以下代码示例展示如何使用事件驱动型 Cloud Functions 函数以及 Cloud Pub/Sub 触发器来编写、部署和触发流水线。
构建和编译简单的流水线
使用 Kubeflow Pipelines SDK 构建计划流水线并将其编译为 YAML 文件。
示例 hello-world-scheduled-pipeline:
from kfp import compiler
from kfp import dsl
# A simple component that prints and returns a greeting string
@dsl.component
def hello_world(message: str) -> str:
greeting_str = f'Hello, {message}'
print(greeting_str)
return greeting_str
# A simple pipeline that contains a single hello_world task
@dsl.pipeline(
name='hello-world-scheduled-pipeline')
def hello_world_scheduled_pipeline(greet_name: str):
hello_world_task = hello_world(greet_name)
# Compile the pipeline and generate a YAML file
compiler.Compiler().compile(pipeline_func=hello_world_scheduled_pipeline,
package_path='hello_world_scheduled_pipeline.yaml')
将已编译的流水线 YAML 上传到 Cloud Storage 存储桶
在 Google Cloud 控制台中打开 Cloud Storage 浏览器。
点击您在配置项目时创建的 Cloud Storage 存储分区。
使用现有文件夹或新文件夹,将已编译的流水线 YAML(在此示例中为
hello_world_scheduled_pipeline.yaml)上传到所选文件夹。点击上传的 YAML 文件以访问详细信息。复制 gsutil URI 以备后用。
使用 Pub/Sub 触发器创建 Cloud Functions 函数
访问控制台中的 Cloud Functions 页面。
点击创建函数按钮。
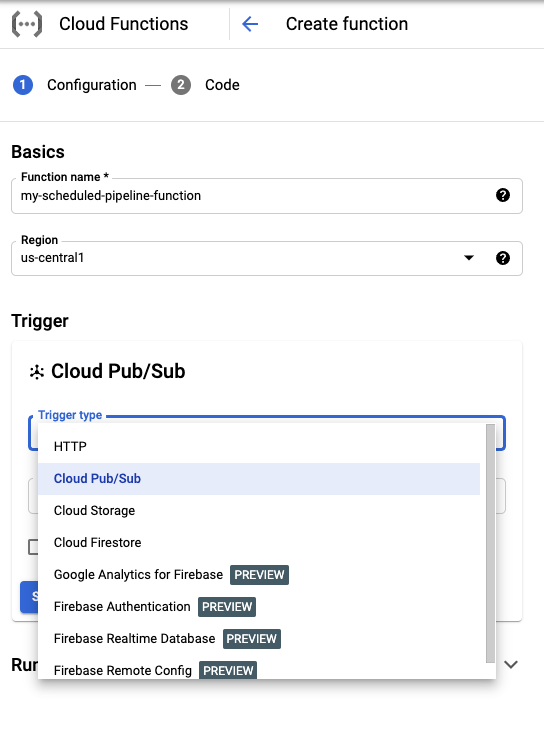
在基础知识部分中,为您的函数命名(例如
my-scheduled-pipeline-function)。在触发器部分中,选择 Cloud Pub/Sub 作为触发器类型。
在选择 Cloud Pub/Sub 主题下拉列表中,点击创建主题。
在创建主题框中,为您的新主题命名(例如
my-scheduled-pipeline-topic),然后选择创建主题。将所有其他字段保留为默认值,然后点击保存以保存“触发器”部分配置。
将其他所有字段保留为默认值,然后点击下一步以继续转到“代码”部分。
在运行时下,选择 Python 3.7。
在入口点中,输入“订阅”(示例代码入口点函数名称)。
在源代码下,选择内嵌编辑器(如果尚未选择)。
在
main.py文件中,添加以下代码:import base64 import json from google.cloud import aiplatform PROJECT_ID = 'your-project-id' # <---CHANGE THIS REGION = 'your-region' # <---CHANGE THIS PIPELINE_ROOT = 'your-cloud-storage-pipeline-root' # <---CHANGE THIS def subscribe(event, context): """Triggered from a message on a Cloud Pub/Sub topic. Args: event (dict): Event payload. context (google.cloud.functions.Context): Metadata for the event. """ # decode the event payload string payload_message = base64.b64decode(event['data']).decode('utf-8') # parse payload string into JSON object payload_json = json.loads(payload_message) # trigger pipeline run with payload trigger_pipeline_run(payload_json) def trigger_pipeline_run(payload_json): """Triggers a pipeline run Args: payload_json: expected in the following format: { "pipeline_spec_uri": "<path-to-your-compiled-pipeline>", "parameter_values": { "greet_name": "<any-greet-string>" } } """ pipeline_spec_uri = payload_json['pipeline_spec_uri'] parameter_values = payload_json['parameter_values'] # Create a PipelineJob using the compiled pipeline from pipeline_spec_uri aiplatform.init( project=PROJECT_ID, location=REGION, ) job = aiplatform.PipelineJob( display_name='hello-world-pipeline-cloud-function-invocation', template_path=pipeline_spec_uri, pipeline_root=PIPELINE_ROOT, enable_caching=False, parameter_values=parameter_values ) # Submit the PipelineJob job.submit()替换以下内容:
- PROJECT_ID:在其中运行此流水线的 Google Cloud 项目。
- REGION:此流水线运行所在的区域。
- PIPELINE_ROOT:指定流水线服务账号可以访问的 Cloud Storage URI。流水线运行的工件存储在流水线根目录中。
在
requirements.txt文件中,将内容替换为以下软件包要求:google-api-python-client>=1.7.8,<2 google-cloud-aiplatform点击部署以部署该函数。