Les prédictions par lot sont des requêtes asynchrones qui demandent des prédictions directement à partir de la ressource de modèle sans avoir à le déployer sur un point de terminaison.
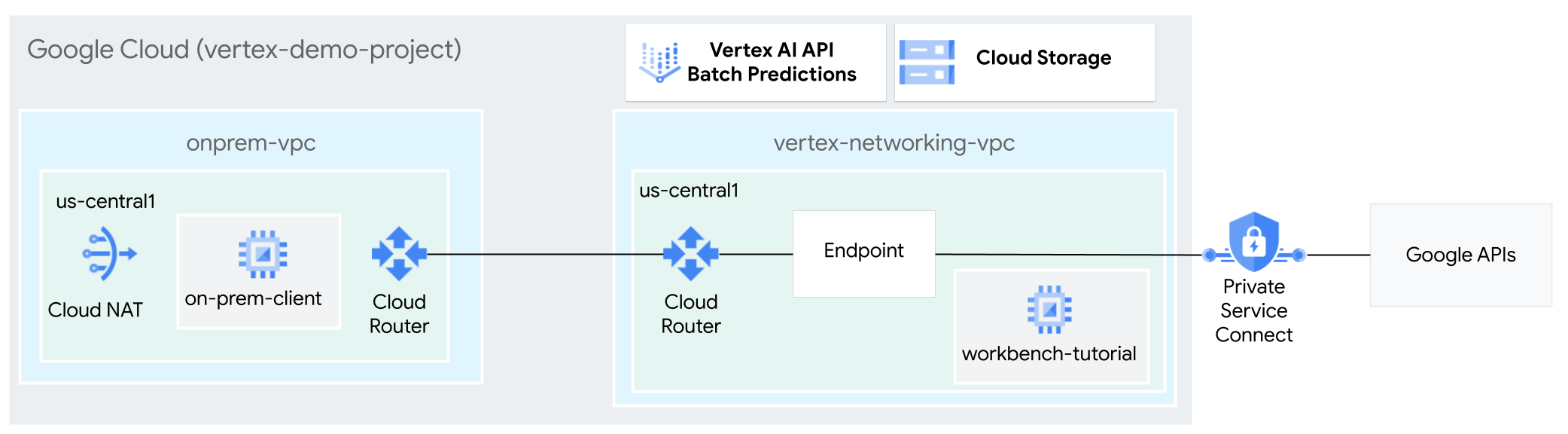
Dans ce tutoriel, vous allez utiliser un VPN haute disponibilité pour envoyer des requêtes de prédiction par lot à un modèle entraîné en mode privé, entre deux réseaux cloud privé virtuel pouvant servir de base pour la connectivité multicloud et privée sur site.
Ce tutoriel est destiné aux administrateurs réseau d'entreprise, aux data scientists et aux chercheurs qui connaissent déjà Vertex AI, le cloud privé virtuel (VPC), la console Google Cloud et Cloud Shell. Une connaissance de Vertex AI Workbench est utile, mais pas obligatoire.
Objectifs
- Créer deux réseaux cloud privés virtuels (VPC), comme illustré dans le schéma précédent :
- L'un (
vertex-networking-vpc) permet d'accéder aux API Google pour la prédiction par lot. - L'autre (
onprem-vpc) représente un réseau sur site.
- L'un (
- Déployer des passerelles VPN haute disponibilité, des tunnels Cloud VPN et des routeurs Cloud Router pour connecter
vertex-networking-vpcetonprem-vpc. - Créer un modèle de prédiction par lot Vertex AI et l'importer dans un bucket Cloud Storage.
- Créer un point de terminaison Private Service Connect (PSC) pour transférer des requêtes privées vers l'API REST de prédiction par lot de Vertex AI.
- Configurer une annonce de routage personnalisée Cloud Router dans
vertex-networking-vpcpour annoncer les routes du point de terminaison Private Service Connect àonprem-vpc. - Créez une instance de VM Compute Engine dans
onprem-vpcpour représenter une application cliente (on-prem-client) qui envoie des requêtes de prédiction par lot en mode privé sur un VPN haute disponibilité.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, vous pouvez éviter de continuer à payer des frais en supprimant les ressources que vous avez créées. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
-
Dans Google Cloud Console, accédez à la page de sélection du projet.
-
Sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
- Ouvrez Cloud Shell pour exécuter les commandes répertoriées dans ce tutoriel. Cloud Shell est un environnement shell interactif pour Google Cloud qui vous permet de gérer vos projets et vos ressources depuis un navigateur Web.
- Dans Cloud Shell, définissez le projet actuel sur votre ID de projet Google Cloud, puis stockez le même ID de projet dans la variable de shell
projectid:projectid="PROJECT_ID" gcloud config set project ${projectid}Remplacez PROJECT_ID par l'ID du projet. Si nécessaire, vous pouvez le trouver dans la console Google Cloud. Pour en savoir plus, consultez la section Trouver votre ID de projet. - Si vous n'êtes pas le propriétaire du projet, demandez à son propriétaire de vous accorder le rôle Administrateur de projet IAM (roles/resourcemanager.projectIamAdmin). Vous devez disposer de ce rôle pour attribuer des rôles IAM à l'étape suivante.
-
Attribuez des rôles à votre compte Google. Exécutez la commande suivante une fois pour chacun des rôles IAM suivants :
roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/iap.tunnelResourceAccessor, roles/notebooks.admin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/serviceusage.serviceUsageAdmin, roles/storage.admin, roles/aiplatform.admin, roles/aiplatform.user, roles/resourcemanager.projectIamAdmingcloud projects add-iam-policy-binding PROJECT_ID --member="user:EMAIL_ADDRESS" --role=ROLE
- en remplaçant
PROJECT_IDpar l'ID de votre projet : - Remplacez
EMAIL_ADDRESSpar votre adresse e-mail. - Remplacez
ROLEpar chaque rôle individuel.
- en remplaçant
-
Activer les API DNS, Artifact Registry, IAM, Compute Engine, Notebooks, et Vertex AI :
gcloud services enable dns.googleapis.com
artifactregistry.googleapis.com iam.googleapis.com compute.googleapis.com notebooks.googleapis.com aiplatform.googleapis.com
Créer les réseaux VPC
Dans cette section, vous allez créer deux réseaux VPC: l'un pour accéder aux API Google pour la prédiction par lot et l'autre pour simuler un réseau sur site. Dans chacun des deux réseaux VPC, vous créez un routeur Cloud Router et une passerelle Cloud NAT. Une passerelle Cloud NAT fournit une connectivité sortante pour les instances de machines virtuelles (VM) Compute Engine sans adresse IP externe.
Créer le réseau VPC
vertex-networking-vpc:gcloud compute networks create vertex-networking-vpc \ --subnet-mode customDans le réseau
vertex-networking-vpc, créez un sous-réseau nomméworkbench-subnet, avec10.0.1.0/28comme plage d'adresses IPv4 principale :gcloud compute networks subnets create workbench-subnet \ --range=10.0.1.0/28 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-accessCréez le réseau VPC pour simuler le réseau sur site (
onprem-vpc) :gcloud compute networks create onprem-vpc \ --subnet-mode customDans le réseau
onprem-vpc, créez un sous-réseau nomméonprem-vpc-subnet1, avec172.16.10.0/29comme plage d'adresses IPv4 principale :gcloud compute networks subnets create onprem-vpc-subnet1 \ --network onprem-vpc \ --range 172.16.10.0/29 \ --region us-central1
Vérifier que les réseaux VPC sont correctement configurés
Dans la console Google Cloud, accédez à l'onglet Réseaux du projet en cours sur la page Réseaux VPC.
Dans la liste des réseaux VPC, vérifiez que les deux réseaux ont été créés :
vertex-networking-vpcetonprem-vpc.Cliquez sur l'onglet Sous-réseaux dans le projet actuel.
Dans la liste des sous-réseaux VPC, vérifiez que les sous-réseaux
workbench-subnetetonprem-vpc-subnet1ont été créés.
Configurer la connectivité hybride
Dans cette section, vous allez créer deux passerelles VPN haute disponibilité connectées l'une à l'autre. L'une réside dans le réseau VPC vertex-networking-vpc. L'autre réside dans le réseau VPC onprem-vpc. Chaque passerelle contient un routeur Cloud Router et une paire de tunnels VPN.
Créer des passerelles VPN haute disponibilité
Dans Cloud Shell, créez la passerelle VPN haute disponibilité pour le réseau VPC
vertex-networking-vpc:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1Créez la passerelle VPN haute disponibilité pour le réseau VPC
onprem-vpc:gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-vpc \ --region us-central1Dans la console Google Cloud, accédez à l'onglet Passerelles Cloud VPN sur la page VPN.
Vérifiez que les deux passerelles (
vertex-networking-vpn-gw1etonprem-vpn-gw1) ont été créées et que chacune dispose de deux adresses IP d'interface.
Créer des routeurs Cloud et des passerelles Cloud NAT
Dans chacun des deux réseaux VPC, vous créez deux routeurs cloud: un routeur général et un routeur régional. Dans chacun des routeurs Cloud Router régionaux, vous créez une passerelle Cloud NAT. Les passerelles Cloud NAT fournissent une connectivité sortante pour les instances de machines virtuelles (VM) Compute Engine sans adresse IP externe.
Dans Cloud Shell, créez un routeur Cloud Router pour le réseau VPC
vertex-networking-vpc:gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1\ --network vertex-networking-vpc \ --asn 65001Créez un routeur Cloud Router pour le réseau VPC
onprem-vpc:gcloud compute routers create onprem-vpc-router1 \ --region us-central1\ --network onprem-vpc\ --asn 65002Créez un routeur Cloud Router régional pour le réseau VPC
vertex-networking-vpc:gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1Configurez une passerelle Cloud NAT sur le routeur Cloud Router régional:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Créez un routeur Cloud Router régional pour le réseau VPC
onprem-vpc:gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-vpc \ --region us-central1Configurez une passerelle Cloud NAT sur le routeur Cloud Router régional:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Dans Google Cloud Console, accédez à la page Routeurs cloud.
Dans la liste des routeurs cloud, vérifiez que les routeurs suivants ont été créés:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-vpc-router1vertex-networking-vpc-router1
Vous devrez peut-être actualiser l'onglet du navigateur de la console Google Cloud pour afficher les nouvelles valeurs.
Dans la liste des routeurs Cloud Router, cliquez sur
cloud-router-us-central1-vertex-nat.Sur la page Détails du routeur, vérifiez que la passerelle Cloud NAT
cloud-nat-us-central1a été créée.Cliquez sur la flèche de retour pour revenir à la page Routeurs cloud.
Dans la liste des routeurs, cliquez sur
cloud-router-us-central1-onprem-nat.Sur la page Détails du routeur, vérifiez que la passerelle Cloud NAT
cloud-nat-us-central1-on-prema été créée.
Créer des tunnels VPN
Dans Cloud Shell, dans le réseau
vertex-networking-vpc, créez un tunnel VPN appelévertex-networking-vpc-tunnel0:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0Dans le réseau
vertex-networking-vpc, créez un tunnel VPN appelévertex-networking-vpc-tunnel1:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1Dans le réseau
onprem-vpc, créez un tunnel VPN appeléonprem-vpc-tunnel0:gcloud compute vpn-tunnels create onprem-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0Dans le réseau
onprem-vpc, créez un tunnel VPN appeléonprem-vpc-tunnel1:gcloud compute vpn-tunnels create onprem-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1Dans Google Cloud Console, accédez à la page VPN.
Dans la liste des tunnels VPN, vérifiez que les quatre tunnels VPN ont été créés.
Établir des sessions BGP
Cloud Router utilise le protocole BGP (Border Gateway Protocol) pour échanger des routes entre votre réseau VPC (dans ce cas, vertex-networking-vpc) et votre réseau sur site (représenté par onprem-vpc). Sur Cloud Router, vous configurez une interface et un pair BGP pour votre routeur sur site.
Ensemble, l'interface et la configuration du pair BGP forment une session BGP.
Dans cette section, vous allez créer deux sessions BGP pour vertex-networking-vpc et deux pour onprem-vpc.
Une fois que vous avez configuré les interfaces et les pairs BGP entre vos routeurs, ils commencent automatiquement à échanger des routes.
Établir des sessions BGP pour vertex-networking-vpc
Dans Cloud Shell, dans le réseau
vertex-networking-vpc, créez une interface BGP pourvertex-networking-vpc-tunnel0:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1Dans le réseau
vertex-networking-vpc, créez un pair BGP pourbgp-onprem-tunnel0:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1Dans le réseau
vertex-networking-vpc, créez une interface BGP pourvertex-networking-vpc-tunnel1:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1Dans le réseau
vertex-networking-vpc, créez un pair BGP pourbgp-onprem-tunnel1:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
Établir des sessions BGP pour onprem-vpc
Dans le réseau
onprem-vpc, créez une interface BGP pouronprem-vpc-tunnel0:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel0 \ --region us-central1Dans le réseau
onprem-vpc, créez un pair BGP pourbgp-vertex-networking-vpc-tunnel0:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1Dans le réseau
onprem-vpc, créez une interface BGP pouronprem-vpc-tunnel1:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel1 \ --region us-central1Dans le réseau
onprem-vpc, créez un pair BGP pourbgp-vertex-networking-vpc-tunnel1:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
Valider la création de la session BGP
Dans Google Cloud Console, accédez à la page VPN.
Dans la liste des tunnels VPN, vérifiez que la valeur du champ État de la session BGP pour chacun des tunnels est passée de Configurer la session BGP à BGP établi. Vous devrez peut-être actualiser l'onglet du navigateur de la console Google Cloud pour afficher les nouvelles valeurs.
Valider les routes apprises vertex-networking-vpc
Dans Google Cloud Console, accédez à la page Réseaux VPC.
Dans la liste des réseaux VPC, cliquez sur
vertex-networking-vpc.Cliquez sur l'onglet Routes.
Sélectionnez us-central1 (Iowa) dans la liste Région, puis cliquez sur Afficher.
Dans la colonne Plage d'adresses IP de destination, vérifiez que la plage d'adresses IP du sous-réseau
onprem-vpc-subnet1(172.16.10.0/29) apparaît deux fois.
Valider les routes apprises onprem-vpc
Cliquez sur la flèche de retour pour revenir à la page Réseaux VPC.
Dans la liste des réseaux VPC, cliquez sur
onprem-vpc.Cliquez sur l'onglet Routes.
Sélectionnez us-central1 (Iowa) dans la liste Région, puis cliquez sur Afficher.
Dans la colonne Plage d'adresses IP de destination, vérifiez que la plage d'adresses IP du sous-réseau
workbench-subnet(10.0.1.0/28) apparaît deux fois.
Créer le point de terminaison client Private Service Connect
Dans Cloud Shell, réservez une adresse IP de point de terminaison client qui servira à accéder aux API Google:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpcCréez une règle de transfert pour connecter le point de terminaison aux API et services Google.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc\ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
Créer des annonces de routage personnalisées pour vertex-networking-vpc
Dans cette section, vous allez créer une annonce de routage personnalisée pour vertex-networking-vpc-router1 (le routeur Cloud Router pour vertex-networking-vpc) afin d'annoncer l'adresse IP du point de terminaison PSC au réseau onprem-vpc.
Dans Google Cloud Console, accédez à la page Routeurs cloud.
Dans la liste des routeurs Cloud Router, cliquez sur
vertex-networking-vpc-router1.Sur la page Détails du routeur, cliquez sur Modifier.
Dans la section Routes annoncées, sélectionnez Créer des routes personnalisées pour le paramètre Routes.
Sélectionnez Diffuser tous les sous-réseaux visibles par Cloud Router pour continuer à annoncer les sous-réseaux disponibles pour le routeur cloud. Cette option imite le comportement de Cloud Router en mode d'annonce par défaut.
Cliquez sur Ajouter une route personnalisée.
Dans Source, sélectionnez Plage d'adresses IP personnalisée.
Dans le champ Plage d'adresses IP, saisissez l'adresse IP suivante :
192.168.0.1Dans le champ Description, saisissez le texte suivant :
Custom route to advertise Private Service Connect endpoint IP addressCliquez sur OK, puis sur Enregistrer.
Vérifier que onprem-vpc a appris les routes annoncées
Dans la console Google Cloud, accédez à la page Routes.
Dans l'onglet Routes effectives, procédez comme suit :
- Pour Réseau, choisissez
onprem-vpc. - Dans le champ Région, choisissez
us-central1 (Iowa). - Cliquez sur Afficher.
Dans la liste des routes, vérifiez qu'il existe des entrées dont le nom commence par
onprem-vpc-router1-bgp-vertex-networking-vpc-tunnel0etonprem-vpc-router1-bgp-vfertex-networking-vpc-tunnel1, et qu'elles utilisent toutes deux192.168.0.1comme Plage d'adresses IP de destination.Si ces entrées n'apparaissent pas immédiatement, attendez quelques minutes, puis actualisez l'onglet de navigateur de la console Google Cloud.
- Pour Réseau, choisissez
Créer une VM dans onprem-vpc qui utilise un compte de service géré par l'utilisateur.
Dans cette section, vous allez créer une instance de VM qui simule une application cliente sur site qui envoie des requêtes de prédiction par lot. En appliquant les bonnes pratiques de Compute Engine et d'IAM, cette VM utilise un compte de service géré par l'utilisateur au lieu du compte de service par défaut de Compute Engine.
Créer un compte de service géré par l'utilisateur
Dans Cloud Shell, exécutez les commandes suivantes, en remplaçant PROJECT_ID par votre ID de projet :
projectid=PROJECT_ID gcloud config set project ${projectid}Créez un compte de service nommé
onprem-user-managed-sa:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa-onprem-client"Attribuez le rôle Utilisateur Vertex AI (
roles/aiplatform.user) au compte de service :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Attribuez le rôle de lecteur des objets de l'espace de stockage (
storage.objectViewer) au compte de service :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectViewer"
Créer l'instance de VM on-prem-client
L'instance de VM que vous créez ne possède pas d'adresse IP externe et n'autorise pas l'accès direct sur Internet. Pour activer l'accès administrateur à la VM, vous utilisez le transfert TCP d'Identity-Aware Proxy (IAP).
Dans Cloud Shell, créez l'instance de VM
on-prem-client:gcloud compute instances create on-prem-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-vpc-subnet1 \ --scopes=http://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Créez une règle de pare-feu pour autoriser IAP à se connecter à votre instance de VM:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Valider l'accès public à l'API Vertex AI
Dans cette section, vous allez utiliser l'utilitaire dig pour effectuer une résolution DNS de l'instance de VM on-prem-client vers l'API Vertex AI (us-central1-aiplatform.googleapis.com). Le résultat dig indique que l'accès par défaut n'utilise que des adresses IP virtuelles publiques pour accéder à l'API Vertex AI.
Dans la section suivante, vous allez configurer un accès privé à l'API Vertex AI.
Dans Cloud Shell, connectez-vous à l'instance de VM
on-prem-clientà l'aide d'IAP:gcloud compute ssh on-prem-client \ --zone=us-central1-a \ --tunnel-through-iapDans l'instance de VM
on-prem-client, exécutez la commandedig:dig us-central1-aiplatform.googleapis.comUn résultat
digsemblable à ce qui suit doit s'afficher, où les adresses IP de la section de réponse sont des adresses IP publiques :; <<>> DiG 9.16.44-Debian <<>> us-central1.aiplatfom.googleapis.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42506 ;; flags: qr rd ra; QUERY: 1, ANSWER: 16, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;us-central1.aiplatfom.googleapis.com. IN A ;; ANSWER SECTION: us-central1.aiplatfom.googleapis.com. 300 IN A 173.194.192.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.152.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.219.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.146.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.147.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.125.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.136.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.148.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.200.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.234.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.171.95 us-central1.aiplatfom.googleapis.com. 300 IN A 108.177.112.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.128.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.6.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.212.95 us-central1.aiplatfom.googleapis.com. 300 IN A 74.125.124.95 ;; Query time: 8 msec ;; SERVER: 169.254.169.254#53(169.254.169.254) ;; WHEN: Wed Sep 27 04:10:16 UTC 2023 ;; MSG SIZE rcvd: 321
Configurer et valider un accès privé à l'API Vertex AI
Dans cette section, vous allez configurer un accès privé à l'API Vertex AI de sorte que lorsque vous envoyez des requêtes de prédiction par lot, elles sont redirigées vers votre point de terminaison PSC. Le point de terminaison PSC transfère à son tour ces requêtes privées à l'API REST de prédiction par lot de Vertex AI.
Mettre à jour le fichier /etc/hosts pour qu'il pointe vers le point de terminaison PSC
Au cours de cette étape, vous allez ajouter une ligne au fichier /etc/hosts qui entraîne la redirection des requêtes envoyées au point de terminaison du service public (us-central1-aiplatform.googleapis.com) vers le point de terminaison PSC (192.168.0.1).
Dans l'instance de VM
on-prem-client, utilisez un éditeur de texte tel quevimounanopour ouvrir le fichier/etc/hosts:sudo vim /etc/hostsAjoutez la ligne suivante au fichier :
192.168.0.1 us-central1-aiplatform.googleapis.comCette ligne attribue l'adresse IP du point de terminaison PSC (
192.168.0.1) au nom de domaine complet de l'API Google Vertex AI (us-central1-aiplatform.googleapis.com).Le fichier modifié doit se présenter comme suit :
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-client.us-central1-a.c.vertex-genai-400103.internal on-prem-client # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleEnregistrez le fichier comme suit :
- Si vous utilisez
vim, appuyez sur la toucheEsc, puis saisissez:wqpour enregistrer le fichier et quitter. - Si vous utilisez
nano, saisissezControl+Oet appuyez surEnterpour enregistrer le fichier, puis saisissezControl+Xpour quitter.
- Si vous utilisez
Pinguez le point de terminaison Vertex AI comme suit :
ping us-central1-aiplatform.googleapis.comLa commande
pingdoit renvoyer le résultat suivant.192.168.0.1correspond à l'adresse IP du point de terminaison PSC :PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.Saisissez
Control+Cpour quitterping.Saisissez
exitpour quitter l'instance de VMon-prem-client.
Créer un compte de service géré par l'utilisateur pour Vertex AI Workbench dans vertex-networking-vpc
Dans cette section, pour contrôler l'accès à votre instance Vertex AI Workbench, vous devez créer un compte de service géré par l'utilisateur, puis lui attribuer des rôles IAM. Lorsque vous créez l'instance, vous spécifiez le compte de service.
Dans Cloud Shell, exécutez les commandes suivantes, en remplaçant PROJECT_ID par votre ID de projet :
projectid=PROJECT_ID gcloud config set project ${projectid}Créez un compte de service nommé
workbench-sa:gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Attribuez le rôle IAM Utilisateur Vertex AI (
roles/aiplatform.user) au compte de service :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Attribuez le rôle IAM Utilisateur BigQuery (
roles/bigquery.user) au compte de service:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/bigquery.user"Attribuez le rôle IAM Administrateur de l'espace de stockage (
roles/storage.admin) au compte de service :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"Attribuez le rôle IAM Lecteur de journaux (
roles/logging.viewer) au compte de service:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.viewer"
Créer l'instance Vertex AI Workbench
Dans Cloud Shell, créez une instance Vertex AI Workbench en spécifiant le compte de service
workbench-sa:gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.comDans la console Google Cloud, accédez à l'onglet Instances sur la page Vertex AI Workbench.
À côté du nom de votre instance Vertex AI Workbench (
workbench-tutorial), cliquez sur Ouvrir JupyterLab.Votre instance Vertex AI Workbench ouvre JupyterLab.
Sélectionnez Fichier > Nouveau > Notebook.
Dans le menu Sélectionner le noyau, sélectionnez Python 3 (local), puis cliquez sur Sélectionner.
Lorsque le nouveau notebook s'ouvre, une cellule de code par défaut vous permet de saisir du code. Elle se présente comme
[ ]:suivi d'un champ de texte. Ce champ de texte est l'emplacement pour coller votre code.Pour installer le SDK Vertex AI pour Python, collez le code suivant dans la cellule, puis cliquez sur Run the selected cells and advance (Exécuter les cellules sélectionnées et continuer) :
!pip3 install --upgrade google-cloud-bigquery scikit-learn==1.2À cette étape et à chacune des étapes suivantes, ajoutez une cellule de code (si nécessaire) en cliquant sur Insert a cell below (Insérer une cellule ci-dessous), collez le code dans la cellule, puis cliquez sur Run the selected cells and advance (Exécuter les cellules sélectionnées et continuer).
Pour utiliser les packages nouvellement installés dans cet environnement d'exécution Jupyter, vous devez redémarrer l'environnement d'exécution :
# Restart kernel after installs so that your environment can access the new packages import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True)Définissez les variables d'environnement suivantes dans votre notebook JupyterLab, en remplaçant PROJECT_ID par l'ID de votre projet.
# set project ID and location PROJECT_ID = "PROJECT_ID" REGION = "us-central1"Créez un bucket Cloud Storage pour la préproduction de la tâche d'entraînement:
BUCKET_NAME = f"{PROJECT_ID}-ml-staging" BUCKET_URI = f"gs://{BUCKET_NAME}" !gsutil mb -l {REGION} -p {PROJECT_ID} {BUCKET_URI}
Préparer les données d'entraînement
Dans cette section, vous allez préparer les données à utiliser pour entraîner un modèle de prédiction.
Dans votre notebook JupyterLab, créez un client BigQuery:
from google.cloud import bigquery bq_client = bigquery.Client(project=PROJECT_ID)Récupérez les données de l'ensemble de données public BigQuery
ml_datasets:DATA_SOURCE = "bigquery-public-data.ml_datasets.census_adult_income" # Define the SQL query to fetch the dataset query = f""" SELECT * FROM `{DATA_SOURCE}` LIMIT 20000 """ # Download the dataset to a dataframe df = bq_client.query(query).to_dataframe() df.head()Utilisez la bibliothèque
sklearnpour répartir les données d'entraînement et de test:from sklearn.model_selection import train_test_split # Split the dataset X_train, X_test = train_test_split(df, test_size=0.3, random_state=43) # Print the shapes of train and test sets print(X_train.shape, X_test.shape)Exportez les dataframes d'entraînement et de test vers des fichiers CSV dans le bucket de préproduction:
X_train.to_csv(f"{BUCKET_URI}/train.csv",index=False, quoting=1, quotechar='"') X_test[[i for i in X_test.columns if i != "income_bracket"]].iloc[:20].to_csv(f"{BUCKET_URI}/test.csv",index=False,quoting=1, quotechar='"')
Préparer l'application d'entraînement
Dans cette section, vous allez créer et compiler l'application d'entraînement Python, puis l'enregistrer dans le bucket de préproduction.
Dans votre notebook JupyterLab, créez un dossier pour les fichiers de l'application d'entraînement:
!mkdir -p training_package/trainerVous devriez maintenant voir un dossier nommé
training_packagedans le menu de navigation de JupyterLab.Définissez les caractéristiques, la cible, le libellé et les étapes de l'entraînement et de l'exportation du modèle vers un fichier:
%%writefile training_package/trainer/task.py from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectKBest from sklearn.pipeline import FeatureUnion, Pipeline from sklearn.preprocessing import LabelBinarizer import pandas as pd import argparse import joblib import os TARGET = "income_bracket" # Define the feature columns that you use from the dataset COLUMNS = ( "age", "workclass", "functional_weight", "education", "education_num", "marital_status", "occupation", "relationship", "race", "sex", "capital_gain", "capital_loss", "hours_per_week", "native_country", ) # Categorical columns are columns that have string values and # need to be turned into a numerical value to be used for training CATEGORICAL_COLUMNS = ( "workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country", ) # load the arguments parser = argparse.ArgumentParser() parser.add_argument('--training-dir', dest='training_dir', default=os.getenv('AIP_MODEL_DIR'), type=str,help='get the staging directory') args = parser.parse_args() # Load the training data X_train = pd.read_csv(os.path.join(args.training_dir,"train.csv")) # Remove the column we are trying to predict ('income-level') from our features list # Convert the Dataframe to a lists of lists train_features = X_train.drop(TARGET, axis=1).to_numpy().tolist() # Create our training labels list, convert the Dataframe to a lists of lists train_labels = X_train[TARGET].to_numpy().tolist() # Since the census data set has categorical features, we need to convert # them to numerical values. We'll use a list of pipelines to convert each # categorical column and then use FeatureUnion to combine them before calling # the RandomForestClassifier. categorical_pipelines = [] # Each categorical column needs to be extracted individually and converted to a numerical value. # To do this, each categorical column will use a pipeline that extracts one feature column via # SelectKBest(k=1) and a LabelBinarizer() to convert the categorical value to a numerical one. # A scores array (created below) will select and extract the feature column. The scores array is # created by iterating over the COLUMNS and checking if it is a CATEGORICAL_COLUMN. for i, col in enumerate(COLUMNS): if col in CATEGORICAL_COLUMNS: # Create a scores array to get the individual categorical column. # Example: # data = [39, 'State-gov', 77516, 'Bachelors', 13, 'Never-married', 'Adm-clerical', # 'Not-in-family', 'White', 'Male', 2174, 0, 40, 'United-States'] # scores = [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] # # Returns: [['Sate-gov']] scores = [] # Build the scores array for j in range(len(COLUMNS)): if i == j: # This column is the categorical column we want to extract. scores.append(1) # Set to 1 to select this column else: # Every other column should be ignored. scores.append(0) skb = SelectKBest(k=1) skb.scores_ = scores # Convert the categorical column to a numerical value lbn = LabelBinarizer() r = skb.transform(train_features) lbn.fit(r) # Create the pipeline to extract the categorical feature categorical_pipelines.append( ( "categorical-{}".format(i), Pipeline([("SKB-{}".format(i), skb), ("LBN-{}".format(i), lbn)]), ) ) # Create pipeline to extract the numerical features skb = SelectKBest(k=6) # From COLUMNS use the features that are numerical skb.scores_ = [1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0] categorical_pipelines.append(("numerical", skb)) # Combine all the features using FeatureUnion preprocess = FeatureUnion(categorical_pipelines) # Create the classifier classifier = RandomForestClassifier() # Transform the features and fit them to the classifier classifier.fit(preprocess.transform(train_features), train_labels) # Create the overall model as a single pipeline pipeline = Pipeline([("union", preprocess), ("classifier", classifier)]) # Save the model pipeline joblib.dump(pipeline, os.path.join(args.training_dir,"model.joblib"))Créez un fichier
__init__.pydans chaque sous-répertoire pour en faire un package :!touch training_package/__init__.py !touch training_package/trainer/__init__.pyCréez un script de configuration de package Python:
%%writefile training_package/setup.py from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for census income classification.' )Exécutez la commande
sdistpour créer la distribution source de l'application d'entraînement:!cd training_package && python setup.py sdist --formats=gztarCopiez le package Python dans le bucket de préproduction:
!gsutil cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/Vérifiez que le bucket de préproduction contient trois fichiers:
!gsutil ls $BUCKET_URIUn résultat semblable aux lignes suivantes doit s'afficher :
gs://$BUCKET_NAME/test.csv gs://$BUCKET_NAME/train.csv gs://$BUCKET_NAME/trainer-0.1.tar.gz
Entraîner le modèle
Dans cette section, vous allez entraîner le modèle en créant et en exécutant une tâche d'entraînement personnalisée.
Dans votre notebook JupyterLab, exécutez la commande suivante pour créer une tâche d'entraînement personnalisée:
!gcloud ai custom-jobs create --display-name=income-classification-training-job \ --project=$PROJECT_ID \ --worker-pool-spec=replica-count=1,machine-type='e2-highmem-2',executor-image-uri='us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest',python-module=trainer.task \ --python-package-uris=$BUCKET_URI/trainer-0.1.tar.gz \ --args="--training-dir","/gcs/$BUCKET_NAME" \ --region=$REGIONLe résultat doit ressembler à ce qui suit. Le premier nombre de chaque chemin de tâche personnalisée correspond au numéro du projet (PROJECT_NUMBER). Le deuxième nombre correspond à l'ID de la tâche personnalisée (CUSTOM_JOB_ID). Notez ces valeurs afin de pouvoir les utiliser à l'étape suivante.
Using endpoint [http://us-central1-aiplatform.googleapis.com/] CustomJob [projects/721032480027/locations/us-central1/customJobs/1100328496195960832] is submitted successfully. Your job is still active. You may view the status of your job with the command $ gcloud ai custom-jobs describe projects/721032480027/locations/us-central1/customJobs/1100328496195960832 or continue streaming the logs with the command $ gcloud ai custom-jobs stream-logs projects/721032480027/locations/us-central1/customJobs/1100328496195960832Exécutez la tâche d'entraînement personnalisée et affichez sa progression en diffusant les journaux de la tâche en cours d'exécution:
!gcloud ai custom-jobs stream-logs projects/PROJECT_NUMBER/locations/us-central1/customJobs/CUSTOM_JOB_IDRemplacez les valeurs suivantes :
- PROJECT_NUMBER: numéro de projet issu de la sortie de la commande précédente.
- CUSTOM_JOB_ID: ID de tâche personnalisée issu du résultat de la commande précédente.
Votre tâche d'entraînement personnalisé est désormais en cours d'exécution. Ce processus devrait prendre environ 10 minutes.
Une fois la tâche terminée, vous pouvez importer le modèle du bucket de préproduction vers Vertex AI Model Registry.
Importer le modèle
Votre tâche d'entraînement personnalisée importe le modèle entraîné dans le bucket de préproduction. Une fois la tâche terminée, vous pouvez importer le modèle du bucket vers Vertex AI Model Registry.
Dans votre notebook JupyterLab, importez le modèle en exécutant la commande suivante:
!gcloud ai models upload --container-image-uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-2:latest" \ --display-name=income-classifier-model \ --artifact-uri=$BUCKET_URI \ --project=$PROJECT_ID \ --region=$REGIONRépertoriez les modèles Vertex AI du projet comme suit:
!gcloud ai models list --region=us-central1Le résultat doit se présenter sous la forme suivante. Si deux modèles ou plus sont répertoriés, le premier de la liste est celui que vous avez importé le plus récemment.
Notez la valeur de la colonne MODEL_ID. Vous en aurez besoin pour créer la requête de prédiction par lot.
Using endpoint [http://us-central1-aiplatform.googleapis.com/] MODEL_ID DISPLAY_NAME 1871528219660779520 income-classifier-modelVous pouvez également répertorier les modèles de votre projet comme suit:
Dans la section Vertex AI de la console Google Cloud, accédez à la page Vertex AI Model Registry.
Accédez à la page Vertex AI Model Registry.
Pour afficher les ID de modèle et d'autres détails, cliquez sur le nom du modèle, puis sur l'onglet Détails de la version.
Obtenir des prédictions par lot à partir du modèle
Vous pouvez maintenant demander des prédictions par lots à partir du modèle. Les requêtes de prédiction par lot sont effectuées à partir de l'instance de VM on-prem-client.
Créer la requête de prédiction par lot
Dans cette étape, vous utilisez ssh pour vous connecter à l'instance de VM on-prem-client.
Dans l'instance de VM, créez un fichier texte nommé request.json contenant la charge utile d'un exemple de requête curl que vous envoyez à votre modèle pour obtenir des prédictions par lot.
Dans Cloud Shell, exécutez les commandes suivantes, en remplaçant PROJECT_ID par votre ID de projet :
projectid=PROJECT_ID gcloud config set project ${projectid}Connectez-vous à l'instance de VM
on-prem-clientà l'aide dessh:gcloud compute ssh on-prem-client \ --project=$projectid \ --zone=us-central1-aDans l'instance de VM
on-prem-client, utilisez un éditeur de texte tel quevimounanopour créer un fichier nommérequest.jsoncontenant le texte suivant:{ "displayName": "income-classification-batch-job", "model": "projects/PROJECT_ID/locations/us-central1/models/MODEL_ID", "inputConfig": { "instancesFormat": "csv", "gcsSource": { "uris": ["BUCKET_URI/test.csv"] } }, "outputConfig": { "predictionsFormat": "jsonl", "gcsDestination": { "outputUriPrefix": "BUCKET_URI" } }, "dedicatedResources": { "machineSpec": { "machineType": "n1-standard-4", "acceleratorCount": "0" }, "startingReplicaCount": 1, "maxReplicaCount": 2 } }Remplacez les valeurs suivantes :
- PROJECT_ID : ID de votre projet.
- MODEL_ID: ID de votre modèle
- BUCKET_URI: URI du bucket de stockage dans lequel vous avez préproduit votre modèle.
Exécutez la commande suivante pour envoyer la requête de prédiction par lot:
curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request.json \ "http://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/batchPredictionJobs"Remplacez PROJECT_ID par l'ID du projet.
La ligne suivante doit s'afficher dans la réponse:
"state": "JOB_STATE_PENDING"Votre tâche de prédiction par lot s'exécute désormais de manière asynchrone. L'exécution prend environ 20 minutes.
Dans la console Google Cloud, dans la section Vertex AI, accédez à la page Prédictions par lot.
Accéder à la page "Prédictions par lot"
Pendant l'exécution de la tâche de prédiction par lot, son état est
Running. Une fois l'opération terminée, son état passe àFinished.Cliquez sur le nom de votre tâche de prédiction par lot (
income-classification-batch-job), puis cliquez sur le lien Emplacement d'exportation de la page d'informations permettant d'afficher les fichiers de sortie de votre tâche par lot dans Cloud Storage.Vous pouvez également cliquer sur l'icône Afficher le résultat de la prédiction sur Cloud Storage (entre la colonne Dernière mise à jour et le menu Actions).
Cliquez sur le lien du fichier
prediction.results-00000-of-00002ouprediction.results-00001-of-00002, puis sur le lien URL authentifiée pour ouvrir le fichier.Le résultat de votre tâche de prédiction par lot doit ressembler à cet exemple:
{"instance": ["27", " Private", "391468", " 11th", "7", " Divorced", " Craft-repair", " Own-child", " White", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["47", " Self-emp-not-inc", "192755", " HS-grad", "9", " Married-civ-spouse", " Machine-op-inspct", " Wife", " White", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Self-emp-not-inc", "84119", " HS-grad", "9", " Married-civ-spouse", " Craft-repair", " Husband", " White", " Male", "0", "0", "45", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "236543", " 12th", "8", " Divorced", " Protective-serv", " Own-child", " White", " Male", "0", "0", "54", " Mexico"], "prediction": " <=50K"} {"instance": ["60", " Private", "160625", " HS-grad", "9", " Married-civ-spouse", " Prof-specialty", " Husband", " White", " Male", "5013", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["34", " Local-gov", "22641", " HS-grad", "9", " Never-married", " Protective-serv", " Not-in-family", " Amer-Indian-Eskimo", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "178623", " HS-grad", "9", " Never-married", " Other-service", " Not-in-family", " Black", " Female", "0", "0", "40", " ?"], "prediction": " <=50K"} {"instance": ["28", " Private", "54243", " HS-grad", "9", " Divorced", " Transport-moving", " Not-in-family", " White", " Male", "0", "0", "60", " United-States"], "prediction": " <=50K"} {"instance": ["29", " Local-gov", "214385", " 11th", "7", " Divorced", " Other-service", " Unmarried", " Black", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["49", " Self-emp-inc", "213140", " HS-grad", "9", " Married-civ-spouse", " Exec-managerial", " Husband", " White", " Male", "0", "1902", "60", " United-States"], "prediction": " >50K"}
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez chaque ressource individuellement.
Vous pouvez supprimer les ressources individuelles dans la console Google Cloud comme suit:
Supprimez la tâche de prédiction par lot comme suit:
Dans la console Google Cloud, dans la section Vertex AI, accédez à la page Prédictions par lot.
À côté du nom de votre tâche de prédiction par lot (
income-classification-batch-job), cliquez sur le menu Actions, puis sélectionnez Supprimer la tâche de prédiction par lot.)
Supprimez le modèle comme suit :
Dans la section Vertex AI de la console Google Cloud, accédez à la page Model Registry.
À côté du nom de votre modèle (
income-classifier-model), cliquez sur le menu Actions, puis sélectionnez Supprimer le modèle.
Supprimez l'instance Vertex AI Workbench comme suit:
Dans la console Google Cloud, dans la section Vertex AI, accédez à l'onglet Instances de la page Workbench.
Sélectionnez l'instance Vertex AI Workbench
workbench-tutorial, puis cliquez sur Supprimer.
Supprimez l'instance de VM Compute Engine comme suit:
Dans la console Google Cloud, accédez à la page Compute Engine.
Sélectionnez l'instance de VM
on-prem-client, puis cliquez sur Supprimer.
Supprimez les tunnels VPN comme suit:
Dans Google Cloud Console, accédez à la page VPN.
Sur la page VPN, cliquez sur l'onglet Tunnels Cloud VPN.
Dans la liste des tunnels VPN, sélectionnez les quatre tunnels VPN que vous avez créés dans ce tutoriel, puis cliquez sur Supprimer.
Supprimez les passerelles VPN haute disponibilité comme suit:
Sur la page VPN, cliquez sur l'onglet Passerelles Cloud VPN.
Dans la liste des passerelles VPN, cliquez sur
onprem-vpn-gw1.Sur la page Informations sur la passerelle Cloud VPN, cliquez sur Supprimer la passerelle VPN.
Si nécessaire, cliquez sur la flèche de retour pour revenir à la liste des passerelles VPN, puis cliquez sur
vertex-networking-vpn-gw1.Sur la page Informations sur la passerelle Cloud VPN, cliquez sur Supprimer la passerelle VPN.
Supprimez les routeurs cloud comme suit:
Accédez à la page Routeurs cloud.
Dans la liste des routeurs cloud, sélectionnez les quatre routeurs que vous avez créés dans ce tutoriel.
Pour supprimer les routeurs, cliquez sur Supprimer.
Cela supprimera également les deux passerelles Cloud NAT connectées aux routeurs Cloud.
Supprimez la règle de transfert
pscvertexpour le réseau VPCvertex-networking-vpccomme suit:Accédez à l'onglet Interfaces de la page Équilibrage de charge.
Dans la liste des règles de transfert, cliquez sur
pscvertex.Sur la page Détails de la règle de transfert, cliquez sur Supprimer.
Supprimez les réseaux VPC comme suit:
Accédez à la page des réseaux VPC.
Dans la liste des réseaux VPC, cliquez sur
onprem-vpc.Sur la page Détails du réseau VPC, cliquez sur Supprimer le réseau VPC.
Lorsque vous supprimez un réseau, ses sous-réseaux, ses routes et ses règles de pare-feu sont également supprimés.
Dans la liste des réseaux VPC, cliquez sur
vertex-networking-vpc.Sur la page Détails du réseau VPC, cliquez sur Supprimer le réseau VPC.
Supprimez le bucket de stockage comme suit :
Dans la console Google Cloud, accédez à la page Cloud Storage.
Sélectionnez votre bucket de stockage, puis cliquez sur Supprimer.
Supprimez les comptes de service
workbench-saetonprem-user-managed-sacomme suit:Accédez à la page Comptes de service.
Sélectionnez les comptes de service
onprem-user-managed-saetworkbench-sa, puis cliquez sur Supprimer.
Étapes suivantes
- Découvrez les options de mise en réseau d'entreprise pour accéder aux points de terminaison et aux services Vertex AI.
- Découvrez comment fonctionne Private Service Connect et ses avantages significatifs en termes de performances.
- Découvrez comment utiliser VPC Service Controls pour créer des périmètres sécurisés afin d'autoriser ou de refuser l'accès à Vertex AI et à d'autres API Google sur votre point de terminaison de prédiction en ligne.
- Découvrez comment et pourquoi utiliser une zone de transfert DNS plutôt que de modifier le fichier
/etc/hostsdans des environnements de production à grande échelle.