ノートブックを使用してモデルをローカルでトレーニングする、パラメータをログに記録する、トレーニング時系列の指標を Vertex AI TensorBoard に記録する、評価指標を記録する、という流れは、データ サイエンティストにとって一般的なワークフローです。
しかし、社内の他の人が作成したデータ前処理コードを再利用できれば、煩雑なデータ ラングリングを省力化し、標準化できます。そのために、次のことを可能にする必要があります。
- Python データ前処理ライブラリを使用して、ノートブックのメモリ内データセット(Pandas Dataframe)をクリーンアップする。
- Keras を使用してモデルをトレーニングする(ノートブックで再度トレーニングする)。
ノートブック: 前処理済みデータを使用したモデルのテスト
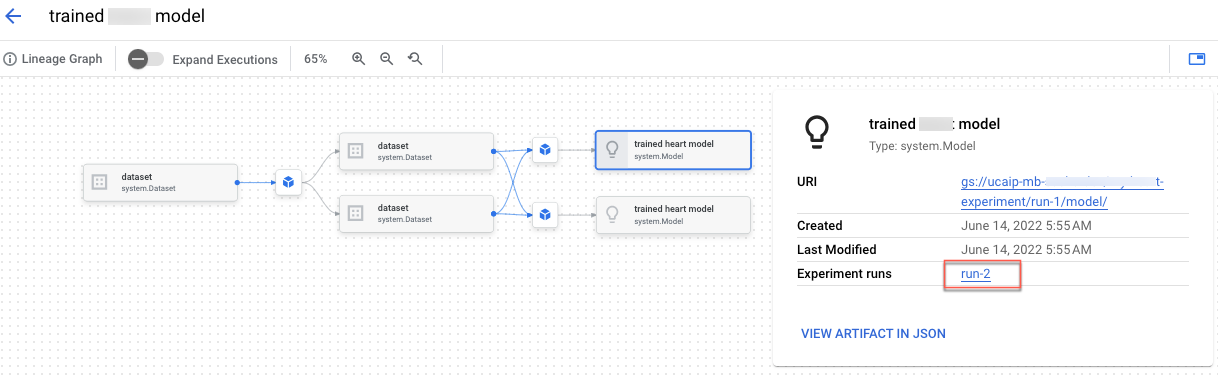
「カスタム トレーニング用の Vertex AI Experiments リネージを作成する」ノートブックでは、Vertex AI Experiments に前処理コードを統合する方法を学習します。また、ML の過程で生成されたメタデータとアーティファクトの記録、分析、デバッグ、監査を行えるテストリネージを構築します。
アーティファクト リネージは、Google Cloud コンソールで確認できます。