Questo documento illustra i passaggi necessari per creare una pipeline che addestra automaticamente un modello personalizzato ogni volta che nuovi dati vengono inseriti nel set di dati utilizzando Vertex AI Pipelines e Cloud Functions.
Obiettivi
Questa procedura è spiegata nei seguenti passaggi:
Acquisisci e prepara set di dati in BigQuery.
Crea e carica un pacchetto di addestramento personalizzato. Quando viene eseguito, legge i dati dal set di dati e addestra il modello.
Crea una pipeline Vertex AI. Questa pipeline esegue il pacchetto di addestramento personalizzato, carica il modello in Vertex AI Model Registry, esegue il job di valutazione e invia una notifica via email.
Esegui la pipeline manualmente.
Creare una Cloud Function con un trigger Eventarc che esegue la pipeline ogni volta che nuovi dati vengono inseriti nel set di dati BigQuery.
Prima di iniziare
Configura il progetto e il blocco note.
Configurazione del progetto
-
Nella console Google Cloud, vai alla pagina del selettore progetto.
-
Seleziona o crea un progetto Google Cloud.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
Crea blocco note
Utilizziamo un blocco note di Colab Enterprise per eseguire parte del codice in questo tutorial.
Se non sei il proprietario del progetto, chiedi a un proprietario del progetto di concederti i ruoli IAM
roles/resourcemanager.projectIamAdmineroles/aiplatform.colabEnterpriseUser.Devi disporre di questi ruoli per utilizzare Colab Enterprise e concedere ruoli e autorizzazioni IAM a te e agli account di servizio.
Nella console Google Cloud, vai alla pagina Blocchi note di Colab Enterprise.
Colab Enterprise ti chiederà di abilitare le seguenti API obbligatorie, se non sono già abilitate.
- API Vertex AI
- API Dataform
- API Compute Engine
Nel menu Regione, seleziona la regione in cui vuoi creare il blocco note. In caso di dubbi, utilizza us-central1 come regione.
Utilizza la stessa regione per tutte le risorse in questo tutorial.
Fai clic su Crea un nuovo blocco note.
Il nuovo blocco note verrà visualizzato nella scheda I miei blocchi note. Per eseguire il codice nel blocco note, aggiungi una cella di codice e fai clic sul pulsante Esegui cella .
Configura l'ambiente di sviluppo
Nel tuo blocco note, installa i seguenti pacchetti Python3.
! pip3 install google-cloud-aiplatform==1.34.0 \ google-cloud-pipeline-components==2.6.0 \ kfp==2.4.0 \ scikit-learn==1.0.2 \ mlflow==2.10.0Imposta il progetto Google Cloud CLI eseguendo questo comando:
PROJECT_ID = "PROJECT_ID" # Set the project id ! gcloud config set project {PROJECT_ID}Sostituisci PROJECT_ID con l'ID progetto. Se necessario, puoi trovare il tuo ID progetto nella console Google Cloud.
Concedi ruoli al tuo Account Google:
! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/bigquery.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.user ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/storage.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/pubsub.editor ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/cloudfunctions.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.viewer ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.configWriter ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/iam.serviceAccountUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/eventarc.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.colabEnterpriseUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/artifactregistry.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/serviceusage.serviceUsageAdminAbilita le seguenti API
- API Artifact Registry
- API BigQuery
- API Cloud Build
- API Cloud Functions
- API Cloud Logging
- API Pub/Sub
- API Cloud Run Admin
- API Cloud Storage
- API Eventarc
- API Service Usage
- API Vertex AI
! gcloud services enable artifactregistry.googleapis.com bigquery.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com logging.googleapis.com pubsub.googleapis.com run.googleapis.com storage-component.googleapis.com eventarc.googleapis.com serviceusage.googleapis.com aiplatform.googleapis.comConcedi i ruoli agli account di servizio del tuo progetto:
Visualizzare i nomi degli account di servizio
! gcloud iam service-accounts listPrendi nota del nome dell'agente di servizio Compute. Deve essere nel formato
[email protected].Concedi i ruoli richiesti all'agente di servizio.
! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID[email protected]"" --role=roles/aiplatform.serviceAgent ! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID[email protected]"" --role=roles/eventarc.eventReceiver
Acquisisci e prepara set di dati
In questo tutorial creerai un modello che prevede la tariffa di una corsa in taxi in base a caratteristiche come tempo di percorrenza, posizione e distanza. Utilizzeremo i dati del set di dati pubblico Chicago Taxi Trips. Questo set di dati include viaggi in taxi dal 2013 a oggi, segnalati alla città di Chicago nel suo ruolo di ente di regolamentazione. Per proteggere la privacy dei conducenti e degli utenti dei taxi contemporaneamente e consentire all'aggregatore di analizzare i dati, l'ID taxi viene mantenuto coerente per ogni numero medaglione di taxi, ma non mostra il numero, in alcuni casi i dati del censimento vengono eliminati e i tempi vengono arrotondati ai 15 minuti più vicini.
Per ulteriori informazioni, visita la pagina su Chicago Taxi Trips on Marketplace.
Crea un set di dati BigQuery
Nella console Google Cloud, vai a BigQuery Studio.
Nel riquadro Explorer, individua il progetto, fai clic su Azioni e poi su Crea set di dati.
Nella pagina Crea set di dati:
In ID set di dati, inserisci
mlops. Per saperne di più, consulta la sezione sulla denominazione dei set di dati.In Tipo di località, scegli più regioni. Ad esempio, scegli USA (più regioni negli Stati Uniti) se utilizzi
us-central1. Una volta creato un set di dati, la località non può essere modificata.Fai clic su Crea set di dati.
Per ulteriori informazioni, consulta l'articolo su come creare set di dati.
Crea e compila la tabella BigQuery
In questa sezione creerai la tabella e importerai un anno di dati dal set di dati pubblico nel set di dati del tuo progetto.
Vai a BigQuery Studio
Fai clic su Crea query SQL ed esegui la seguente query SQL facendo clic su Esegui.
CREATE OR REPLACE TABLE `PROJECT_ID.mlops.chicago` AS ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2019 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )Questa query crea la tabella
<PROJECT_ID>.mlops.chicagoe la compila con i dati della tabellabigquery-public-data.chicago_taxi_trips.taxi_tripspubblica.Per visualizzare lo schema della tabella, fai clic su Vai alla tabella e poi sulla scheda Schema.
Per visualizzare i contenuti del sommario, fai clic sulla scheda Anteprima.
Crea e carica il pacchetto di addestramento personalizzato
In questa sezione creerai un pacchetto Python contenente il codice che legge il set di dati, suddivide i dati in set di addestramento e test e addestra il modello personalizzato. Il pacchetto verrà eseguito come una delle attività della pipeline. Per maggiori informazioni, consulta la pagina relativa alla creazione di un'applicazione di addestramento Python per un container predefinito.
Crea il pacchetto di addestramento personalizzato
Nel blocco note di Colab, crea le cartelle principali per l'applicazione di addestramento:
!mkdir -p training_package/trainerUtilizza il seguente comando per creare un file
__init__.pyin ogni cartella per trasformarlo in un pacchetto:! touch training_package/__init__.py ! touch training_package/trainer/__init__.pyPuoi visualizzare i nuovi file e le nuove cartelle nel riquadro File cartella.
Nel riquadro File, crea un file denominato
task.pynella cartella training_package/trainer con il contenuto seguente.# Import the libraries from sklearn.model_selection import train_test_split, cross_val_score from sklearn.preprocessing import OneHotEncoder, StandardScaler from google.cloud import bigquery, bigquery_storage from sklearn.ensemble import RandomForestRegressor from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline from google import auth from scipy import stats import numpy as np import argparse import joblib import pickle import csv import os # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--project-id', dest='project_id', type=str, help='Project ID.') parser.add_argument('--training-dir', dest='training_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the data and the trained model.') parser.add_argument('--bq-source', dest='bq_source', type=str, help='BigQuery data source for training data.') args = parser.parse_args() # data preparation code BQ_QUERY = """ with tmp_table as ( SELECT trip_seconds, trip_miles, fare, tolls, company, pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude, DATETIME(trip_start_timestamp, 'America/Chicago') trip_start_timestamp, DATETIME(trip_end_timestamp, 'America/Chicago') trip_end_timestamp, CASE WHEN (pickup_community_area IN (56, 64, 76)) OR (dropoff_community_area IN (56, 64, 76)) THEN 1 else 0 END is_airport, FROM `{}` WHERE dropoff_latitude IS NOT NULL and dropoff_longitude IS NOT NULL and pickup_latitude IS NOT NULL and pickup_longitude IS NOT NULL and fare > 0 and trip_miles > 0 and MOD(ABS(FARM_FINGERPRINT(unique_key)), 100) between 0 and 99 ORDER BY RAND() LIMIT 10000) SELECT *, EXTRACT(YEAR FROM trip_start_timestamp) trip_start_year, EXTRACT(MONTH FROM trip_start_timestamp) trip_start_month, EXTRACT(DAY FROM trip_start_timestamp) trip_start_day, EXTRACT(HOUR FROM trip_start_timestamp) trip_start_hour, FORMAT_DATE('%a', DATE(trip_start_timestamp)) trip_start_day_of_week FROM tmp_table """.format(args.bq_source) # Get default credentials credentials, project = auth.default() bqclient = bigquery.Client(credentials=credentials, project=args.project_id) bqstorageclient = bigquery_storage.BigQueryReadClient(credentials=credentials) df = ( bqclient.query(BQ_QUERY) .result() .to_dataframe(bqstorage_client=bqstorageclient) ) # Add 'N/A' for missing 'Company' df.fillna(value={'company':'N/A','tolls':0}, inplace=True) # Drop rows containing null data. df.dropna(how='any', axis='rows', inplace=True) # Pickup and dropoff locations distance df['abs_distance'] = (np.hypot(df['dropoff_latitude']-df['pickup_latitude'], df['dropoff_longitude']-df['pickup_longitude']))*100 # Remove extremes, outliers possible_outliers_cols = ['trip_seconds', 'trip_miles', 'fare', 'abs_distance'] df=df[(np.abs(stats.zscore(df[possible_outliers_cols].astype(float))) < 3).all(axis=1)].copy() # Reduce location accuracy df=df.round({'pickup_latitude': 3, 'pickup_longitude': 3, 'dropoff_latitude':3, 'dropoff_longitude':3}) # Drop the timestamp col X=df.drop(['trip_start_timestamp', 'trip_end_timestamp'],axis=1) # Split the data into train and test X_train, X_test = train_test_split(X, test_size=0.10, random_state=123) ## Format the data for batch predictions # select string cols string_cols = X_test.select_dtypes(include='object').columns # Add quotes around string fields X_test[string_cols] = X_test[string_cols].apply(lambda x: '\"' + x + '\"') # Add quotes around column names X_test.columns = ['\"' + col + '\"' for col in X_test.columns] # Save DataFrame to csv X_test.to_csv(os.path.join(args.training_dir,"test.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Save test data without the target for batch predictions X_test.drop('\"fare\"',axis=1,inplace=True) X_test.to_csv(os.path.join(args.training_dir,"test_no_target.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Separate the target column y_train=X_train.pop('fare') # Get the column indexes col_index_dict = {col: idx for idx, col in enumerate(X_train.columns)} # Create a column transformer pipeline ct_pipe = ColumnTransformer(transformers=[ ('hourly_cat', OneHotEncoder(categories=[range(0,24)], sparse = False), [col_index_dict['trip_start_hour']]), ('dow', OneHotEncoder(categories=[['Mon', 'Tue', 'Sun', 'Wed', 'Sat', 'Fri', 'Thu']], sparse = False), [col_index_dict['trip_start_day_of_week']]), ('std_scaler', StandardScaler(), [ col_index_dict['trip_start_year'], col_index_dict['abs_distance'], col_index_dict['pickup_longitude'], col_index_dict['pickup_latitude'], col_index_dict['dropoff_longitude'], col_index_dict['dropoff_latitude'], col_index_dict['trip_miles'], col_index_dict['trip_seconds']]) ]) # Add the random-forest estimator to the pipeline rfr_pipe = Pipeline([ ('ct', ct_pipe), ('forest_reg', RandomForestRegressor( n_estimators = 20, max_features = 1.0, n_jobs = -1, random_state = 3, max_depth=None, max_leaf_nodes=None, )) ]) # train the model rfr_score = cross_val_score(rfr_pipe, X_train, y_train, scoring = 'neg_mean_squared_error', cv = 5) rfr_rmse = np.sqrt(-rfr_score) print ("Crossvalidation RMSE:",rfr_rmse.mean()) final_model=rfr_pipe.fit(X_train, y_train) # Save the model pipeline with open(os.path.join(args.training_dir,"model.pkl"), 'wb') as model_file: pickle.dump(final_model, model_file)Il codice svolge le seguenti attività:
- Selezione delle caratteristiche.
- Trasformazione dell'ora dei dati di ritiro e consegna dal fuso orario UTC all'ora locale di Chicago.
- Estrazione della data, dell'ora, del giorno della settimana, del mese e dell'anno dalla data/ora ritiro.
- Calcolo della durata della corsa in base all'ora di inizio e di fine.
- Identificare e contrassegnare le corse iniziate o terminate in un aeroporto in base alle aree comuni.
- Il modello di regressione casuale della foresta è addestrato per prevedere la tariffa della corsa in taxi utilizzando il framework scikit-learn.
Il modello addestrato viene salvato in un file di pickle
model.pkl.L'approccio e il feature engineering selezionati si basano sull'esplorazione e sull'analisi dei dati sulla previsione delle tariffe per il taxi di Chicago.
Nel riquadro File, crea un file denominato
setup.pynella cartella training_package con il contenuto seguente.from setuptools import find_packages from setuptools import setup REQUIRED_PACKAGES=["google-cloud-bigquery[pandas]","google-cloud-bigquery-storage"] setup( name='trainer', version='0.1', install_requires=REQUIRED_PACKAGES, packages=find_packages(), include_package_data=True, description='Training application package for chicago taxi trip fare prediction.' )Nel blocco note, esegui
setup.pyper creare la distribuzione di origine per la tua applicazione di addestramento:! cd training_package && python setup.py sdist --formats=gztar && cd ..
Alla fine di questa sezione, il riquadro File dovrebbe contenere i seguenti file e cartelle in training-package.
dist
trainer-0.1.tar.gz
trainer
__init__.py
task.py
trainer.egg-info
__init__.py
setup.py
carica il pacchetto di addestramento personalizzato su Cloud Storage
Creare un bucket Cloud Storage.
REGION="REGION" BUCKET_NAME = "BUCKET_NAME" BUCKET_URI = f"gs://{BUCKET_NAME}" ! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URISostituisci i seguenti valori parametro:
REGION: scegli la stessa regione che scegli durante la creazione del blocco note Colab.BUCKET_NAME: nome del bucket.
Carica il pacchetto di addestramento nel bucket Cloud Storage.
# Copy the training package to the bucket ! gsutil cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/
Crea la tua pipeline
Una pipeline è la descrizione di un flusso di lavoro MLOps sotto forma di grafico di passaggi chiamati attività di pipeline.
In questa sezione definirai le attività della pipeline, le compilerai in YAML e registrerai la pipeline in Artifact Registry in modo che possa essere controllata dalla versione ed eseguita più volte, da un singolo utente o da più utenti.
Ecco una visualizzazione delle attività, inclusi addestramento del modello, caricamento del modello, valutazione del modello e notifica via email, nella nostra pipeline:
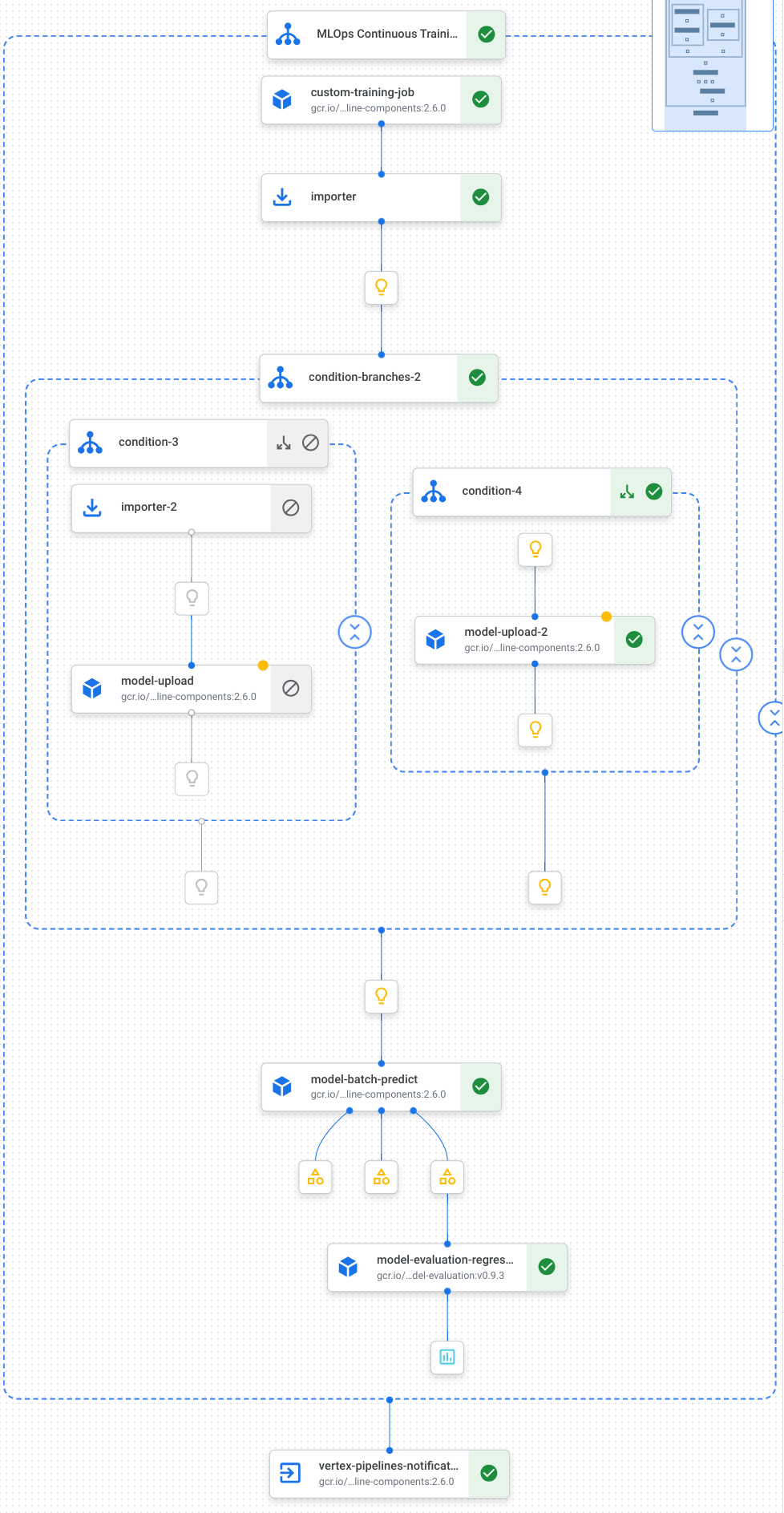
Per ulteriori informazioni, consulta la sezione Creazione di modelli di pipeline.
Definisci le costanti e inizializza i client
Nel blocco note, definisci le costanti che verranno utilizzate nei passaggi successivi:
import os EMAIL_RECIPIENTS = [ "NOTIFY_EMAIL" ] PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-pipeline-datatrigger-tutorial" WORKING_DIR = f"{PIPELINE_ROOT}/mlops-datatrigger-tutorial" os.environ['AIP_MODEL_DIR'] = WORKING_DIR EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" PIPELINE_FILE = PIPELINE_NAME + ".yaml"Sostituisci
NOTIFY_EMAILcon un indirizzo email. Al completamento del job della pipeline, correttamente o meno, viene inviata un'email a quell'indirizzo.Inizializza l'SDK Vertex AI con il progetto, il bucket di gestione temporanea, la località e l'esperimento.
from google.cloud import aiplatform aiplatform.init( project=PROJECT_ID, staging_bucket=BUCKET_URI, location=REGION, experiment=EXPERIMENT_NAME) aiplatform.autolog()
Definisci le attività della pipeline
Nel blocco note, definisci la pipeline custom_model_training_evaluation_pipeline:
from kfp import dsl
from kfp.dsl import importer
from kfp.dsl import OneOf
from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp
from google_cloud_pipeline_components.types import artifact_types
from google_cloud_pipeline_components.v1.model import ModelUploadOp
from google_cloud_pipeline_components.v1.batch_predict_job import ModelBatchPredictOp
from google_cloud_pipeline_components.v1.model_evaluation import ModelEvaluationRegressionOp
from google_cloud_pipeline_components.v1.vertex_notification_email import VertexNotificationEmailOp
from google_cloud_pipeline_components.v1.endpoint import ModelDeployOp
from google_cloud_pipeline_components.v1.endpoint import EndpointCreateOp
from google.cloud import aiplatform
# define the train-deploy pipeline
@dsl.pipeline(name="custom-model-training-evaluation-pipeline")
def custom_model_training_evaluation_pipeline(
project: str,
location: str,
training_job_display_name: str,
worker_pool_specs: list,
base_output_dir: str,
prediction_container_uri: str,
model_display_name: str,
batch_prediction_job_display_name: str,
target_field_name: str,
test_data_gcs_uri: list,
ground_truth_gcs_source: list,
batch_predictions_gcs_prefix: str,
batch_predictions_input_format: str="csv",
batch_predictions_output_format: str="jsonl",
ground_truth_format: str="csv",
parent_model_resource_name: str=None,
parent_model_artifact_uri: str=None,
existing_model: bool=False
):
# Notification task
notify_task = VertexNotificationEmailOp(
recipients= EMAIL_RECIPIENTS
)
with dsl.ExitHandler(notify_task, name='MLOps Continuous Training Pipeline'):
# Train the model
custom_job_task = CustomTrainingJobOp(
project=project,
display_name=training_job_display_name,
worker_pool_specs=worker_pool_specs,
base_output_directory=base_output_dir,
location=location
)
# Import the unmanaged model
import_unmanaged_model_task = importer(
artifact_uri=base_output_dir,
artifact_class=artifact_types.UnmanagedContainerModel,
metadata={
"containerSpec": {
"imageUri": prediction_container_uri,
},
},
).after(custom_job_task)
with dsl.If(existing_model == True):
# Import the parent model to upload as a version
import_registry_model_task = importer(
artifact_uri=parent_model_artifact_uri,
artifact_class=artifact_types.VertexModel,
metadata={
"resourceName": parent_model_resource_name
},
).after(import_unmanaged_model_task)
# Upload the model as a version
model_version_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
parent_model=import_registry_model_task.outputs["artifact"],
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
with dsl.Else():
# Upload the model
model_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
# Get the model (or model version)
model_resource = OneOf(model_version_upload_op.outputs["model"], model_upload_op.outputs["model"])
# Batch prediction
batch_predict_task = ModelBatchPredictOp(
project= project,
job_display_name= batch_prediction_job_display_name,
model= model_resource,
location= location,
instances_format= batch_predictions_input_format,
predictions_format= batch_predictions_output_format,
gcs_source_uris= test_data_gcs_uri,
gcs_destination_output_uri_prefix= batch_predictions_gcs_prefix,
machine_type= 'n1-standard-2'
)
# Evaluation task
evaluation_task = ModelEvaluationRegressionOp(
project= project,
target_field_name= target_field_name,
location= location,
# model= model_resource,
predictions_format= batch_predictions_output_format,
predictions_gcs_source= batch_predict_task.outputs["gcs_output_directory"],
ground_truth_format= ground_truth_format,
ground_truth_gcs_source= ground_truth_gcs_source
)
return
La pipeline è costituita da un grafico di attività che utilizzano i seguenti componenti di Google Cloud Pipeline:
CustomTrainingJobOp: esegue job di addestramento personalizzato in Vertex AI.ModelUploadOp: carica il modello di machine learning addestrato nel registro dei modelli.ModelBatchPredictOp: crea un job di previsione batch.ModelEvaluationRegressionOp: valuta un job batch di regressione.VertexNotificationEmailOp: invia notifiche via email.
Compila la pipeline
Compila la pipeline utilizzando il compilatore Kubeflow Pipelines (KFP) in un file YAML contenente una rappresentazione ermetica della pipeline.
from kfp import dsl
from kfp import compiler
compiler.Compiler().compile(
pipeline_func=custom_model_training_evaluation_pipeline,
package_path="{}.yaml".format(PIPELINE_NAME),
)
Dovresti vedere un file YAML denominato vertex-pipeline-datatrigger-tutorial.yaml nella directory di lavoro.
Carica la pipeline come modello
Crea un repository di tipo
KFPin Artifact Registry.REPO_NAME = "mlops" # Create a repo in the artifact registry ! gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFPCarica la pipeline compilata nel repository.
from kfp.registry import RegistryClient host = f"http://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."}) TEMPLATE_URI = f"http://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest"Nella console Google Cloud, verifica che il modello venga visualizzato in Modelli di pipeline.
Esegui manualmente la pipeline
Per assicurarti che la pipeline funzioni, eseguila manualmente.
Nel blocco note, specifica i parametri necessari per eseguire la pipeline come un job.
DATASET_NAME = "mlops" TABLE_NAME = "chicago" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID, "--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False }Creare ed eseguire un job di pipeline.
# Create a pipeline job job = aiplatform.PipelineJob( display_name="triggered_custom_regression_evaluation", template_path=TEMPLATE_URI , parameter_values=parameters, pipeline_root=BUCKET_URI, enable_caching=False ) # Run the pipeline job job.run()Il job richiede circa 30 minuti.
Nella console, dovresti vedere una nuova pipeline eseguita nella pagina Pipeline:
Al termine dell'esecuzione della pipeline, dovresti vedere un nuovo modello denominato
taxifare-prediction-modelo una nuova versione del modello in Vertex AI Model Registry:Dovresti anche visualizzare un nuovo job di previsione batch:
Crea una funzione che attivi la pipeline
In questo passaggio, creerai una funzione Cloud Functions (2ª generazione) che esegue la pipeline ogni volta che vengono inseriti nuovi dati nella tabella BigQuery.
In particolare, utilizziamo un Eventarc per attivare la funzione ogni volta che si verifica un evento google.cloud.bigquery.v2.JobService.InsertJob. La funzione esegue quindi il modello di pipeline.
Per saperne di più, consulta Trigger Eventarc e i tipi di eventi supportati.
Crea funzione con trigger Eventarc
Nella console Google Cloud, vai a Cloud Functions.
Fai clic sul pulsante Crea funzione. Nella pagina Configurazione:
Seleziona 2a generazione come ambiente.
Per Nome funzione, utilizza mlops.
In Regione, seleziona la stessa regione del bucket Cloud Storage e del repository Artifact Registry.
Per Attivatore, seleziona Altro attivatore. Si apre il riquadro Trigger Eventarc.
Per Tipo di attivatore, scegli Origini Google.
Per Provider di eventi, scegli BigQuery.
Per Tipo di evento, scegli
google.cloud.bigquery.v2.JobService.InsertJob.In Risorsa, scegli Risorsa specifica e specifica la tabella BigQuery.
projects/PROJECT_ID/datasets/mlops/tables/chicagoNel campo Regione, seleziona una località per il trigger Eventarc, se applicabile. Per ulteriori informazioni, consulta Posizione trigger.
Fai clic su Salva attivatore.
Se ti viene chiesto di concedere ruoli agli account di servizio, fai clic su Concedi tutti.
Fai clic su Avanti per andare alla pagina Codice. Nella pagina Codice:
Imposta Runtime su Python 3.12.
Imposta Punto di ingresso su
mlops_entrypoint.Con l'editor in linea, apri il file
main.pye sostituisci i contenuti con quanto segue:Sostituisci
PROJECT_ID,REGION,BUCKET_NAMEcon i valori utilizzati in precedenza.import json import functions_framework import requests import google.auth import google.auth.transport.requests # CloudEvent function to be triggered by an Eventarc Cloud Audit Logging trigger # Note: this is NOT designed for second-party (Cloud Audit Logs -> Pub/Sub) triggers! @functions_framework.cloud_event def mlops_entrypoint(cloudevent): # Print out the CloudEvent's (required) `type` property # See http://github.com/cloudevents/spec/blob/v1.0.1/spec.md#type print(f"Event type: {cloudevent['type']}") # Print out the CloudEvent's (optional) `subject` property # See http://github.com/cloudevents/spec/blob/v1.0.1/spec.md#subject if 'subject' in cloudevent: # CloudEvent objects don't support `get` operations. # Use the `in` operator to verify `subject` is present. print(f"Subject: {cloudevent['subject']}") # Print out details from the `protoPayload` # This field encapsulates a Cloud Audit Logging entry # See http://cloud.go888ogle.com.fqhub.com/logging/docs/audit#audit_log_entry_structure payload = cloudevent.data.get("protoPayload") if payload: print(f"API method: {payload.get('methodName')}") print(f"Resource name: {payload.get('resourceName')}") print(f"Principal: {payload.get('authenticationInfo', dict()).get('principalEmail')}") row_count = payload.get('metadata', dict()).get('tableDataChange',dict()).get('insertedRowsCount') print(f"No. of rows: {row_count} !!") if row_count: if int(row_count) > 0: print ("Pipeline trigger Condition met !!") submit_pipeline_job() else: print ("No pipeline triggered !!!") def submit_pipeline_job(): PROJECT_ID = 'PROJECT_ID' REGION = 'REGION' BUCKET_NAME = "BUCKET_NAME" DATASET_NAME = "mlops" TABLE_NAME = "chicago" base_output_dir = BUCKET_NAME BUCKET_URI = "gs://{}".format(BUCKET_NAME) PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-mlops-pipeline-tutorial" EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" REPO_NAME ="mlops" TEMPLATE_NAME="custom-model-training-evaluation-pipeline" TRAINING_JOB_DISPLAY_NAME="taxifare-prediction-training-job" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID,"--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False } TEMPLATE_URI = f"http://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest" print("TEMPLATE URI: ", TEMPLATE_URI) request_body = { "name": PIPELINE_NAME, "displayName": PIPELINE_NAME, "runtimeConfig":{ "gcsOutputDirectory": PIPELINE_ROOT, "parameterValues": parameters, }, "templateUri": TEMPLATE_URI } pipeline_url = "http://us-central1-aiplatform.googleapis.com/v1/projects/{}/locations/{}/pipelineJobs".format(PROJECT_ID, REGION) creds, project = google.auth.default() auth_req = google.auth.transport.requests.Request() creds.refresh(auth_req) headers = { 'Authorization': 'Bearer {}'.format(creds.token), 'Content-Type': 'application/json; charset=utf-8' } response = requests.request("POST", pipeline_url, headers=headers, data=json.dumps(request_body)) print(response.text)Apri il file
requirements.txte sostituisci i contenuti con il seguente:requests==2.31.0 google-auth==2.25.1
Fai clic su Esegui il deployment per eseguire il deployment della funzione.
Inserisci i dati per attivare la pipeline
Nella console Google Cloud, vai a BigQuery Studio.
Fai clic su Crea query SQL ed esegui la seguente query SQL facendo clic su Esegui.
INSERT INTO `PROJECT_ID.mlops.chicago` ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2022 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )Questa query SQL per inserire nuove righe nella tabella.
Per verificare se l'evento è stato attivato, cerca
pipeline trigger condition metnel log della funzione.Se la funzione viene attivata correttamente, dovresti vedere una nuova pipeline eseguita in Vertex AI Pipelines. Il job di pipeline richiede circa 30 minuti.
Esegui la pulizia
Per eseguire la pulizia di tutte le risorse Google Cloud utilizzate per questo progetto, puoi eliminare il progetto Google Cloud che hai utilizzato per il tutorial.
In caso contrario, puoi eliminare le singole risorse che hai creato per questo tutorial.
Elimina il modello come segue:
Nella sezione Vertex AI, vai alla pagina Model Registry.
Accanto al nome del modello, fai clic sul menu Azioni e scegli Elimina modello.
Elimina le esecuzioni della pipeline:
Vai alla pagina Esecuzioni pipeline.
Accanto al nome di ogni esecuzione della pipeline, fai clic sul menu Azioni e scegli Elimina esecuzione pipeline.
Elimina il job di addestramento personalizzato:
Accanto al nome di ogni job di addestramento personalizzato, fai clic sul menu Azioni e scegli Elimina job di addestramento personalizzato.
Elimina i job di previsione batch come segue:
Accanto al nome di ogni job di previsione batch, fai clic sul menu Azioni e scegli Elimina job di previsione batch.