Optimize Dataproc costs using VM machine type
Susheel Kaushik
Product Manager, Data Analytics
Dataproc is a fast, easy-to-use, fully managed cloud service for running managed open source, such as Apache Spark, Apache Presto, and Apache Hadoop clusters, in a simpler, more cost-efficient way. We hear that enterprises are migrating their big data workloads to the cloud to gain cost advantages with per-second pricing, idle cluster deletion, autoscaling, and more. However, compute, storage, and network costs can add to your overall workload processing costs. Picking the right cloud virtual machine (VM) for compute is a critical piece of the puzzle to make sure you’re using your budget wisely.
Moving these big data clusters to the cloud can bring many cost-efficient benefits. But the choices you make when deploying these clusters on Google Cloud can also add to the savings. As part of the configuration process of Dataproc clusters, you can choose from available Google Cloud VMs. A workload and its execution times are some factors to consider when selecting VM types. Here’s a quick overview of the VMs you can choose from in Google Cloud:
General-purpose machine types (N1) offer the best price-performance ratio for a variety of workloads. If you are not sure which machine type is best for your workload, using a general-purpose machine type is a good place to start.
General-purpose efficient machine types (E2) are ideal for small-to-medium workloads that require at most 16 vCPUs, but do not require local SSDs or GPUs. E2 machine types do not offer sustained-use discounts; however, they do provide consistently low on-demand and committed-use pricing.
Memory-optimized machine types (M2) are ideal for tasks that require intensive use of memory with higher memory-to-vCPU ratios, such as in-memory databases and in-memory analytics, like SAP HANA and business warehousing (BW) workloads, genomics analysis, SQL analysis services, and so on.
Compute-optimized machine types (C2) are ideal for compute-intensive workloads, such as machine learning algorithms, and offer the highest performance per core on Compute Engine.
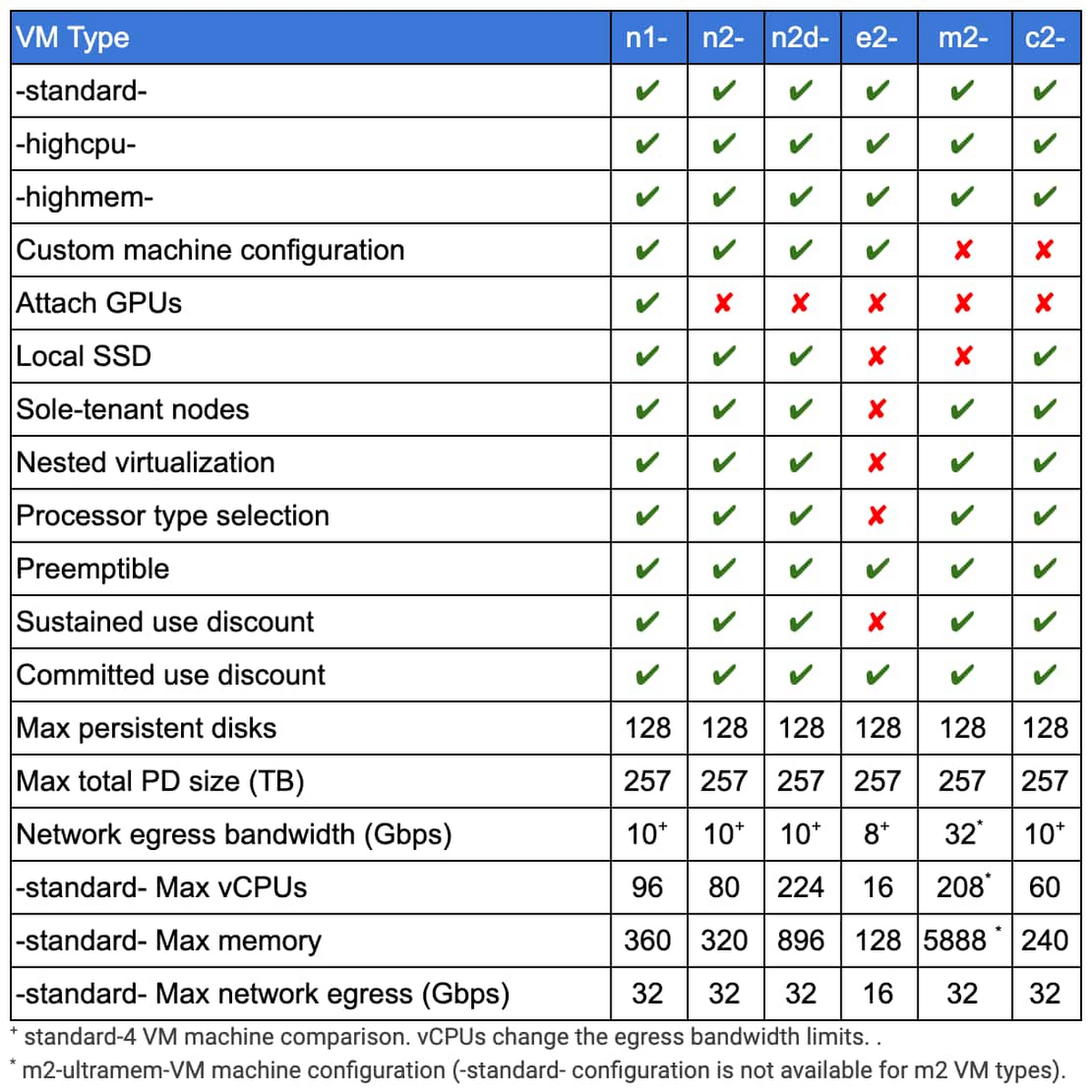
For the right Dataproc workloads, E2 VMs have emerged as a way to continue to bend the cost curve down. E2 VMs have similar processing characteristics and are up to 31% cheaper compared to equivalent N1 VMs, offering the lowest total cost of ownership of any VM in Google Cloud, with reliable and sustained performance along with flexible configurations. Sustained use discounts do not apply to E2 VMs. Also, E2 VMs do not support local SSDs, sole-tenant nodes, nested virtualization, and processor type selection.
Here, this table summarizes the various Dataproc-supported VM types.
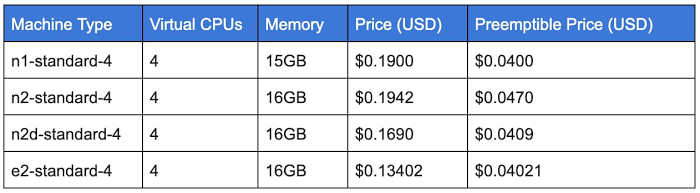
The following table summarizes the costs of various standard-4 configurations available at the time of publishing this article. Check out up-to-date VM pricing information. The e2-standard-4 is about 30% less expensive than the n1-standard-4 configuration.
E2 VMs reduce the compute costs of a Dataproc cluster, thereby reducing the overall TCO. Committed use discounts add to the realized savings. Dataproc TCO savings from using E2 VMs will depend on your workload and cluster usage patterns. Along with VM choice, there are some other ways to make sure you’re keeping your big data costs down.
Tips to optimize cluster costs
There are some commonly used techniques and features you can use to manage cluster operations costs, including:
VM pricing
Committed use discounts: Predictable workloads can benefit from pricing discounts from committed use.
Compute spend
Autoscaling: You can configure Dataproc clusters to scale up and down based on utilization demand.
Job-scoped clusters: A Dataproc cluster can be started in 90 seconds and workflow/job specific clusters can be started for non-SLA critical workloads, thereby minimizing costs to only when the cluster is running.
Preemptible VMs: Non-SLA critical workloads can be run on Preemptible VMs, further increasing the cost savings.
Compute time
Data reorganization: Understanding query access patterns and optimizing the data store for the access pattern will result in faster query times and reduced compute costs.
Aggregates vs. raw data: Intermediate aggregates for frequently accessed data also reduce the amount of data scanned and improve query performance and compute costs.
How to select E2 VMs for Dataproc clusters
Update the master-machine-type and worker-machine-type to the desired E2 VM machine name at cluster creation time to change your Dataproc cluster configuration. Use any of the Dataproc management interfaces: gcloud command, REST API, Google Console and language-specific APIs (go, Java, Node.js, and Python) to select the E2 VM machine type.
Your mileage will vary, but customers using E2 VMs can expect savings as long as the VM limitations are acceptable. We highly recommend verifying the workload on the Dataproc cluster with E2 VMs to better understand the performance and cost characteristics prior to making a change in production.
We are always looking for ways to deliver the highest cost performance for our customers and continue to add features for you to customize and optimize your Dataproc clusters. Check out our Dataproc page to learn more about what’s new with Dataproc.

