When you use a dataset to train an AutoML model, your data is divided into three splits: a training split, a validation split, and a test split. The key goal when creating data splits is to ensure that your test set accurately represents production data. This ensures that the evaluation metrics provide an accurate signal on how the model performs on real world data.
This page describes how Vertex AI uses the training, validation, and test sets of your data to train an AutoML model and the ways you can control how your data is split among these three sets. The data split algorithms for classification and regression are different from the data split algorithms for forecasting.
Data splits for classification and regression
How data splits are used
The data splits are used in the training process as follows:
Model trials
The training set is used to train models with different preprocessing, architecture, and hyperparameter option combinations. These models are evaluated on the validation set for quality, which guides the exploration of additional option combinations. The validation set is also used to select the best checkpoint from periodic evaluation during training. The best parameters and architectures determined in the parallel tuning phase are used to train two ensemble models as described below.
Model evaluation
Vertex AI trains an evaluation model, using the training and validation sets as training data. Vertex AI generates the final model evaluation metrics on this model, using the test set. This is the first time in the process that the test set is used. This approach ensures that the final evaluation metrics are an unbiased reflection of how well the final trained model will perform in production.
Serving model
A model is trained with the training, validation, and test sets, to maximize the amount of training data. This model is the one that you use to request online predictions or batch predictions.
Default data split
By default, Vertex AI uses a random split algorithm to separate your data into the three data splits. Vertex AI randomly selects 80% of your data rows for the training set, 10% for the validation set, and 10% for the test set. We recommend the default split for datasets that are:
- Unchanging over time.
- Relatively balanced.
- Distributed like the data used for predictions in production.
To use the default data split, accept the default in the Google Cloud console, or leave the split field empty for the API.
Options for controlling data splits
You can control what rows are selected for which split using one of the following approaches:
- Random split: Set the split percentages and randomly assign the data rows.
- Manual split: Select specific rows to use for training, validation, and testing in the data split column.
- Chronological split: Split your data by time in the Time column.
You choose only one of these options; you make the choice when you train your model. Some of these options require changes to the training data (for example, the data split column or the time column). Including data for data split options does not require you to use those options; you can still choose another option when you train your model.
The default split is not the best choice if:
You are not training a forecasting model, but your data is time-sensitive.
In this case, you should use a chronological split, or a manual split that results in the most recent data being used as the test set.
Your test data includes data from populations that will not be represented in production.
For example, suppose you are training a model with purchase data from a number of stores. You know, however, that the model will be used primarily to make predictions for stores that are not in the training data. To ensure that the model can generalize to unseen stores, you should segregate your datasets by stores. In other words, your test set should include only stores different from the validation set, and the validation set should include only stores different from the training set.
Your classes are imbalanced.
If you have many more of one class than another in your training data, you might need to manually include more examples of the minority class in your test data. Vertex AI does not perform stratified sampling, so the test set could include too few or even zero examples of the minority class.
Random split
The random split is also known as "mathematical split" or "fraction split".
By default, the percentages of training data used for the training, validation, and test sets are 80, 10, and 10, respectively. If you are using Google Cloud console, you can change the percentages to any values that add up to 100. If you are using the Vertex AI API, you use fractions that add up to 1.0.
To change the percentages (fractions), you use the FractionSplit object to define your fractions.
Rows are selected for a data split randomly, but deterministically. If you are not satisfied with the makeup of your generated data splits, you must use a manual split or change the training data. Training a new model with the same training data results in the same data split.
Manual split
The manual split is also known as "predefined split".
A data split column enables you to select specific rows to be used for training, validation, and testing. When you create your training data, you add a column that can contain one of the following (case sensitive) values:
TRAINVALIDATETESTUNASSIGNED
The values in this column must be one of the two following combinations:
- All of
TRAIN,VALIDATE, andTEST - Only
TESTandUNASSIGNED
Every row must have a value for this column; it cannot be the empty string.
For example, with all sets specified:
"TRAIN","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "TRAIN","Roger","Rogers","123-45-6789" "VALIDATE","Sarah","Smith","333-33-3333"
With only the test set specified:
"UNASSIGNED","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "UNASSIGNED","Roger","Rogers","123-45-6789" "UNASSIGNED","Sarah","Smith","333-33-3333"
The data split column can have any valid column name; its transformation type can be Categorical, Text, or Auto.
If the value of the data split column is UNASSIGNED, Vertex AI
automatically assigns that row to the training or validation set.
Designate a column as a data split column during model training.
Chronological split
The chronological split is also known as "timestamp split".
If your data is time-dependent, you can designate one column as a Time column. Vertex AI uses the Time column to split your data, with the earliest of the rows used for training, the next rows for validation, and the latest rows for testing.
Vertex AI treats each row as an independent and identically distributed training example; setting the Time column does not change this. The Time column is used only to split the dataset.
If you specify a Time column, you must include a value for the Time column for every row in your dataset. Make sure that the Time column has enough distinct values, so that the validation and test sets are non-empty. Usually, having at least 20 distinct values should be sufficient.
The data in the Time column must conform to one of the formats supported by the timestamp transformation. However, the Time column can have any supported transformation, because the transformation only affects how that column is used in training; transformations do not affect data split.
You can also specify the percentages of the training data that get assigned to each set.
Designate a column as a Time column during model training.
Data splits for forecasting
By default, Vertex AI uses a chronological split algorithm to separate your forecasting data into the three data splits. We recommend using the default split. However, if you want to control which training data rows are used for which split, use a manual split.
How data splits are used
The data splits are used in the training process as follows:
Model trials
The training set is used to train models with different preprocessing, architecture, and hyperparameter option combinations. These models are evaluated on the validation set for quality, which guides the exploration of additional option combinations. The validation set is also used to select the best checkpoint from periodic evaluation during training. The best parameters and architectures determined in the parallel tuning phase are used to train two ensemble models as described below.
Model evaluation
Vertex AI trains an evaluation model, using the training and validation sets as training data. Vertex AI generates the final model evaluation metrics on this model, using the test set. This is the first time in the process that the test set is used. This approach ensures that the final evaluation metrics are an unbiased reflection of how well the final trained model will perform in production.
Serving model
A model is trained with the training and validation set. It is validated (to select best checkpoint) using the test set. The test set is never trained on in the sense that the loss is calculated from it. This model is the one that you use to request predictions.
Default split
The default (chronological) data split works as follows:
- The training data is sorted by date.
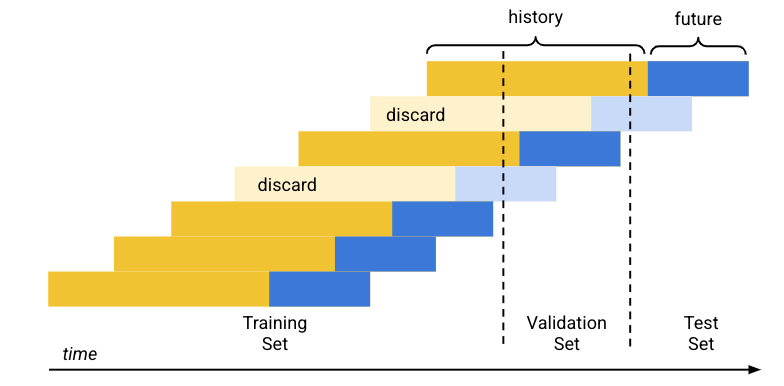
- Using the predetermined set percentages (80/10/10), the time period covered by the training data is separated into three blocks, one for each training set.
- Empty rows are added to the beginning of each time series to enable the model to learn from rows that do not have enough history (context window). The number of added rows is the size of the context window set at training time.
Using the forecast horizon size as set at training time, each row whose future data (forecast horizon) falls fully into one of the datasets is used for that set. (Rows whose forecast horizon straddles two sets are discarded to avoid data leakage.)
Manual split
A data split column enables you to select specific rows to be used for training, validation, and testing. When you create your training data, you add a column that can contain one of the following (case sensitive) values:
TRAINVALIDATETEST
Every row must have a value for this column; it cannot be the empty string.
For example:
"TRAIN","sku_id_1","2020-09-21","10" "TEST","sku_id_1","2020-09-22","23" "TRAIN","sku_id_2","2020-09-22","3" "VALIDATE","sku_id_2","2020-09-23","45"
The data split column can have any valid column name; its transformation type can be Categorical, Text, or Auto.
Designate a column as a data split column during model training.
Make sure you take care to avoid data leakage between your time series.