Ce guide du débutant est une introduction à l'obtention de prédictions à partir de modèles personnalisés sur Vertex AI.
Objectifs de la formation
Niveau d'expérience sur Vertex AI : débutant
Durée de lecture estimée : 15 minutes
Objectifs d'apprentissage :
- Avantages de l'utilisation d'un service de prédiction géré.
- Fonctionnement des prédictions par lot dans Vertex AI.
- Fonctionnement des prédictions en ligne dans Vertex AI
Pourquoi utiliser un service de prédiction géré ?
Imaginez que vous ayez pour tâche de créer un modèle prenant en entrée l'image d'une plante afin de prédire l'espèce. Vous pouvez commencer par entraîner un modèle dans un notebook, en testant différents hyperparamètres et architectures. Lorsque vous disposez d'un modèle entraîné, vous pouvez appeler la méthode predict dans le framework de ML de votre choix et tester la qualité du modèle.
Ce workflow est idéal pour les tests, mais lorsque vous souhaitez utiliser le modèle pour obtenir des prédictions sur de nombreuses données ou pour obtenir des prédictions à faible latence à la volée, vous avez besoin de plus qu'un notebook. Supposons, par exemple, que vous essayiez de mesurer la diversité d'un écosystème spécifique et que, plutôt que de demander à des humains d'identifier et de compter manuellement des espèces végétales en milieu naturel, vous souhaitez utiliser ce modèle de ML pour classer de grands lots d'images. Si vous utilisez un notebook, vous pouvez rencontrer des contraintes de mémoire. En outre, l'obtention de prédictions pour toutes ces données est susceptible d'être une tâche de longue durée qui peut expirer dans votre notebook.
Imaginons que vous souhaitiez utiliser ce modèle dans une application où les utilisateurs peuvent importer des images de plantes et les identifier immédiatement. Vous aurez besoin d'un emplacement pour héberger le modèle qui se trouve en dehors d'un notebook que votre application peut appeler pour réaliser une prédiction. De plus, il est peu probable que votre trafic soit cohérent vers votre modèle. Vous aurez donc besoin d'un service capable de s'adapter en cas de besoin.
Dans tous ces cas, un service de prédiction géré permet de fluidifier l'hébergement et l'utilisation de vos modèles de ML. Ce guide explique comment obtenir des prédictions à partir de modèles de ML sur Vertex AI. Notez qu'il existe d'autres personnalisations, fonctionnalités et méthodes d'interface avec le service qui ne sont pas abordées ici. L'objectif de ce guide est de fournir une vue d'ensemble. Pour en savoir plus, consultez la documentation sur les prédictions Vertex AI.
Présentation du service de prédiction géré
Vertex AI est compatible avec les prédictions par lot et en ligne.
La prédiction par lot est une requête asynchrone. Elle est particulièrement adaptée lorsque vous n'avez pas besoin d'une réponse immédiate et que vous souhaitez traiter des données accumulées dans une seule requête. Dans l'exemple abordé dans l'introduction, il s'agit du cas d'utilisation de la biodiversité.
Si vous souhaitez obtenir des prédictions à faible latence à partir de données transmises à votre modèle à la volée, vous pouvez utiliser la prédiction en ligne. Dans l'exemple présenté dans l'introduction, il s'agit du cas d'utilisation dans lequel vous souhaitez intégrer votre modèle dans une application qui aide les utilisateurs à identifier immédiatement les espèces végétales.
Importer un modèle dans Vertex AI Model Registry
Pour utiliser le service de prédiction, la première étape consiste à importer votre modèle de ML entraîné dans Vertex AI Model Registry. Il s'agit d'un registre dans lequel vous pouvez gérer le cycle de vie de vos modèles.
Créer une ressource de modèle
Lorsque vous entraînez des modèles à l'aide du service d'entraînement personnalisé Vertex AI, vous pouvez faire en sorte que votre modèle soit automatiquement importé dans le registre une fois le job d'entraînement terminé. Si vous avez ignoré cette étape ou entraîné votre modèle en dehors de Vertex AI, vous pouvez l'importer manuellement via la console Google Cloud ou le SDK Vertex AI pour Python en pointant vers un emplacement Cloud Storage contenant vos artefacts de modèle enregistrés. Le format de ces artefacts de modèle peut être savedmodel.pb, model.joblib, model.pkl, etc., suivant le framework de ML que vous utilisez.
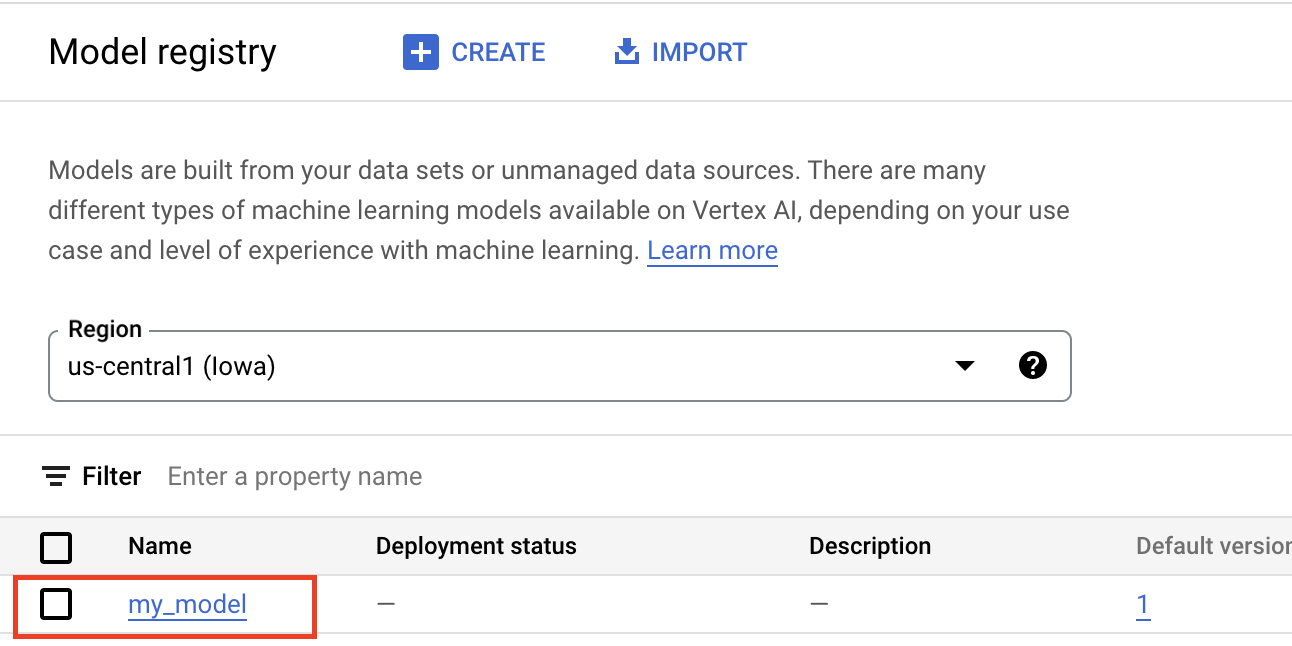
L'importation d'artefacts dans Vertex AI Model Registry crée une ressource Model, visible dans la console Google Cloud comme illustré ci-dessous.
Sélectionner un conteneur
Lorsque vous importez un modèle dans Vertex AI Model Registry, vous devez l'associer à un conteneur pour que Vertex AI diffuse les requêtes de prédiction.
Conteneurs prédéfinis
Vertex AI fournit des conteneurs prédéfinis que vous pouvez utiliser pour les prédictions. Les conteneurs prédéfinis sont organisés par framework de ML et par version de framework, et fournissent des serveurs de prédiction HTTP que vous pouvez utiliser pour diffuser des prédictions avec une configuration minimale. Ils n'effectuent que l'opération de prédiction du framework de machine learning, donc si vous devez prétraiter vos données, vous devez le faire avant de lancer la requête de prédiction. De même, tout post-traitement doit se produire après l'exécution de la requête de prédiction. Pour obtenir un exemple d'utilisation d'un conteneur prédéfini, consultez le notebook Diffuser des modèles d'image PyTorch avec des conteneurs prédéfinis sur Vertex AI.
Conteneurs personnalisés
Si votre cas d'utilisation nécessite des bibliothèques qui ne sont pas incluses dans les conteneurs prédéfinis ou si vous souhaitez effectuer des transformations de données personnalisées dans le cadre de la requête de prédiction, vous pouvez utiliser un conteneur personnalisé que vous créez et transférez vers Artifact Registry. Bien que les conteneurs personnalisés permettent une plus grande personnalisation, ils doivent exécuter un serveur HTTP. Plus précisément, le conteneur doit écouter les vérifications de l'activité, les vérifications de l'état et les requêtes de prédiction, et y répondre. Dans la plupart des cas, si elle est possible, l'utilisation d'un conteneur prédéfini est l'option recommandée et la plus simple. Pour obtenir un exemple d'utilisation d'un conteneur personnalisé, consultez le notebook Classification d'image PyTorch sur un seul GPU à l'aide de Vertex Training avec un conteneur personnalisé.
Routines de prédiction personnalisées
Si votre cas d'utilisation nécessite des transformations personnalisées de pré et post-traitement, et que vous ne souhaitez pas avoir à créer ni à gérer de conteneur personnalisé, vous pouvez utiliser les routines de prédiction personnalisées. Les routines de prédiction personnalisées vous permettent de fournir vos transformations de données sous forme de code Python. En arrière-plan, le SDK Vertex AI pour Python crée un conteneur personnalisé que vous pouvez tester localement et déployer sur Vertex AI. Pour obtenir un exemple d'utilisation des routines de prédiction personnalisées, consultez le notebook Routines de prédiction personnalisées avec Sklearn.
Obtenir des prédictions par lot
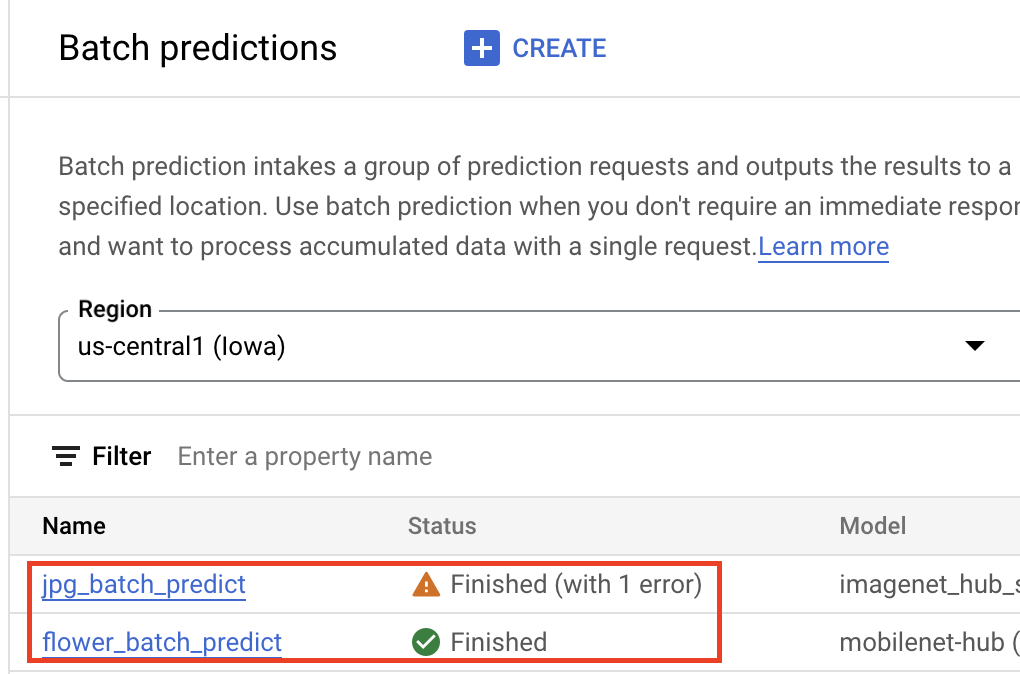
Une fois que votre modèle est dans Vertex AI Model Registry, vous pouvez envoyer une tâche de prédiction par lot à partir de la console Google Cloud ou du SDK Vertex AI pour Python. Vous devrez spécifier l'emplacement des données sources, ainsi que l'emplacement dans Cloud Storage ou BigQuery dans lequel vous souhaitez enregistrer les résultats. Vous pouvez également spécifier le type de machine sur lequel vous souhaitez exécuter cette tâche, ainsi que les accélérateurs facultatifs. Comme le service de prédiction est entièrement géré, Vertex AI provisionne automatiquement les ressources de calcul, effectue la tâche de prédiction et assure la suppression des ressources de calcul une fois la tâche de prédiction terminée. Vous pouvez suivre l'état de vos tâches de prédiction par lot dans la console Google Cloud.
Obtenir des prédictions en ligne
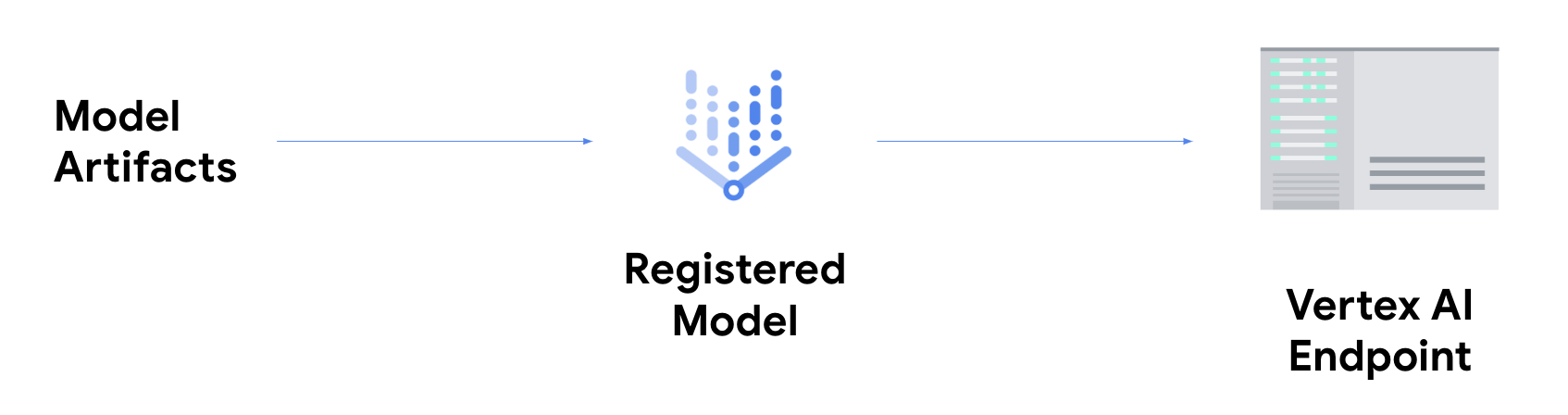
Si vous souhaitez obtenir des prédictions en ligne, vous devez effectuer l'étape supplémentaire de déploiement de votre modèle sur un point de terminaison Vertex AI.
Cette opération permet d'associer les artefacts de modèle aux ressources physiques pour une diffusion à faible latence et de créer une ressource DeployedModel.
Une fois le modèle déployé sur un point de terminaison, il accepte les requêtes comme n'importe quel autre point de terminaison REST, ce qui signifie que vous pouvez l'appeler depuis une fonction Cloud, un chatbot, une application Web, etc. Vous pouvez déployer plusieurs modèles sur un seul point de terminaison et répartir le trafic entre eux. Cette fonctionnalité est utile si vous souhaitez par exemple déployer une nouvelle version de modèle mais que vous ne souhaitez pas diriger immédiatement l'ensemble du trafic vers le nouveau modèle. Vous pouvez également déployer le même modèle sur plusieurs objets.
Ressources pour obtenir des prédictions à partir de modèles personnalisés sur Vertex AI
Pour en savoir plus sur l'hébergement et la diffusion de modèles sur Vertex AI, consultez les ressources suivantes ou reportez-vous au dépôt GitHub des exemples Vertex AI.
- Vidéo Obtenir des prédictions
- Entraîner et diffuser un modèle TensorFlow à l'aide d'un conteneur prédéfini
- Diffuser des modèles d'image PyTorch avec des conteneurs prédéfinis sur Vertex AI
- Diffuser un modèle de diffusion stable à l'aide d'un conteneur prédéfini
- Routines de prédiction personnalisées avec Sklearn