliminates the need for copying the data, ensuring the data is more reliable and the architecture is more resilient due to fewer data hops. Above all, this zero-copy approach does enable data consumers in other teams in the bank besides trade surveillance to use market, trade and reference data by following the same pattern in BigQuery.
In addition, BigQuery offers another advantage. It is closely integrated with other Google Cloud services, such as Dataproc and Cloud Composer, so orchestrating ETLs is seamless, leveraging Apache Airflow’s out-of-the-box operators for BigQuery. There is also no need to perform any copying of data to process data from BigQuery using Spark. Instead, an out-of-the-box connector allows data to be read via the BigQuery Storage API, which is optimized for streaming large volumes of data directly to Dataproc workers in parallel ensuring fast processing speed.
Finally, storing data in BigQuery enables data producers to leverage Google Cloud’s native, out-of-the-box tooling for ensuring data quality, such as Dataplex automatic data quality. With this service, it’s possible to configure rules for data freshness, accuracy, uniqueness, completeness, timeliness, and various other dimensions and then simply execute them against the data stored in BigQuery. This happens fully serverless and automated without the need to provision any infrastructure for the rules execution and data quality enforcement. As a result, the Compliance Technology team can ensure that the data they receive from front-office systems complies with the required data quality standards, thus adding to the value of the new architecture.
Given the fact that the new architecture leverages integrated and serverless data analytics products and managed services from Google Cloud, the Compliance Technology team can now fully focus on the business logic of their Trade Surveillance application. BigQuery stands out here because it doesn’t require any maintenance windows, version upgrades, upfront sizing or hardware replacements, as opposed to running a large-scale, on-premises Hadoop cluster.
This brings us to the final advantage, namely the cost-effectiveness of the new architecture. In addition to allowing team members to now focus on business-relevant features instead of dealing with infrastructure, the architecture makes use of services which are charged based on a pay-as-you-go model. Instead of running the underlying machines in 24/7 mode, compute power is only brought up when needed to perform compliance-specific ETLs, execute the trade surveillance scenarios, or perform effectiveness calibration, which are all batch processes. This again helps further reduce the cost compared to an always-on, on-prem solution.
Here’s the view from Deutsche Bank’s Compliance Technology team about the associated benefits:
“Our estimations show that we can potentially save up to 30% in IT Infrastructure cost and achieve better risk coverage and Time to Market when it comes to rolling out additional risk and behaviors with this new serverless architecture using BigQuery.”
- Sanjay-Kumar Tripathi, Managing Director, Global Head of Communication Surveillance Technology & Compliance Cloud Transformation Lead, Deutsche Bank AG

