Dokumen ini akan menuntun Anda menjalankan langkah-langkah yang diperlukan untuk membangun pipeline yang otomatis melatih model kustom setiap kali data baru disisipkan ke dalam set data menggunakan Vertex AI Pipelines dan Cloud Functions.
Tujuan
Langkah-langkah berikut mencakup proses ini:
Mendapatkan dan menyiapkan set data di BigQuery.
Membuat dan mengupload paket pelatihan kustom. Ketika dieksekusi, model ini akan membaca data dari set data dan melatih model.
Membangun Pipeline Vertex AI. Pipeline ini mengeksekusi paket pelatihan kustom, mengupload model ke Vertex AI Model Registry, menjalankan tugas evaluasi, dan mengirim notifikasi email.
Menjalankan pipeline secara manual.
Buat Cloud Function dengan pemicu Eventarc yang menjalankan pipeline setiap kali data baru dimasukkan ke dalam set data BigQuery.
Sebelum Memulai
Siapkan project dan notebook Anda.
Penyiapan project
-
Di konsol Google Cloud, buka halaman Pemilih project.
-
Pilih atau buat project Google Cloud.
-
Pastikan penagihan telah diaktifkan untuk project Google Cloud Anda.
Buat notebook
Kita menggunakan notebook Colab Enterprise untuk mengeksekusi beberapa kode dalam tutorial ini.
Jika Anda bukan pemilik project, minta pemilik project untuk memberi Anda peran IAM
roles/resourcemanager.projectIamAdmindanroles/aiplatform.colabEnterpriseUser.Anda harus memiliki peran ini agar dapat menggunakan Colab Enterprise dan memberikan peran serta izin IAM ke Anda sendiri dan akun layanan.
Di konsol Google Cloud, buka halaman Colab Enterprise Notebooks.
Colab Enterprise akan meminta Anda mengaktifkan API yang diperlukan berikut jika belum diaktifkan.
- Vertex AI API
- API Dataform
- Compute Engine API
Pada menu Region, pilih region tempat Anda ingin membuat notebook. Jika tidak yakin, gunakan us-central1 sebagai regionnya.
Gunakan region yang sama untuk semua resource dalam tutorial ini.
Klik Create a new notebook.
Notebook baru Anda akan muncul di tab Notebook saya. Untuk menjalankan kode di notebook, tambahkan sel kode dan klik tombol Run cell.
Menyiapkan lingkungan pengembangan
Di notebook Anda, instal paket Python3 berikut.
! pip3 install google-cloud-aiplatform==1.34.0 \ google-cloud-pipeline-components==2.6.0 \ kfp==2.4.0 \ scikit-learn==1.0.2 \ mlflow==2.10.0Tetapkan project Google Cloud CLI dengan menjalankan perintah berikut:
PROJECT_ID = "PROJECT_ID" # Set the project id ! gcloud config set project {PROJECT_ID}Ganti PROJECT_ID dengan project ID Anda. Jika perlu, Anda dapat menemukan project ID di Google Cloud Console.
Memberikan peran ke Akun Google Anda:
! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/bigquery.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.user ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/storage.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/pubsub.editor ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/cloudfunctions.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.viewer ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.configWriter ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/iam.serviceAccountUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/eventarc.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.colabEnterpriseUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/artifactregistry.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/serviceusage.serviceUsageAdminMengaktifkan API berikut
- Artifact Registry API
- BigQuery API
- Cloud Build API
- Cloud Functions API
- Cloud Logging API
- Pub/Sub API
- Cloud Run Admin API
- Cloud Storage API
- API Eventarc
- Service Usage API
- Vertex AI API
! gcloud services enable artifactregistry.googleapis.com bigquery.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com logging.googleapis.com pubsub.googleapis.com run.googleapis.com storage-component.googleapis.com eventarc.googleapis.com serviceusage.googleapis.com aiplatform.googleapis.comBerikan peran ke akun layanan project Anda:
Melihat nama akun layanan
! gcloud iam service-accounts listCatat nama agen layanan Compute Anda. Nama tersebut harus dalam format
[email protected].Memberikan peran yang diperlukan ke agen layanan.
! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID[email protected]"" --role=roles/aiplatform.serviceAgent ! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID[email protected]"" --role=roles/eventarc.eventReceiver
Mendapatkan dan menyiapkan {i>dataset<i}
Dalam tutorial ini, Anda akan membuat model yang memprediksi tarif naik taksi berdasarkan fitur seperti waktu perjalanan, lokasi, dan jarak. Kita akan menggunakan data dari set data Perjalanan Taksi Chicago publik. Set data ini mencakup perjalanan taksi dari tahun 2013 hingga saat ini, yang dilaporkan ke Kota Chicago dalam perannya sebagai badan pengatur. Untuk melindungi privasi pengemudi dan pengguna kab secara bersamaan dan memungkinkan agregator untuk menganalisis data, ID Taksi dijaga agar tetap konsisten untuk setiap nomor medali taksi yang diberikan, tetapi tidak menampilkan angka, dalam beberapa kasus, Jalur Sensus ditekan, dan waktu dibulatkan ke terdekat 15 menit.
Untuk informasi selengkapnya, lihat Perjalanan Taksi Chicago di Marketplace.
Membuat set data BigQuery
Di konsol Google Cloud, buka BigQuery Studio.
Di panel Explorer, cari project Anda, klik Actions, lalu klik Create dataset.
Di halaman Create dataset:
Untuk Dataset ID, masukkan
mlops. Untuk mengetahui informasi selengkapnya, lihat penamaan set data.Untuk Jenis lokasi, pilih multi-region. Misalnya, pilih US (beberapa region di Amerika Serikat) jika Anda menggunakan
us-central1. Setelah set data dibuat, lokasi tidak dapat diubah.Klik Create dataset.
Untuk mengetahui informasi selengkapnya, lihat cara membuat set data.
Membuat dan mengisi tabel BigQuery
Di bagian ini, Anda akan membuat tabel dan mengimpor data selama satu tahun dari set data publik ke set data project Anda.
Buka BigQuery Studio
Klik Create SQL Query dan jalankan kueri SQL berikut dengan mengklik Run.
CREATE OR REPLACE TABLE `PROJECT_ID.mlops.chicago` AS ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2019 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )Kueri ini membuat tabel
<PROJECT_ID>.mlops.chicagodan mengisinya dengan data dari tabelbigquery-public-data.chicago_taxi_trips.taxi_tripspublik.Untuk melihat skema tabel, klik Go to table, lalu klik tab Schema.
Untuk melihat isi tabel, klik tab Preview.
Membuat dan mengupload paket pelatihan kustom
Di bagian ini, Anda akan membuat paket Python yang berisi kode yang membaca set data, membagi data menjadi set pelatihan dan pengujian, serta melatih model kustom. Paket ini akan dijalankan sebagai salah satu tugas di pipeline Anda. Untuk mengetahui informasi selengkapnya, lihat mem-build aplikasi pelatihan Python untuk container bawaan.
Membuat paket pelatihan kustom
Di notebook Colab, buat folder induk untuk aplikasi pelatihan:
!mkdir -p training_package/trainerBuat file
__init__.pydi setiap folder untuk menjadikannya sebuah paket menggunakan perintah berikut:! touch training_package/__init__.py ! touch training_package/trainer/__init__.pyAnda dapat melihat file dan folder baru di panel folder File.
Di panel Files, buat file bernama
task.pydi folder training_package/trainer dengan konten berikut.# Import the libraries from sklearn.model_selection import train_test_split, cross_val_score from sklearn.preprocessing import OneHotEncoder, StandardScaler from google.cloud import bigquery, bigquery_storage from sklearn.ensemble import RandomForestRegressor from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline from google import auth from scipy import stats import numpy as np import argparse import joblib import pickle import csv import os # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--project-id', dest='project_id', type=str, help='Project ID.') parser.add_argument('--training-dir', dest='training_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the data and the trained model.') parser.add_argument('--bq-source', dest='bq_source', type=str, help='BigQuery data source for training data.') args = parser.parse_args() # data preparation code BQ_QUERY = """ with tmp_table as ( SELECT trip_seconds, trip_miles, fare, tolls, company, pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude, DATETIME(trip_start_timestamp, 'America/Chicago') trip_start_timestamp, DATETIME(trip_end_timestamp, 'America/Chicago') trip_end_timestamp, CASE WHEN (pickup_community_area IN (56, 64, 76)) OR (dropoff_community_area IN (56, 64, 76)) THEN 1 else 0 END is_airport, FROM `{}` WHERE dropoff_latitude IS NOT NULL and dropoff_longitude IS NOT NULL and pickup_latitude IS NOT NULL and pickup_longitude IS NOT NULL and fare > 0 and trip_miles > 0 and MOD(ABS(FARM_FINGERPRINT(unique_key)), 100) between 0 and 99 ORDER BY RAND() LIMIT 10000) SELECT *, EXTRACT(YEAR FROM trip_start_timestamp) trip_start_year, EXTRACT(MONTH FROM trip_start_timestamp) trip_start_month, EXTRACT(DAY FROM trip_start_timestamp) trip_start_day, EXTRACT(HOUR FROM trip_start_timestamp) trip_start_hour, FORMAT_DATE('%a', DATE(trip_start_timestamp)) trip_start_day_of_week FROM tmp_table """.format(args.bq_source) # Get default credentials credentials, project = auth.default() bqclient = bigquery.Client(credentials=credentials, project=args.project_id) bqstorageclient = bigquery_storage.BigQueryReadClient(credentials=credentials) df = ( bqclient.query(BQ_QUERY) .result() .to_dataframe(bqstorage_client=bqstorageclient) ) # Add 'N/A' for missing 'Company' df.fillna(value={'company':'N/A','tolls':0}, inplace=True) # Drop rows containing null data. df.dropna(how='any', axis='rows', inplace=True) # Pickup and dropoff locations distance df['abs_distance'] = (np.hypot(df['dropoff_latitude']-df['pickup_latitude'], df['dropoff_longitude']-df['pickup_longitude']))*100 # Remove extremes, outliers possible_outliers_cols = ['trip_seconds', 'trip_miles', 'fare', 'abs_distance'] df=df[(np.abs(stats.zscore(df[possible_outliers_cols].astype(float))) < 3).all(axis=1)].copy() # Reduce location accuracy df=df.round({'pickup_latitude': 3, 'pickup_longitude': 3, 'dropoff_latitude':3, 'dropoff_longitude':3}) # Drop the timestamp col X=df.drop(['trip_start_timestamp', 'trip_end_timestamp'],axis=1) # Split the data into train and test X_train, X_test = train_test_split(X, test_size=0.10, random_state=123) ## Format the data for batch predictions # select string cols string_cols = X_test.select_dtypes(include='object').columns # Add quotes around string fields X_test[string_cols] = X_test[string_cols].apply(lambda x: '\"' + x + '\"') # Add quotes around column names X_test.columns = ['\"' + col + '\"' for col in X_test.columns] # Save DataFrame to csv X_test.to_csv(os.path.join(args.training_dir,"test.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Save test data without the target for batch predictions X_test.drop('\"fare\"',axis=1,inplace=True) X_test.to_csv(os.path.join(args.training_dir,"test_no_target.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Separate the target column y_train=X_train.pop('fare') # Get the column indexes col_index_dict = {col: idx for idx, col in enumerate(X_train.columns)} # Create a column transformer pipeline ct_pipe = ColumnTransformer(transformers=[ ('hourly_cat', OneHotEncoder(categories=[range(0,24)], sparse = False), [col_index_dict['trip_start_hour']]), ('dow', OneHotEncoder(categories=[['Mon', 'Tue', 'Sun', 'Wed', 'Sat', 'Fri', 'Thu']], sparse = False), [col_index_dict['trip_start_day_of_week']]), ('std_scaler', StandardScaler(), [ col_index_dict['trip_start_year'], col_index_dict['abs_distance'], col_index_dict['pickup_longitude'], col_index_dict['pickup_latitude'], col_index_dict['dropoff_longitude'], col_index_dict['dropoff_latitude'], col_index_dict['trip_miles'], col_index_dict['trip_seconds']]) ]) # Add the random-forest estimator to the pipeline rfr_pipe = Pipeline([ ('ct', ct_pipe), ('forest_reg', RandomForestRegressor( n_estimators = 20, max_features = 1.0, n_jobs = -1, random_state = 3, max_depth=None, max_leaf_nodes=None, )) ]) # train the model rfr_score = cross_val_score(rfr_pipe, X_train, y_train, scoring = 'neg_mean_squared_error', cv = 5) rfr_rmse = np.sqrt(-rfr_score) print ("Crossvalidation RMSE:",rfr_rmse.mean()) final_model=rfr_pipe.fit(X_train, y_train) # Save the model pipeline with open(os.path.join(args.training_dir,"model.pkl"), 'wb') as model_file: pickle.dump(final_model, model_file)Kode ini menyelesaikan tugas-tugas berikut:
- Pilihan fitur.
- Mengubah waktu data penjemputan dan pengantaran dari UTC ke waktu lokal Chicago.
- Mengekstrak tanggal, jam, hari, bulan, dan tahun dari tanggal pengambilan.
- Menghitung durasi perjalanan menggunakan waktu mulai dan berakhir.
- Mengidentifikasi dan menandai perjalanan yang dimulai atau berakhir di bandara berdasarkan area komunitas.
- Model regresi Random Forest dilatih untuk memprediksi tarif perjalanan taksi menggunakan framework scikit-learn.
Model yang dilatih disimpan ke dalam file acar
model.pkl.Pendekatan dan rekayasa fitur yang dipilih didasarkan pada eksplorasi dan analisis data tentang Memprediksi Tarif Taksi Chicago.
Di panel Files, buat file bernama
setup.pydi folder training_package dengan konten berikut.from setuptools import find_packages from setuptools import setup REQUIRED_PACKAGES=["google-cloud-bigquery[pandas]","google-cloud-bigquery-storage"] setup( name='trainer', version='0.1', install_requires=REQUIRED_PACKAGES, packages=find_packages(), include_package_data=True, description='Training application package for chicago taxi trip fare prediction.' )Di notebook, jalankan
setup.pyuntuk membuat distribusi sumber untuk aplikasi pelatihan Anda:! cd training_package && python setup.py sdist --formats=gztar && cd ..
Di akhir bagian ini, panel Files akan berisi file dan folder berikut di training-package.
dist
trainer-0.1.tar.gz
trainer
__init__.py
task.py
trainer.egg-info
__init__.py
setup.py
Mengupload paket pelatihan kustom ke Cloud Storage
Membuat bucket Cloud Storage.
REGION="REGION" BUCKET_NAME = "BUCKET_NAME" BUCKET_URI = f"gs://{BUCKET_NAME}" ! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URIGanti nilai parameter berikut:
REGION: Pilih region yang sama dengan yang Anda pilih saat membuat notebook colab.BUCKET_NAME: Nama bucket.
Upload paket pelatihan Anda ke bucket Cloud Storage.
# Copy the training package to the bucket ! gsutil cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/
Membangun pipeline Anda
Pipeline adalah deskripsi alur kerja MLOps sebagai grafik langkah-langkah yang disebut tugas pipeline.
Di bagian ini, Anda akan menentukan tugas pipeline, mengompilasinya ke YAML, dan mendaftarkan pipeline di Artifact Registry agar dapat dikontrol versi dan dijalankan beberapa kali, oleh satu pengguna atau oleh beberapa pengguna.
Berikut adalah visualisasi tugas, termasuk pelatihan model, upload model, evaluasi model, dan notifikasi email, dalam pipeline kami:
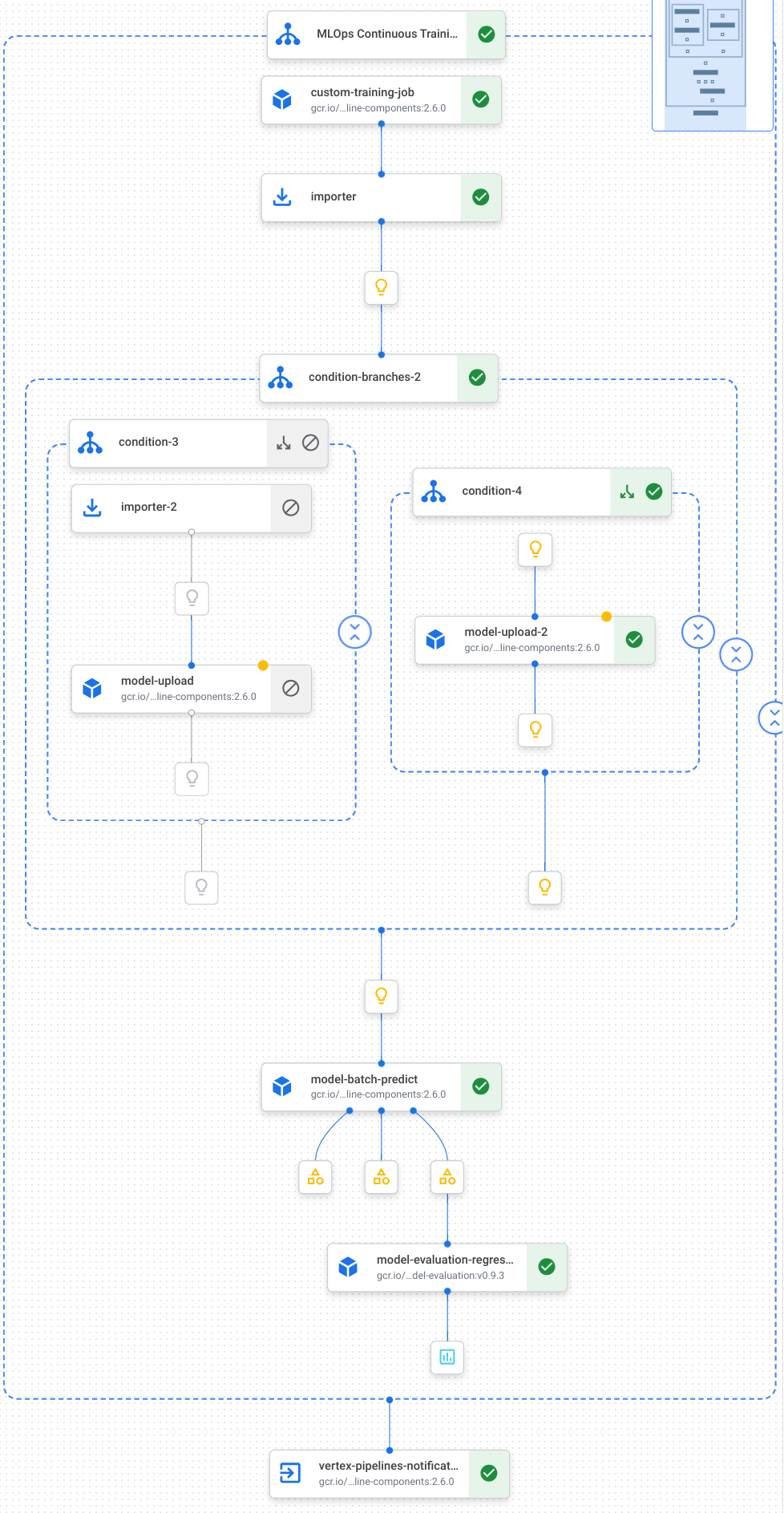
Untuk mengetahui informasi selengkapnya, lihat membuat template pipeline.
Menentukan konstanta dan melakukan inisialisasi klien
Di {i>notebook<i} Anda, tentukan konstanta yang akan digunakan di langkah-langkah selanjutnya:
import os EMAIL_RECIPIENTS = [ "NOTIFY_EMAIL" ] PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-pipeline-datatrigger-tutorial" WORKING_DIR = f"{PIPELINE_ROOT}/mlops-datatrigger-tutorial" os.environ['AIP_MODEL_DIR'] = WORKING_DIR EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" PIPELINE_FILE = PIPELINE_NAME + ".yaml"Ganti
NOTIFY_EMAILdengan alamat email. Saat tugas pipeline selesai, baik berhasil maupun tidak, email akan dikirim ke alamat email tersebut.Lakukan inisialisasi Vertex AI SDK dengan project, bucket staging, lokasi, dan eksperimen.
from google.cloud import aiplatform aiplatform.init( project=PROJECT_ID, staging_bucket=BUCKET_URI, location=REGION, experiment=EXPERIMENT_NAME) aiplatform.autolog()
Menentukan tugas pipeline
Di notebook, tentukan pipeline custom_model_training_evaluation_pipeline Anda:
from kfp import dsl
from kfp.dsl import importer
from kfp.dsl import OneOf
from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp
from google_cloud_pipeline_components.types import artifact_types
from google_cloud_pipeline_components.v1.model import ModelUploadOp
from google_cloud_pipeline_components.v1.batch_predict_job import ModelBatchPredictOp
from google_cloud_pipeline_components.v1.model_evaluation import ModelEvaluationRegressionOp
from google_cloud_pipeline_components.v1.vertex_notification_email import VertexNotificationEmailOp
from google_cloud_pipeline_components.v1.endpoint import ModelDeployOp
from google_cloud_pipeline_components.v1.endpoint import EndpointCreateOp
from google.cloud import aiplatform
# define the train-deploy pipeline
@dsl.pipeline(name="custom-model-training-evaluation-pipeline")
def custom_model_training_evaluation_pipeline(
project: str,
location: str,
training_job_display_name: str,
worker_pool_specs: list,
base_output_dir: str,
prediction_container_uri: str,
model_display_name: str,
batch_prediction_job_display_name: str,
target_field_name: str,
test_data_gcs_uri: list,
ground_truth_gcs_source: list,
batch_predictions_gcs_prefix: str,
batch_predictions_input_format: str="csv",
batch_predictions_output_format: str="jsonl",
ground_truth_format: str="csv",
parent_model_resource_name: str=None,
parent_model_artifact_uri: str=None,
existing_model: bool=False
):
# Notification task
notify_task = VertexNotificationEmailOp(
recipients= EMAIL_RECIPIENTS
)
with dsl.ExitHandler(notify_task, name='MLOps Continuous Training Pipeline'):
# Train the model
custom_job_task = CustomTrainingJobOp(
project=project,
display_name=training_job_display_name,
worker_pool_specs=worker_pool_specs,
base_output_directory=base_output_dir,
location=location
)
# Import the unmanaged model
import_unmanaged_model_task = importer(
artifact_uri=base_output_dir,
artifact_class=artifact_types.UnmanagedContainerModel,
metadata={
"containerSpec": {
"imageUri": prediction_container_uri,
},
},
).after(custom_job_task)
with dsl.If(existing_model == True):
# Import the parent model to upload as a version
import_registry_model_task = importer(
artifact_uri=parent_model_artifact_uri,
artifact_class=artifact_types.VertexModel,
metadata={
"resourceName": parent_model_resource_name
},
).after(import_unmanaged_model_task)
# Upload the model as a version
model_version_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
parent_model=import_registry_model_task.outputs["artifact"],
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
with dsl.Else():
# Upload the model
model_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
# Get the model (or model version)
model_resource = OneOf(model_version_upload_op.outputs["model"], model_upload_op.outputs["model"])
# Batch prediction
batch_predict_task = ModelBatchPredictOp(
project= project,
job_display_name= batch_prediction_job_display_name,
model= model_resource,
location= location,
instances_format= batch_predictions_input_format,
predictions_format= batch_predictions_output_format,
gcs_source_uris= test_data_gcs_uri,
gcs_destination_output_uri_prefix= batch_predictions_gcs_prefix,
machine_type= 'n1-standard-2'
)
# Evaluation task
evaluation_task = ModelEvaluationRegressionOp(
project= project,
target_field_name= target_field_name,
location= location,
# model= model_resource,
predictions_format= batch_predictions_output_format,
predictions_gcs_source= batch_predict_task.outputs["gcs_output_directory"],
ground_truth_format= ground_truth_format,
ground_truth_gcs_source= ground_truth_gcs_source
)
return
Pipeline Anda terdiri dari grafik tugas yang menggunakan Komponen Pipeline Google Cloud berikut:
CustomTrainingJobOp: Menjalankan tugas pelatihan kustom di Vertex AI.ModelUploadOp: Mengupload model machine learning yang dilatih ke registry model.ModelBatchPredictOp: Membuat tugas prediksi batch.ModelEvaluationRegressionOp: Mengevaluasi tugas batch regresi.VertexNotificationEmailOp: Mengirim notifikasi email.
Mengompilasi pipeline
Kompilasi pipeline menggunakan compiler Kubeflow Pipeline (KFP) ke file YAML yang berisi representasi hermetis pipeline Anda.
from kfp import dsl
from kfp import compiler
compiler.Compiler().compile(
pipeline_func=custom_model_training_evaluation_pipeline,
package_path="{}.yaml".format(PIPELINE_NAME),
)
Anda akan melihat file YAML bernama vertex-pipeline-datatrigger-tutorial.yaml di direktori kerja.
Mengupload pipeline sebagai template
Buat repositori jenis
KFPdi Artifact Registry.REPO_NAME = "mlops" # Create a repo in the artifact registry ! gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFPUpload pipeline yang dikompilasi ke repositori.
from kfp.registry import RegistryClient host = f"http://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."}) TEMPLATE_URI = f"http://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest"Di konsol Google Cloud, pastikan template Anda muncul di Pipeline Templates.
Menjalankan pipeline secara manual
Untuk memastikan bahwa pipeline berfungsi, jalankan pipeline secara manual.
Di notebook Anda, tentukan parameter yang diperlukan untuk menjalankan pipeline sebagai tugas.
DATASET_NAME = "mlops" TABLE_NAME = "chicago" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID, "--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False }Membuat dan menjalankan tugas pipeline.
# Create a pipeline job job = aiplatform.PipelineJob( display_name="triggered_custom_regression_evaluation", template_path=TEMPLATE_URI , parameter_values=parameters, pipeline_root=BUCKET_URI, enable_caching=False ) # Run the pipeline job job.run()Tugas ini memerlukan waktu sekitar 30 menit untuk diselesaikan.
Di konsol, Anda akan melihat pipeline baru yang dijalankan di halaman Pipelines:
Setelah pipeline berjalan selesai, Anda akan melihat model baru bernama
taxifare-prediction-modelatau versi model baru di Vertex AI Model Registry:Anda juga akan melihat tugas prediksi batch baru:
Membuat fungsi yang memicu pipeline Anda
Pada langkah ini, Anda akan membuat Cloud Function (generasi ke-2) yang menjalankan pipeline setiap kali data baru dimasukkan ke dalam tabel BigQuery.
Secara khusus, kami menggunakan Eventarc untuk memicu fungsi setiap kali peristiwa google.cloud.bigquery.v2.JobService.InsertJob terjadi. Fungsi ini kemudian menjalankan template pipeline.
Untuk mengetahui informasi selengkapnya, lihat Pemicu Eventarc dan jenis peristiwa yang didukung.
Membuat fungsi dengan pemicu Eventarc
Di konsol Google Cloud, buka Cloud Functions.
Klik tombol Create Function. Di halaman Configuration:
Pilih generasi ke-2 sebagai lingkungan Anda.
Untuk Function name, gunakan mlops.
Untuk Region, pilih region yang sama dengan bucket Cloud Storage dan repositori Artifact Registry Anda.
Untuk Pemicu, pilih Pemicu lainnya. Panel Eventarc Trigger akan terbuka.
Untuk Jenis Pemicu, pilih Sumber Google.
Untuk Penyedia Peristiwa, pilih BigQuery.
Untuk Jenis acara, pilih
google.cloud.bigquery.v2.JobService.InsertJob.Untuk Resource, pilih Specific resource dan tentukan tabel BigQuery
projects/PROJECT_ID/datasets/mlops/tables/chicagoDi kolom Region, pilih lokasi untuk pemicu Eventarc, jika ada. Lihat Lokasi pemicu untuk mengetahui informasi selengkapnya.
Klik Simpan Pemicu.
Jika Anda diminta untuk memberikan peran ke akun layanan, klik Grant All.
Klik Next untuk membuka halaman Code. Di halaman Code:
Setel Runtime ke python 3.12.
Tetapkan Entry point ke
mlops_entrypoint.Dengan Inline Editor, buka file
main.pydan ganti konten dengan berikut ini:Ganti
PROJECT_ID,REGION,BUCKET_NAMEdengan nilai yang Anda gunakan sebelumnya.import json import functions_framework import requests import google.auth import google.auth.transport.requests # CloudEvent function to be triggered by an Eventarc Cloud Audit Logging trigger # Note: this is NOT designed for second-party (Cloud Audit Logs -> Pub/Sub) triggers! @functions_framework.cloud_event def mlops_entrypoint(cloudevent): # Print out the CloudEvent's (required) `type` property # See http://github.com/cloudevents/spec/blob/v1.0.1/spec.md#type print(f"Event type: {cloudevent['type']}") # Print out the CloudEvent's (optional) `subject` property # See http://github.com/cloudevents/spec/blob/v1.0.1/spec.md#subject if 'subject' in cloudevent: # CloudEvent objects don't support `get` operations. # Use the `in` operator to verify `subject` is present. print(f"Subject: {cloudevent['subject']}") # Print out details from the `protoPayload` # This field encapsulates a Cloud Audit Logging entry # See http://cloud.go888ogle.com.fqhub.com/logging/docs/audit#audit_log_entry_structure payload = cloudevent.data.get("protoPayload") if payload: print(f"API method: {payload.get('methodName')}") print(f"Resource name: {payload.get('resourceName')}") print(f"Principal: {payload.get('authenticationInfo', dict()).get('principalEmail')}") row_count = payload.get('metadata', dict()).get('tableDataChange',dict()).get('insertedRowsCount') print(f"No. of rows: {row_count} !!") if row_count: if int(row_count) > 0: print ("Pipeline trigger Condition met !!") submit_pipeline_job() else: print ("No pipeline triggered !!!") def submit_pipeline_job(): PROJECT_ID = 'PROJECT_ID' REGION = 'REGION' BUCKET_NAME = "BUCKET_NAME" DATASET_NAME = "mlops" TABLE_NAME = "chicago" base_output_dir = BUCKET_NAME BUCKET_URI = "gs://{}".format(BUCKET_NAME) PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-mlops-pipeline-tutorial" EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" REPO_NAME ="mlops" TEMPLATE_NAME="custom-model-training-evaluation-pipeline" TRAINING_JOB_DISPLAY_NAME="taxifare-prediction-training-job" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID,"--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False } TEMPLATE_URI = f"http://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest" print("TEMPLATE URI: ", TEMPLATE_URI) request_body = { "name": PIPELINE_NAME, "displayName": PIPELINE_NAME, "runtimeConfig":{ "gcsOutputDirectory": PIPELINE_ROOT, "parameterValues": parameters, }, "templateUri": TEMPLATE_URI } pipeline_url = "http://us-central1-aiplatform.googleapis.com/v1/projects/{}/locations/{}/pipelineJobs".format(PROJECT_ID, REGION) creds, project = google.auth.default() auth_req = google.auth.transport.requests.Request() creds.refresh(auth_req) headers = { 'Authorization': 'Bearer {}'.format(creds.token), 'Content-Type': 'application/json; charset=utf-8' } response = requests.request("POST", pipeline_url, headers=headers, data=json.dumps(request_body)) print(response.text)Buka file
requirements.txtdan ganti konten dengan kode berikut:requests==2.31.0 google-auth==2.25.1
Klik Deploy untuk men-deploy fungsi.
Menyisipkan data untuk memicu pipeline
Di konsol Google Cloud, buka BigQuery Studio.
Klik Create SQL Query dan jalankan kueri SQL berikut dengan mengklik Run.
INSERT INTO `PROJECT_ID.mlops.chicago` ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2022 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )Kueri SQL ini untuk menyisipkan baris baru ke dalam tabel.
Untuk memastikan apakah peristiwa terpicu atau tidak, telusuri
pipeline trigger condition metdi log fungsi Anda.Jika fungsi berhasil dipicu, Anda akan melihat pipeline baru berjalan di Vertex AI Pipelines. Tugas pipeline memerlukan waktu sekitar 30 menit untuk diselesaikan.
Pembersihan
Untuk membersihkan semua resource Google Cloud yang digunakan untuk project ini, Anda dapat menghapus project Google Cloud yang digunakan untuk tutorial.
Selain itu, Anda dapat menghapus setiap resource yang Anda buat untuk tutorial ini.
Menghapus resource dari Vertex AI.
Menghapus model dari Vertex AI Model Registry.
Resource Vertex AI lainnya hanyalah catatan tugas yang berjalan sebelumnya.
Menghapus operasi pipeline:
Hapus tugas pelatihan Kustom:
Hapus tugas prediksi Batch: