この初心者向けガイドでは、Vertex AI のカスタムモデルから予測を取得する方法の概要を説明します。
学習目標
Vertex AI の経験レベル: 初級
推定所要時間: 15 分
学習内容:
- マネージド予測サービスを使用するメリット。
- Vertex AI でのバッチ予測の仕組み。
- Vertex AI でのオンライン予測の仕組み。
マネージド予測サービスを使用する理由
植物の画像を入力として受け取り、種を予測するモデルの作成を任されたとします。まず、ノートブックでモデルをトレーニングして、さまざまなハイパーパラメータとアーキテクチャを試すことから始めるでしょう。トレーニング済みのモデルがある場合は、任意の ML フレームワークで predict メソッドを呼び出して、モデルの品質をテストできます。
このワークフローはテストには適していますが、モデルを使用して大量のデータに対する予測を取得したり、低レイテンシの予測をその場で取得したりするには、ノートブック以上のものが必要になります。たとえば、特定の生態系の生物多様性を測定しようとしている場合に、人間が野生の植物種を手作業で識別して数えるのではなく、この ML モデルを使用して大量の画像を分類するとします。ノートブックを使用している場合、メモリ不足が発生する可能性があります。さらに、そのすべてのデータに対する予測の取得は長時間実行ジョブになり、ノートブックでタイムアウトになる可能性があります。
また、植物の画像をアップロードしてすぐに識別させることができるアプリケーションでこのモデルを使用する場合はどうでしょうか。アプリケーションが予測のために呼び出すことができる、ノートブックの外に存在するモデルをホストする場所が必要です。また、モデルへのトラフィックが一定である可能性は低いため、必要に応じて自動スケーリングできるサービスが必要になります。
これらすべてのケースで、マネージド予測サービスを使用すれば、ML モデルをホストおよび使用する際の困難が軽減されます。このガイドでは、Vertex AI で ML モデルから予測を取得する方法の概要を説明します。なお、ここでは説明しきれないカスタマイズや機能、サービスとやり取りする方法があります。このガイドは、概要の説明を目的としています。詳細については、Vertex AI Predictions のドキュメントをご覧ください。
マネージド予測サービスの概要
Vertex AI は、バッチ予測とオンライン予測をサポートしています。
バッチ予測は非同期リクエストです。これは、即時のレスポンスが必要なく、累積されたデータを 1 回のリクエストで処理する場合に適しています。冒頭に説明した例では、これは生物多様性の特徴付けのユースケースになります。
モデルに渡されたデータから低レイテンシの予測をその場で取得する場合は、オンライン予測を使用できます。冒頭に説明した例では、これは、植物の種類をすぐに識別できるようにモデルをアプリに埋め込むというユースケースになります。
Vertex AI Model Registry にモデルをアップロードする
予測サービスを使用するには、まず、トレーニング済みの ML モデルを Vertex AI Model Registry にアップロードします。これは、モデルのライフサイクルを管理できるレジストリです。
モデルリソースの作成
Vertex AI カスタム トレーニング サービスを使用してモデルをトレーニングする場合は、トレーニング ジョブの完了後にモデルをレジストリに自動的にインポートできます。この手順をスキップした場合、または Vertex AI の外部でモデルをトレーニングした場合は、Google Cloud コンソールまたは Vertex AI SDK for Python を使用して、保存したモデル アーティファクトを含む Cloud Storage の場所を指すようにして手動でアップロードできます。これらのモデル アーティファクトの形式は、使用している ML フレームワークに応じて savedmodel.pb、model.joblib、model.pkl などになります。
アーティファクトを Vertex AI Model Registry にアップロードすると、Model リソースが作成されて、以下のように Google Cloud コンソールに表示されます。
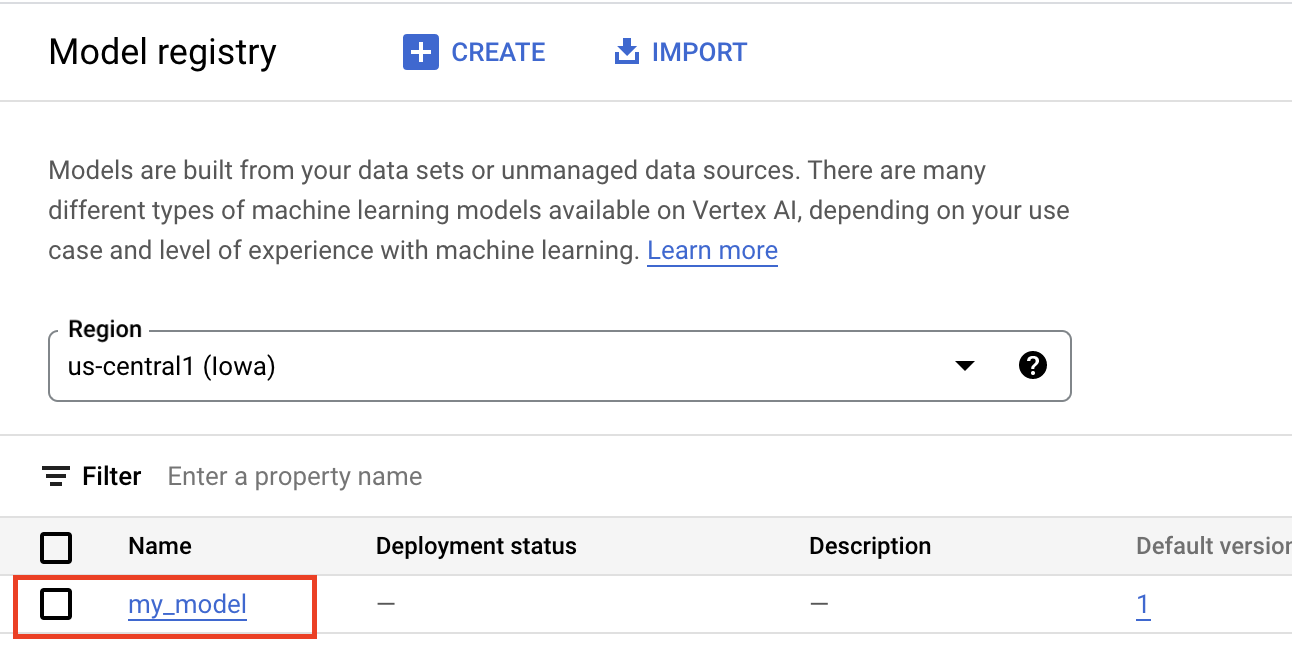
コンテナの選択
Vertex AI Model Registry にモデルをインポートするときは、Vertex AI が予測リクエストを処理できるように、モデルをコンテナに関連付ける必要があります。
ビルド済みコンテナ
Vertex AI には、予測に使用できるビルド済みコンテナが用意されています。ビルド済みコンテナは ML フレームワークとフレームワーク バージョン別に整理されており、最小限の構成で予測を行うために使用できる HTTP 予測サーバーを提供します。ML フレームワークの予測オペレーションのみを実行するため、データの前処理が必要な場合は、予測リクエストの実行前に行う必要があります。同様に、予測リクエストの実行後に後処理を行う必要があります。ビルド済みコンテナの使用例については、ノートブック Vertex AI でビルド済みコンテナを使用して PyTorch 画像モデルを提供するをご覧ください。
カスタム コンテナ
ユースケースに、ビルド済みコンテナに含まれていないライブラリが必要な場合や、カスタムデータ変換を予測リクエストの一部として実行する場合は、カスタム コンテナを使用でき、それをビルドして Artifact Registry に push します。カスタム コンテナでは柔軟なカスタマイズが可能ですが、このコンテナでは HTTP サーバーを実行する必要があります。具体的には、コンテナで実行チェック、ヘルスチェック、予測リクエストをリッスンして、これらに応答する必要があります。ほとんどの場合、可能であればビルド済みコンテナを使用することが、より簡単でおすすめのオプションです。カスタム コンテナの使用例については、ノートブック Vertex Training とカスタム コンテナを使用した単一 GPU での PyTorch 画像分類をご覧ください。
カスタム予測ルーチン
ユースケースでカスタム前処理と後処理の変換が必要で、カスタム コンテナの構築と維持のオーバーヘッドを回避する必要がある場合は、カスタム予測ルーチンを使用できます。カスタム予測ルーチンを使用することで、データ変換を Python コードとして提供できます。バックグラウンドでは、ローカルでテストして Vertex AI にデプロイできるカスタム コンテナが Vertex AI SDK for Python によって構築されます。カスタム予測ルーチンの使用例については、ノートブック Sklearn を使用したカスタム予測ルーチンをご覧ください。
バッチ予測を取得する
モデルが Vertex AI Model Registry に追加されたら、Google Cloud コンソールまたは Vertex AI SDK for Python からバッチ予測ジョブを送信できます。ソースデータのロケーションと、結果を保存する Cloud Storage または BigQuery 内のロケーションを指定します。このジョブを実行するマシンタイプと、オプションのアクセラレータを指定することもできます。予測サービスはフルマネージドであるため、Vertex AI が自動的にコンピューティング リソースをプロビジョニングし、予測タスクを実行して、予測ジョブが終了したらコンピューティング リソースを削除します。バッチ予測ジョブのステータスは、Google Cloud コンソールで追跡できます。
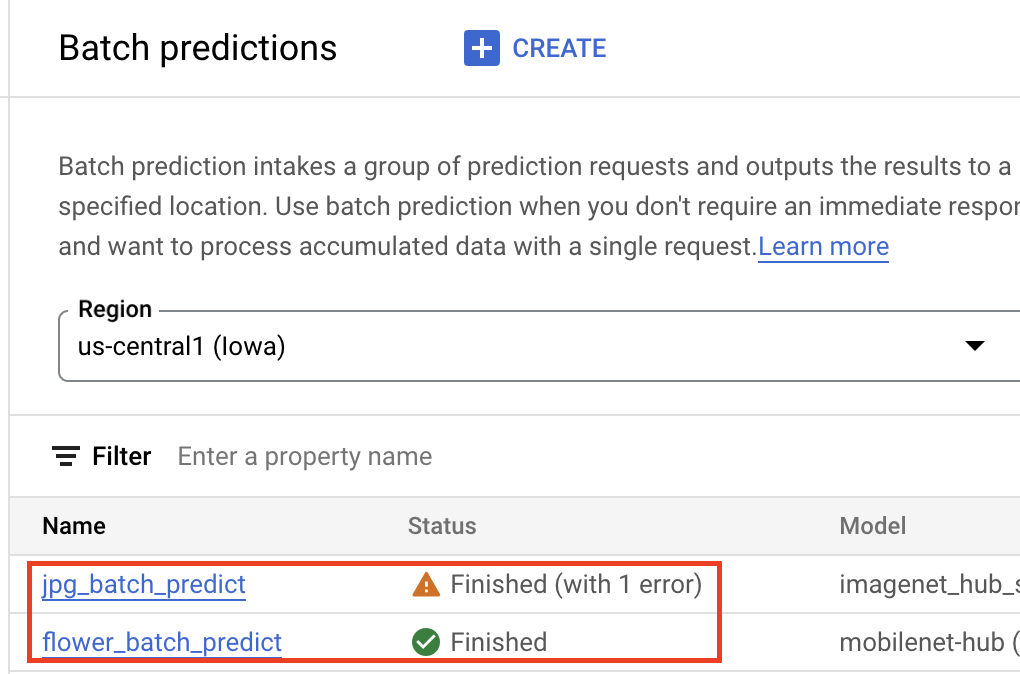
オンライン予測を取得する
オンライン予測を取得するには、追加の手順として、Vertex AI エンドポイントにモデルをデプロイする必要があります。これにより、低レイテンシでのサービングのためにモデル アーティファクトが物理リソースに関連付けられ、DeployedModel リソースが作成されます。
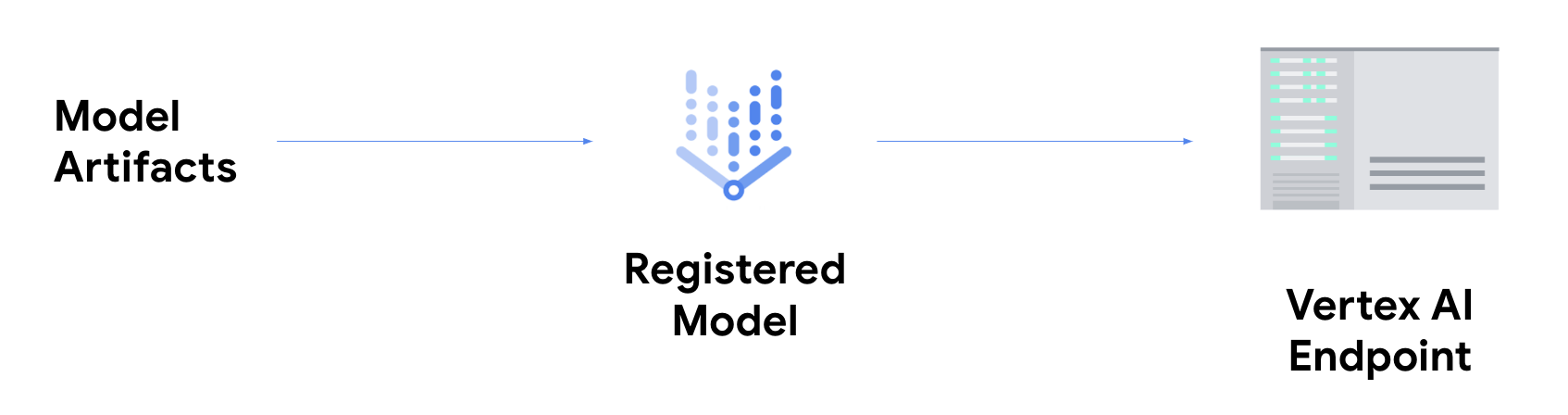
エンドポイントにデプロイされたモデルは、他の REST エンドポイントと同様にリクエストを受け入れます。つまり、Cloud Functions の関数、chatbot、ウェブアプリなどからモデルを呼び出すことができます。なお、1 つのエンドポイントに複数のモデルをデプロイして、モデル間でトラフィックを分割することができます。この機能は、たとえば、新しいモデル バージョンをロールアウトするが、すべてのトラフィックを新しいモデルにすぐに転送したくない場合に便利です。また、同じモデルを複数のエンドポイントにデプロイすることもできます。
Vertex AI でのカスタムモデルからの予測の取得に関するリソース
Vertex AI でのモデルのホスティングとサービングの詳細については、次のリソースまたは Vertex AI のサンプル GitHub リポジトリをご覧ください。
- 予測の取得に関する動画
- ビルド済みコンテナを使用して TensorFlow モデルをトレーニングして提供する
- Vertex AI でビルド済みコンテナを使用して PyTorch モデルを提供する
- ビルド済みコンテナを使用して Stable Diffusion モデルを提供する
- Sklearn によるカスタム予測ルーチン