모델 학습용 특성 데이터를 가져오려면 일괄 제공을 사용하세요. 보관 또는 임시 분석을 위해 특성 값을 내보내야 하는 경우 특성 값을 내보냅니다.
모델 학습을 위한 특성 값 가져오기
모델 학습의 경우 예측 작업의 예시가 포함된 학습 데이터 세트가 필요합니다. 이러한 예시는 해당 특성과 라벨을 포함하는 인스턴스로 구성됩니다. 인스턴스는 예측을 수행할 대상입니다. 예를 들어 인스턴스는 시장 가치를 확인하려는 주택일 수 있습니다. 위치, 나이, 최근 판매된 주변 주택의 평균 가격을 특성으로 합니다. 라벨은 $100,000로 판매된 주택과 같은 예측 작업에 대한 답변입니다.
각 라벨은 특정 시점에 관찰한 것이므로 특정 주택이 판매되었을 때 주변 주택의 가격과 같이 관찰이 이루어진 시점의 해당 특성 값을 가져와야 합니다. 시간이 지나면서 라벨과 특성 값이 수집됨에 따라 해당 특성 값이 변경됩니다. Vertex AI Feature Store(기존)는 특정 시점의 특성 값을 가져올 수 있도록 특정 시점 조회를 수행할 수 있습니다.
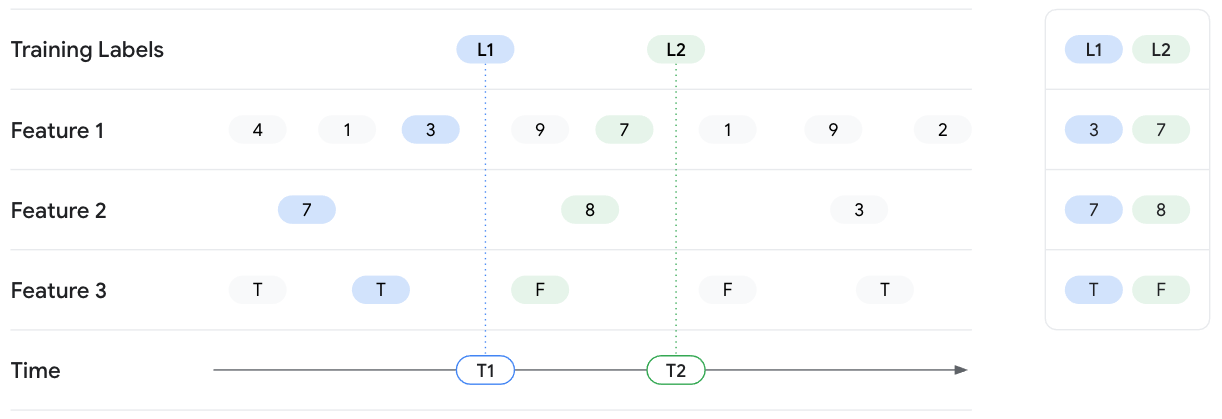
특정 시점 조회 예시
다음 예시에서는 L1 및 L2 라벨이 지정된 2개의 학습 인스턴스에 대한 특성 값을 가져옵니다. 두 라벨은 각각 T1 및 T2에서 관찰됩니다. 이러한 타임스탬프에서 특성 값의 상태를 고정한다고 가정해 보겠습니다. 따라서 T1에서 특정 시점의 조회의 경우 Vertex AI Feature Store(기존)는 Feature 1, Feature 2, Feature 3에 대해 T1 시간까지의 최신 특성을 반환하며 T1 이후의 값은 유출되지 않습니다. 시간이 경과하면 특성 값이 변경되며 라벨도 변경됩니다. 따라서 T2에서 Feature Store는 해당 시점의 다른 특성 값을 반환합니다.
일괄 서빙 입력
일괄 서빙 요청의 일부로 다음 정보가 필요합니다.
- 값을 가져올 기존 특성 목록
- 각 학습 예시에 대한 정보가 포함된 읽기 인스턴스 목록입니다.
특정 시점의 관찰 결과를 나열합니다. CSV 파일 또는 BigQuery 테이블일 수 있습니다. 목록에 다음 정보가 포함되어야 합니다.
- 타임스탬프: 라벨이 관찰되거나 측정된 시간입니다. Vertex AI Feature Store(기존)가 특정 시점 조회를 수행할 수 있으려면 타임스탬프가 필요합니다.
- 항목 ID: 라벨에 해당하는 항목의 한 개 이상의 ID입니다.
- 출력이 기록되는 대상 URI 및 형식. 출력에서 Vertex AI Feature Store(기존)는 본질적으로 읽기 인스턴스 목록의 테이블과 피처스토어의 특성 값을 조인합니다. 다음 형식 및 위치 중 하나를 출력에 지정하세요.
- 리전 또는 멀티 리전 데이터 세트의 BigQuery 테이블.
- 리전 또는 멀티 리전 Cloud Storage 버킷의 CSV 파일. 그러나 특성 값에 배열이 포함된 경우 다른 형식을 선택해야 합니다.
- Cloud Storage 버킷의 Tfrecord 파일
리전 요구사항
읽기 인스턴스와 대상 모두 소스 데이터 세트 또는 버킷은 피처스토어와 동일한 리전 또는 동일한 멀티 리전 위치에 있어야 합니다. 예를 들어 us-central1의 피처스토어는 us-central1 또는 미국 멀티 리전 위치 내에 있는 Cloud Storage 버킷 또는 BigQuery 데이터 세트의 데이터만 읽거나 여기로 데이터를 제공할 수 있습니다. 예를 들어 us-east1에서는 데이터를 사용할 수 없습니다. 또한 이중 리전 버킷을 사용한 데이터 읽기 또는 제공은 지원되지 않습니다.
읽기 인스턴스 목록
읽기 인스턴스 목록은 검색할 특성 값의 항목 및 타임스탬프를 지정합니다. CSV 파일 또는 BigQuery 테이블에는 다음 열이 순서에 관계없이 포함되어야 합니다. 각 열에는 열 헤더가 있어야 합니다.
- 헤더 이름이
timestamp이고 열 값이 RFC 3339 형식의 타임스탬프인 열을 포함해야 합니다. - 하나 이상의 항목 유형 열을 포함해야 하며 여기서 헤더는 항목 유형 ID이고 열 값은 항목 ID입니다.
- 선택사항: 출력에 있는 그대로 전달되는 패스스루 값(추가 열)이 포함될 수 있습니다. 이는 Vertex AI Feature Store(기존)에 없는 데이터가 있지만 출력에 포함하려는 경우에 유용합니다.
예시(CSV)
항목 유형 users 및 movies를 포함하는 피처스토어가 특성이라고 가정합니다. 예를 들어 users 특성에는 age 및 gender가 포함될 수 있으며 movies 특성에는 ratings 및 genre가 포함될 수 있습니다.
이 예시에서는 사용자의 영화 선호도에 대한 학습 데이터를 수집합니다. 사용자가 시청하는 영화 특성과 함께 두 사용자 항목 alice 및 bob의 특성 값을 검색합니다. 개별 데이터 세트로부터 alice가 movie_01을 시청했고 좋아요 표시를 했다는 것을 알았습니다. bob은 movie_02를 시청했지만 좋아요를 표시하지 않았습니다. 따라서 읽기 인스턴스 목록이 다음 예시와 비슷하게 표시될 수 있습니다.
users,movies,timestamp,liked "alice","movie_01",2021-04-15T08:28:14Z,true "bob","movie_02",2021-04-15T08:28:14Z,false
Vertex AI Feature Store(기존)는 지정된 타임스탬프 또는 그 이전에 나열된 항목의 특성 값을 검색합니다. 읽기 인스턴스 목록이 아닌 일괄 제공 요청의 일부로 제공할 특정 기능을 지정합니다.
이 예시에는 또한 liked라는 열이 포함되어 있습니다. 이 열은 사용자가 영화를 마음에 들어 했는지 여부를 표시합니다. 이 열은 피처스토어에 포함되지 않았지만 여전히 이 값을 일괄 처리 출력에 전달할 수 있습니다. 출력에서 이러한 통과 값은 피처스토어의 값과 함께 결합됩니다.
Null 값
지정된 타임스탬프에서 특성 값이 null이면 Vertex AI Feature Store(기존)는 null이 아닌 이전 특성 값을 반환합니다. 이전 값이 없으면 Vertex AI Feature Store(기존)는 null을 반환합니다.
특성 값 제공 처리
읽기 인스턴스 목록 파일에 따라 결정되는 피처스토어의 특성 값을 일괄 처리합니다.
최근 학습 데이터를 읽고 이전 데이터를 제외하여 오프라인 스토리지 사용 비용을 줄이려면 시작 시간을 지정합니다. 시작 시간을 지정하여 오프라인 스토리지 사용 비용을 낮추는 방법을 알아보려면 일괄 제공 및 일괄 내보내기 중에 오프라인 스토리지 비용을 최적화하기 위한 시작 시간 지정을 참조하세요.
웹 UI
다른 메서드를 사용합니다. Google Cloud 콘솔에서는 특성을 일괄 제공할 수 없습니다.
REST
특성 값을 일괄 제공하려면 featurestores.batchReadFeatureValues 메서드를 사용하여 POST 요청을 전송합니다.
다음 샘플은 users 및 movies 항목 유형의 특성 값이 포함된 BigQuery 테이블을 출력합니다. 각 출력 대상에는 요청을 제출하기 전에 몇 가지 기본 요건이 있을 수 있습니다. 예를 들어 bigqueryDestination 필드에 테이블 이름을 지정하려면 기존 데이터 세트가 있어야 합니다. 이러한 요구사항은 API 참조에 설명되어 있습니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- LOCATION_ID: 피처스토어가 생성되는 리전. 예를 들면
us-central1입니다. - PROJECT_ID: 프로젝트 ID
- FEATURESTORE_ID: 피처스토어의 ID
- DATASET_NAME: 대상 BigQuery 데이터 세트의 이름입니다.
- TABLE_NAME: 대상 BigQuery 테이블의 이름입니다.
- STORAGE_LOCATION: 읽기 인스턴스 CSV 파일의 Cloud Storage URI입니다.
HTTP 메서드 및 URL:
POST http://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues
JSON 요청 본문:
{
"destination": {
"bigqueryDestination": {
"outputUri": "bq://PROJECT_ID.DATASET_NAME.TABLE_NAME"
}
},
"csvReadInstances": {
"gcsSource": {
"uris": ["STORAGE_LOCATION"]
}
},
"entityTypeSpecs": [
{
"entityTypeId": "users",
"featureSelector": {
"idMatcher": {
"ids": ["age", "liked_genres"]
}
}
},
{
"entityTypeId": "movies",
"featureSelector": {
"idMatcher": {
"ids": ["title", "average_rating", "genres"]
}
}
}
],
"passThroughFields": [
{
"fieldName": "liked"
}
]
}
요청을 보내려면 다음 옵션 중 하나를 선택합니다.
curl
요청 본문을 request.json 파일에 저장하고 다음 명령어를 실행합니다.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"http://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues"
PowerShell
요청 본문을 request.json 파일에 저장하고 다음 명령어를 실행합니다.
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "http://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues" | Select-Object -Expand Content
다음과 비슷한 출력이 표시됩니다. 응답의 OPERATION_ID를 사용하여 작업 상태를 가져올 수 있습니다.
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/featurestores/FEATURESTORE_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.BatchReadFeatureValuesOperationMetadata",
"genericMetadata": {
"createTime": "2021-03-02T00:03:41.558337Z",
"updateTime": "2021-03-02T00:03:41.558337Z"
}
}
}
Python
Python용 Vertex AI SDK를 설치하거나 업데이트하는 방법은 Python용 Vertex AI SDK 설치를 참조하세요. 자세한 내용은 Python API 참고 문서를 확인하세요.
추가 언어
다음 Vertex AI 클라이언트 라이브러리를 설치하고 사용하여 Vertex AI API를 호출할 수 있습니다. Cloud 클라이언트 라이브러리는 지원되는 각 언어의 고유한 규칙 및 스타일을 사용하여 최적화된 개발자 환경을 제공합니다.
일괄 제공 작업 보기
Google Cloud 콘솔을 사용하여 Google Cloud 프로젝트의 일괄 제공 작업을 봅니다.
웹 UI
- Google Cloud 콘솔의 Vertex AI 섹션에서 특성 페이지로 이동합니다.
- 리전 드롭다운 목록에서 리전을 선택합니다.
- 작업 모음에서 일괄 제공 작업 보기를 클릭하여 모든 피처스토어의 일괄 제공 작업을 나열합니다.
- 사용된 읽기 인스턴스 소스 및 출력 대상 위치와 같은 세부정보를 보려면 일괄 제공 작업의 ID를 클릭합니다.
다음 단계
- 특성 값 일괄 수집 방법 알아보기
- 온라인 서빙을 통해 특성을 제공하는 방법 알아보기
- Vertex AI Feature Store(기존) 동시 일괄 작업 할당량 보기
- 일반적인 Vertex AI Feature Store(기존) 문제 해결