Halaman ini menjelaskan cara menayangkan permintaan prediksi dengan server inferensi NVIDIA Triton menggunakan Vertex AI Prediction. Server inferensi NVIDIA Triton (Triton) adalah solusi inferensi open source dari NVIDIA yang dioptimalkan untuk CPU dan GPU serta menyederhanakan proses penayangan inferensi.
NVIDIA Triton terkait Prediksi Vertex AI
Vertex AI Prediction mendukung deployment model di server inferensi Triton yang berjalan pada container kustom yang dipublikasikan oleh NVIDIA GPU Cloud (NGC) - Image server inferensi NVIDIA Triton. Image Triton dari NVIDIA memiliki semua paket dan konfigurasi yang diperlukan yang memenuhi persyaratan Vertex AI untuk image container penayangan kustom. Image ini berisi server inferensi Triton dengan dukungan untuk model TensorFlow, PyTorch, TensorRT, ONNX, dan OpenVINO. Image ini juga menyertakan backend FIL (Forest Inference Library) yang mendukung pengoperasian framework ML seperti XGBoost, LightGBM, dan Scikit-Learn.
Triton memuat model dan mengekspos endpoint REST pengelolaan inferensi, kesehatan, dan model yang menggunakan protokol inferensi standar. Saat men-deploy model ke Vertex AI, Triton mengenali lingkungan Vertex AI dan mengadopsi protokol Vertex AI Prediction untuk health check dan permintaan prediksi.
Daftar berikut menguraikan fitur utama dan kasus penggunaan server inferensi NVIDIA Triton:
- Dukungan untuk berbagai framework Deep Learning dan Machine Learning: Triton mendukung deployment beberapa model dan perpaduan antara framework dan format model - TensorFlow (SavedModel dan GraphDef), PyTorch (TorchScript), TensorRT, ONNX, OpenVINO, dan backend FIL untuk mendukung framework seperti XGBoost, LightGBM, Scikit-Learn, dan format model Python atau C++ kustom.
- Eksekusi beberapa model serentak: Triton memungkinkan beberapa model, beberapa instance dari model yang sama, atau keduanya dieksekusi secara serentak pada resource komputasi yang sama dengan nol GPU atau lebih.
- Ansambel model (rantai atau pipeline): Ansambel Triton mendukung kasus penggunaan dengan beberapa model disusun sebagai pipeline (atau DAG, Directed Acyclic Graph) dengan tensor input dan output yang terhubung di antara mereka. Selain itu, dengan backend Triton Python, Anda dapat menyertakan semua logika alur pra-pemrosesan, pascapemrosesan, atau kontrol yang ditentukan oleh Business Logic Scripting (BLS).
- Beroperasi di backend CPU dan GPU: Triton mendukung inferensi untuk model yang di-deploy pada node dengan CPU dan GPU.
- Pengelompokan permintaan prediksi secara dinamis: Untuk model yang mendukung pengelompokan, Triton memiliki algoritme penjadwalan dan pengelompokan bawaan. Algoritma ini secara dinamis menggabungkan permintaan inferensi individual ke dalam batch pada sisi server untuk meningkatkan throughput inferensi dan meningkatkan penggunaan GPU.
Untuk mengetahui informasi selengkapnya tentang server inferensi NVIDIA Triton, lihat dokumentasi Triton.
Image container NVIDIA Triton yang tersedia
Tabel berikut menunjukkan image Dockter Triton yang tersedia di Katalog NVIDIA NGC. Pilih image berdasarkan framework model, backend, dan ukuran image container yang Anda gunakan.
xx dan yy masing-masing merujuk pada versi utama dan minor dari Triton.
| Image NVIDIA Triton | Dukungan |
|---|---|
xx.yy-py3 |
Container penuh dengan dukungan untuk model TensorFlow, PyTorch, TensorRT, ONNX, dan OpenVINO |
xx.yy-pyt-python-py3 |
Khusus backend PyTorch dan Python |
xx.yy-tf2-python-py3 |
Khusus backend TensorFlow 2.x dan Python |
xx.yy-py3-min |
Sesuaikan container Triton sesuai kebutuhan |
Memulai: Menayangkan Prediksi dengan NVIDIA Triton
Gambar berikut menunjukkan arsitektur tingkat tinggi Triton di Vertex AI Prediction:
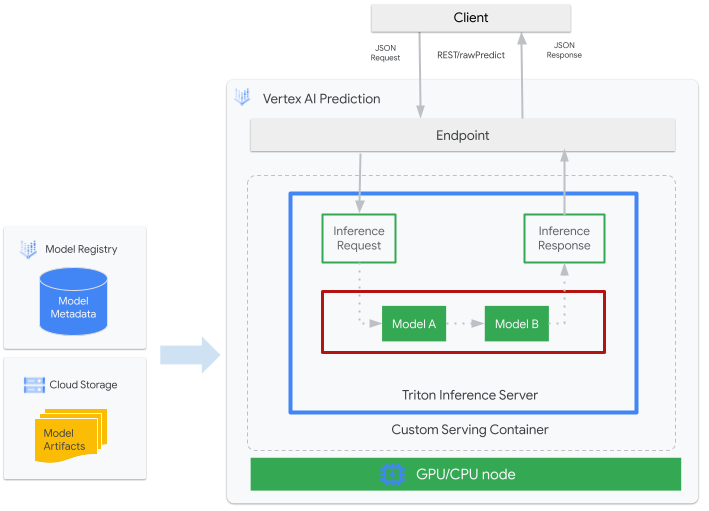
- Model ML yang akan dilayani oleh Triton terdaftar di Vertex AI Model Registry. Metadata model merujuk pada lokasi artefak model di Cloud Storage, container penayangan kustom, dan konfigurasinya.
- Model dari Vertex AI Model Registry di-deploy ke endpoint Vertex AI Prediction yang menjalankan server inferensi Triton sebagai container kustom pada node komputasi dengan CPU dan GPU.
- Permintaan inferensi tiba di server inferensi Triton melalui endpoint Vertex AI Prediction dan dirutekan ke penjadwal yang sesuai.
- Backend melakukan inferensi menggunakan input yang diberikan dalam batch permintaan dan menampilkan respons.
- Triton menyediakan endpoint kondisi kesiapan dan keaktifan, yang memungkinkan integrasi Triton ke dalam lingkungan deployment seperti Vertex AI Prediction.
Tutorial ini menunjukkan cara menggunakan container kustom yang menjalankan server inferensi NVIDIA Triton untuk men-deploy model machine learning (ML) pada Vertex AI Prediction, yang menayangkan prediksi online. Anda men-deploy container yang menjalankan Triton untuk menayangkan prediksi dari model deteksi objek dari TensorFlow Hub yang telah dilatih sebelumnya di set data COCO 2017. Selanjutnya, Anda dapat menggunakan Vertex AI Prediction untuk mendeteksi objek dalam image.
Anda juga dapat menjalankan tutorial di Vertex AI Workbench dengan mengikuti Jupyter Notebook ini.
Sebelum memulai
- Login ke akun Google Cloud Anda. Jika Anda baru menggunakan Google Cloud, buat akun untuk mengevaluasi performa produk kami dalam skenario dunia nyata. Pelanggan baru juga mendapatkan kredit gratis senilai $300 untuk menjalankan, menguji, dan men-deploy workload.
-
Di konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
-
Pastikan penagihan telah diaktifkan untuk project Google Cloud Anda.
-
Enable the Vertex AI API and Artifact Registry API APIs.
-
Di konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
-
Pastikan penagihan telah diaktifkan untuk project Google Cloud Anda.
-
Enable the Vertex AI API and Artifact Registry API APIs.
-
Di konsol Google Cloud, aktifkan Cloud Shell.
Di bagian bawah Google Cloud Console, Cloud Shell sesi akan terbuka dan menampilkan perintah command line. Cloud Shell adalah lingkungan shell dengan Google Cloud CLI yang sudah terinstal, dan dengan nilai yang sudah ditetapkan untuk project Anda saat ini. Diperlukan waktu beberapa detik untuk melakukan inisialisasi sesi.
Dalam tutorial ini, sebaiknya gunakan Cloud Shell untuk berinteraksi dengan Google Cloud. Jika Anda ingin menggunakan shell Bash yang berbeda, bukan Cloud Shell, lakukan konfigurasi tambahan berikut:
- Menginstal Google Cloud CLI.
-
Untuk initialize gcloud CLI, jalankan perintah berikut:
gcloud init
- Ikuti dokumentasi Artifact Registry untuk Menginstal Docker.
Membangun dan mengirim image container
Untuk menggunakan container kustom, Anda harus menentukan image container Docker yang memenuhi persyaratan container kustom. Bagian ini menjelaskan cara membuat image container dan mengirimkannya ke Artifact Registry.
Download artefak model
Artefak model adalah file yang dibuat oleh pelatihan ML yang dapat Anda gunakan untuk menayangkan prediksi. Model ini berisi, setidaknya, struktur dan bobot model ML terlatih Anda. Format artefak model bergantung pada framework ML yang Anda gunakan untuk pelatihan.
Untuk tutorial ini, daripada melatih model dari awal, download model deteksi objek dari TensorFlow Hub yang telah dilatih pada set data COCO 2017.
Triton mengharapkan repositori model diatur dalam struktur berikut untuk menayangkan format TensorFlow SavedModel:
└── model-repository-path
└── model_name
├── config.pbtxt
└── 1
└── model.savedmodel
└── <saved-model-files>
File config.pbtxt menjelaskan konfigurasi model untuk model tersebut. Secara default, file konfigurasi model yang berisi setelan yang diperlukan harus disediakan. Namun, jika Triton dimulai dengan
opsi --strict-model-config=false, dalam beberapa kasus, konfigurasi
model dapat
dibuat secara otomatis
oleh Triton dan tidak harus disediakan secara eksplisit.
Secara khusus, model TensorRT, TensorFlowSavedModel, dan ONNX tidak memerlukan file konfigurasi model karena Triton dapat memperoleh semua setelan yang diperlukan secara otomatis. Semua jenis model lainnya harus menyediakan file konfigurasi model.
# Download and organize model artifacts according to the Triton model repository spec
mkdir -p models/object_detector/1/model.savedmodel/
curl -L "http://tfhub.dev/tensorflow/faster_rcnn/resnet101_v1_640x640/1?tf-hub-format=compressed" | \
tar -zxvC ./models/object_detector/1/model.savedmodel/
ls -ltr ./models/object_detector/1/model.savedmodel/
Setelah mendownload model secara lokal, repositori model akan diatur sebagai berikut:
./models
└── object_detector
└── 1
└── model.savedmodel
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
Menyalin artefak model ke bucket Cloud Storage
Artefak model yang didownload, termasuk file konfigurasi model, dikirim ke
bucket Cloud Storage yang ditentukan oleh MODEL_ARTIFACTS_REPOSITORY, yang dapat digunakan
saat Anda membuat resource model Vertex AI.
gsutil cp -r ./models/object_detector MODEL_ARTIFACTS_REPOSITORY/
Membuat repositori Artifact Registry
Buat repositori Artifact Registry untuk menyimpan image container yang akan Anda buat di bagian berikutnya.
Aktifkan layanan Artifact Registry API untuk project Anda.
gcloud services enable artifactregistry.googleapis.com
Jalankan perintah berikut di shell Anda untuk membuat repositori Artifact Registry:
gcloud artifacts repositories create getting-started-nvidia-triton \
--repository-format=docker \
--location=LOCATION \
--description="NVIDIA Triton Docker repository"
Ganti LOCATION dengan region tempat Artifact Registry menyimpan image container Anda. Kemudian, Anda harus membuat resource model Vertex AI
di endpoint regional yang cocok dengan region ini, jadi pilih region
tempat Vertex AI memiliki endpoint
regional,
seperti us-central1.
Setelah menyelesaikan operasi, perintah akan mencetak output berikut:
Created repository [getting-started-nvidia-triton].
Membangun image container
NVIDIA menyediakan
image Docker untuk membangun image container yang menjalankan Triton
dan sesuai dengan persyaratan
container kustom Vertex AI untuk
penayangan. Anda dapat mengambil image menggunakan docker dan memberi tag pada jalur Artifact Registry tempat image akan dikirim.
NGC_TRITON_IMAGE_URI="nvcr.io/nvidia/tritonserver:22.01-py3"
docker pull $NGC_TRITON_IMAGE_URI
docker tag $NGC_TRITON_IMAGE_URI LOCATION-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference
Ganti kode berikut:
- LOCATION: region repositori Artifact Registry Anda, seperti yang ditentukan di bagian sebelumnya
- PROJECT_ID: ID project Google Cloud Anda
Perintah mungkin berjalan selama beberapa menit.
Menyiapkan file payload untuk menguji permintaan prediksi
Untuk mengirim permintaan prediksi ke server container, siapkan payload dengan contoh file image yang menggunakan Python. Jalankan skrip python berikut untuk membuat file payload:
import json
import requests
# install required packages before running
# pip install pillow numpy --upgrade
from PIL import Image
import numpy as np
# method to generate payload from image url
def generate_payload(image_url):
# download image from url and resize
image_inputs = Image.open(requests.get(image_url, stream=True).raw)
image_inputs = image_inputs.resize((200, 200))
# convert image to numpy array
image_tensor = np.asarray(image_inputs)
# derive image shape
image_shape = [1] + list(image_tensor.shape)
# create payload request
payload = {
"id": "0",
"inputs": [
{
"name": "input_tensor",
"shape": image_shape,
"datatype": "UINT8",
"parameters": {},
"data": image_tensor.tolist(),
}
],
}
# save payload as json file
payload_file = "instances.json"
with open(payload_file, "w") as f:
json.dump(payload, f)
print(f"Payload generated at {payload_file}")
return payload_file
if __name__ == '__main__':
image_url = "http://github.com/tensorflow/models/raw/master/research/object_detection/test_images/image2.jpg"
payload_file = generate_payload(image_url)
Skrip Python menghasilkan payload dan mencetak respons berikut:
Payload generated at instances.json
Menjalankan container secara lokal (opsional)
Sebelum mengirim image container ke Artifact Registry untuk menggunakannya dengan Vertex AI Prediction, Anda dapat menjalankannya sebagai container di lingkungan lokal Anda guna memverifikasi bahwa server berfungsi seperti yang diharapkan:
Untuk menjalankan image container secara lokal, jalankan perintah berikut di shell Anda:
docker run -t -d -p 8000:8000 --rm \ --name=local_object_detector \ -e AIP_MODE=True \ LOCATION-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \ --model-repository MODEL_ARTIFACTS_REPOSITORY \ --strict-model-config=falseGanti baris berikut, seperti yang Anda lakukan di bagian sebelumnya:
- LOCATION: region repositori Artifact Registry Anda, seperti yang ditentukan di bagian sebelumnya
- PROJECT_ID: ID project Google Cloud Anda
- MODEL_ARTIFACTS_REPOSITORY: jalur Cloud Storage tempat artefak model berada
Perintah ini menjalankan container dalam mode terpisah, yang memetakan port
8000dari container ke port8000dari lingkungan lokal. Image Triton dari NGC mengonfigurasi Triton untuk menggunakan port8000.Untuk mengirimkan health check ke server penampung, jalankan perintah berikut di shell Anda:
curl -s -o /dev/null -w "%{http_code}" http://localhost:8000/v2/health/readyJika berhasil, server akan menampilkan kode status sebagai
200.Jalankan perintah berikut untuk mengirim permintaan prediksi ke server container menggunakan payload yang dihasilkan sebelumnya dan dapatkan respons prediksi:
curl -X POST \ -H "Content-Type: application/json" \ -d @instances.json \ localhost:8000/v2/models/object_detector/infer | jq -c '.outputs[] | select(.name == "detection_classes")'Permintaan ini menggunakan salah satu Image uji yang disertakan dengan contoh deteksi objek TensorFlow.
Jika berhasil, server akan menampilkan prediksi berikut:
{"name":"detection_classes","datatype":"FP32","shape":[1,300],"data":[38,1,...,44]}Untuk menghentikan container, jalankan perintah berikut di shell Anda:
docker stop local_object_detector
{kind=link}
Mengirim container ke Artifact Registry
Mengonfigurasi Docker untuk mengakses Artifact Registry. Kemudian, kirim image container Anda ke repositori Artifact Registry.
Untuk memberikan izin penginstalan Docker lokal kepada Artifact Registry di region yang dipilih, jalankan perintah berikut di shell Anda:
gcloud auth configure-docker LOCATION-docker.pkg.dev- Ganti LOCATION dengan region tempat Anda membuat repositori di bagian sebelumnya.
Untuk mengirim image container yang baru saja Anda buat ke Artifact Registry, jalankan perintah berikut di shell Anda:
docker push LOCATION-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inferenceGanti baris berikut, seperti yang Anda lakukan di bagian sebelumnya:
- LOCATION: region repositori Artifact Registry Anda, seperti yang ditentukan di bagian sebelumnya
- PROJECT_ID: ID project Google Cloud Anda
Men-deploy model
Membuat model
Untuk membuat resource Model yang menggunakan container kustom yang menjalankan
Triton, jalankan perintah
gcloud ai models upload berikut:
gcloud ai models upload \
--region=LOCATION \
--display-name=DEPLOYED_MODEL_NAME \
--container-image-uri=LOCATION-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \
--artifact-uri=MODEL_ARTIFACTS_REPOSITORY \
--container-args='--strict-model-config=false'
- LOCATION_ID: Region tempat Anda menggunakan Vertex AI.
- PROJECT_ID: ID project Google Cloud Anda
-
DEPLOYED_MODEL_NAME: Nama untuk
DeployedModel. Anda juga dapat menggunakan nama tampilanModeluntukDeployedModel.
Argumen --container-args='--strict-model-config=false' memungkinkan
Triton menghasilkan konfigurasi model secara otomatis.
Membuat endpoint
Anda harus men-deploy model ke endpoint sebelum model ini dapat digunakan untuk menayangkan prediksi online. Jika Anda men-deploy model ke endpoint yang sudah ada, Anda dapat melewati langkah ini. Contoh berikut menggunakan
perintah
gcloud ai endpoints create:
gcloud ai endpoints create \
--region=LOCATION \
--display-name=ENDPOINT_NAME
Ganti kode berikut:
- LOCATION_ID: Region tempat Anda menggunakan Vertex AI.
- ENDPOINT_NAME: Nama tampilan endpoint.
Alat Google Cloud CLI mungkin memerlukan waktu beberapa detik untuk membuat endpoint.
Men-deploy model ke endpoint
Setelah endpoint siap, deploy model ke endpoint. Saat Anda men-deploy model ke endpoint, layanan ini akan mengaitkan resource fisik dengan model yang menjalankan Triton untuk menayangkan prediksi online.
Contoh berikut menggunakan perintah gcloud ai endpoints deploy-model untuk men-deploy Model ke endpoint yang menjalankan Triton di GPU guna mempercepat penayangan prediksi dan tanpa memisahkan traffic antara beberapa resource
DeployedModel:
ENDPOINT_ID=$(gcloud ai endpoints list \
--region=LOCATION \
--filter=display_name=ENDPOINT_NAME \
--format="value(name)")
MODEL_ID=$(gcloud ai models list \
--region=LOCATION \
--filter=display_name=DEPLOYED_MODEL_NAME \
--format="value(name)")
gcloud ai endpoints deploy-model $ENDPOINT_ID \
--region=LOCATION \
--model=$MODEL_ID \
--display-name=DEPLOYED_MODEL_NAME \
--machine-type=MACHINE_TYPE \
--min-replica-count=MIN_REPLICA_COUNT \
--max-replica-count=MAX_REPLICA_COUNT \
--accelerator=count=ACCELERATOR_COUNT,type=ACCELERATOR_TYPE \
--traffic-split=0=100
Ganti kode berikut:
- LOCATION_ID: Region tempat Anda menggunakan Vertex AI.
- ENDPOINT_NAME: Nama tampilan endpoint.
-
DEPLOYED_MODEL_NAME: Nama untuk
DeployedModel. Anda juga dapat menggunakan nama tampilanModeluntukDeployedModel. -
MACHINE_TYPE: Opsional. Resource mesin yang digunakan untuk setiap node deployment ini. Setelan defaultnya adalah
n1-standard-2. Pelajari jenis-jenis mesin lebih lanjut. - MIN_REPLICA_COUNT: Jumlah minimum node untuk deployment ini. Jumlah node dapat ditingkatkan atau diturunkan sesuai kebutuhan beban prediksi, hingga mencapai jumlah maksimum node dan tidak pernah kurang dari jumlah ini.
- MAX_REPLICA_COUNT: Jumlah maksimum node untuk deployment ini. Jumlah node dapat ditingkatkan atau diturunkan sesuai kebutuhan beban prediksi, hingga jumlah node ini, dan tidak pernah kurang dari jumlah minimum node.
- ACCELERATOR_TYPE: Mengelola konfigurasi akselerator untuk penayangan GPU. Saat men-deploy model dengan Jenis Mesin Compute Engine, akselerator GPU juga dapat dipilih dan jenis harus ditentukan. Pilihannya adalah 'nvidia-tesla-a100', 'nvidia-tesla-k80', 'nvidia-tesla-p100', 'nvidia-tesla-p4', 'nvidia-tesla-t4', 'nvidia -tesla-v100'.
- ACCELERATOR_COUNT: Jumlah akselerator yang harus dipasang ke setiap mesin yang menjalankan tugas. Biasanya jumlahnya adalah 1. Jika tidak ditentukan, nilai defaultnya adalah 1.
Alat Google Cloud CLI mungkin memerlukan waktu beberapa detik untuk men-deploy model ke endpoint. Setelah model berhasil di-deploy, perintah ini akan mencetak output berikut:
Deployed a model to the endpoint xxxxx. Id of the deployed model: xxxxx.
Mendapatkan prediksi online dari model yang di-deploy
Untuk memanggil model melalui endpoint Vertex AI Prediction, format
permintaan prediksi menggunakan Objek JSON Permintaan Inferensi standar
atau Objek JSON Permintaan Inferensi dengan ekstensi biner
dan mengirimkan permintaan ke REST rawPredict Vertex AI Prediction.
Contoh berikut menggunakan perintah
gcloud ai endpoints raw-predict:
ENDPOINT_ID=$(gcloud ai endpoints list \
--region=LOCATION \
--filter=display_name=ENDPOINT_NAME \
--format="value(name)")
gcloud ai endpoints raw-predict $ENDPOINT_ID \
--region=LOCATION \
--http-headers=Content-Type=application/json \
--request @instances.json
Ganti kode berikut:
- LOCATION_ID: Region tempat Anda menggunakan Vertex AI.
- ENDPOINT_NAME: Nama tampilan endpoint.
Endpoint akan menampilkan respons berikut untuk permintaan yang valid:
{
"id": "0",
"model_name": "object_detector",
"model_version": "1",
"outputs": [{
"name": "detection_anchor_indices",
"datatype": "FP32",
"shape": [1, 300],
"data": [2.0, 1.0, 0.0, 3.0, 26.0, 11.0, 6.0, 92.0, 76.0, 17.0, 58.0, ...]
}]
}
Pembersihan
Agar tidak menimbulkan biaya Vertex AI dan biaya Artifact Registry lebih lanjut, hapus resource Google Cloud yang Anda buat selama tutorial ini:
Untuk membatalkan deployment model dari endpoint dan menghapus endpoint, jalankan perintah berikut di shell Anda:
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION \ --filter=display_name=ENDPOINT_NAME \ --format="value(name)") DEPLOYED_MODEL_ID=$(gcloud ai endpoints describe $ENDPOINT_ID \ --region=LOCATION \ --format="value(deployedModels.id)") gcloud ai endpoints undeploy-model $ENDPOINT_ID \ --region=LOCATION \ --deployed-model-id=$DEPLOYED_MODEL_ID gcloud ai endpoints delete $ENDPOINT_ID \ --region=LOCATION \ --quietGanti LOCATION dengan region tempat Anda membuat model di bagian sebelumnya.
Untuk menghapus model, jalankan perintah berikut di shell Anda:
MODEL_ID=$(gcloud ai models list \ --region=LOCATION \ --filter=display_name=DEPLOYED_MODEL_NAME \ --format="value(name)") gcloud ai models delete $MODEL_ID \ --region=LOCATION \ --quietGanti LOCATION dengan region tempat Anda membuat model di bagian sebelumnya.
Untuk menghapus repositori Artifact Registry dan image container di dalamnya, jalankan perintah berikut di shell Anda:
gcloud artifacts repositories delete getting-started-nvidia-triton \ --location=LOCATION \ --quietGanti LOCATION dengan region tempat Anda membuat repositori Artifact Registry di bagian sebelumnya.
Batasan
- Container kustom Triton tidak kompatibel dengan Vertex Explainable AI atau Vertex AI Model Monitoring.
Langkah selanjutnya
- Lihat tutorial Notebook Vertex AI Jupyter untuk pola deployment dengan server inferensi NVIDIA Triton di Vertex AI Prediction.