此新手指南介绍了如何通过 Vertex AI 上的自定义模型进行预测。
学习目标
Vertex AI 体验级别:新手
预计阅读时间:15 分钟
您将学到的内容:
- 使用代管式预测服务的优势。
- 批量预测在 Vertex AI 中的工作原理。
- 在线预测在 Vertex AI 中的工作原理。
为何使用代管式预测服务?
假设您的任务是创建一个模型,该模型将植物图片作为输入并预测物种。您可以先在笔记本中训练模型,尝试不同的超参数和架构。如果您拥有经过训练的模型,可以在所选的机器学习框架中调用 predict 方法并测试模型质量。
此工作流非常适合实验,但如果您想使用模型基于大量数据进行预测,或即时进行低延迟预测,则需要的不仅仅是笔记本。例如,假设您正在尝试衡量特定生态系统的生物多样性,但不希望通过人工手动识别和计算野外的植物物种,而是使用此机器学习模型对大批量图片进行分类。如果您使用的是笔记本,则可能会遇到内存限制。此外,针对上述所有数据获得预测可能是一项长期作业,在笔记本中可能会超时。
或者,如果您想在用户可以上传植物图片并立即识别它们的应用中使用此模型,那又该怎么办?您需要一些地方来托管笔记本之外的模型,应用可以调用该模型进行预测。此外,进入模型的流量不太可能始终如一,因此您需要一个可以在必要时自动扩缩的服务。
在所有上述情况下,代管式预测服务将减少托管和使用机器学习模型的麻烦。本指南介绍如何通过 Vertex AI 上的机器学习模型进行预测。请注意,还有其他一些自定义设置、功能以及与此处未涵盖的服务建立连接的方法。本指南仅提供相关概览。如需了解详情,请参阅 Vertex AI 预测文档。
代管式预测服务概览
Vertex AI 支持批量预测和在线预测。
批量预测是异步请求。如果您不需要立即响应并且希望通过一个请求处理累积数据,可以选择此选项。在上面介绍的示例中,这将对应典型的生物多样性应用场景。
如果您想通过传递给模型的数据即时进行低延迟预测,则可以使用在线预测。在上面介绍的示例中,该选项对应的应用场景是将模型嵌入应用中,帮助用户立即识别植物种类。
将模型上传到 Vertex AI Model Registry
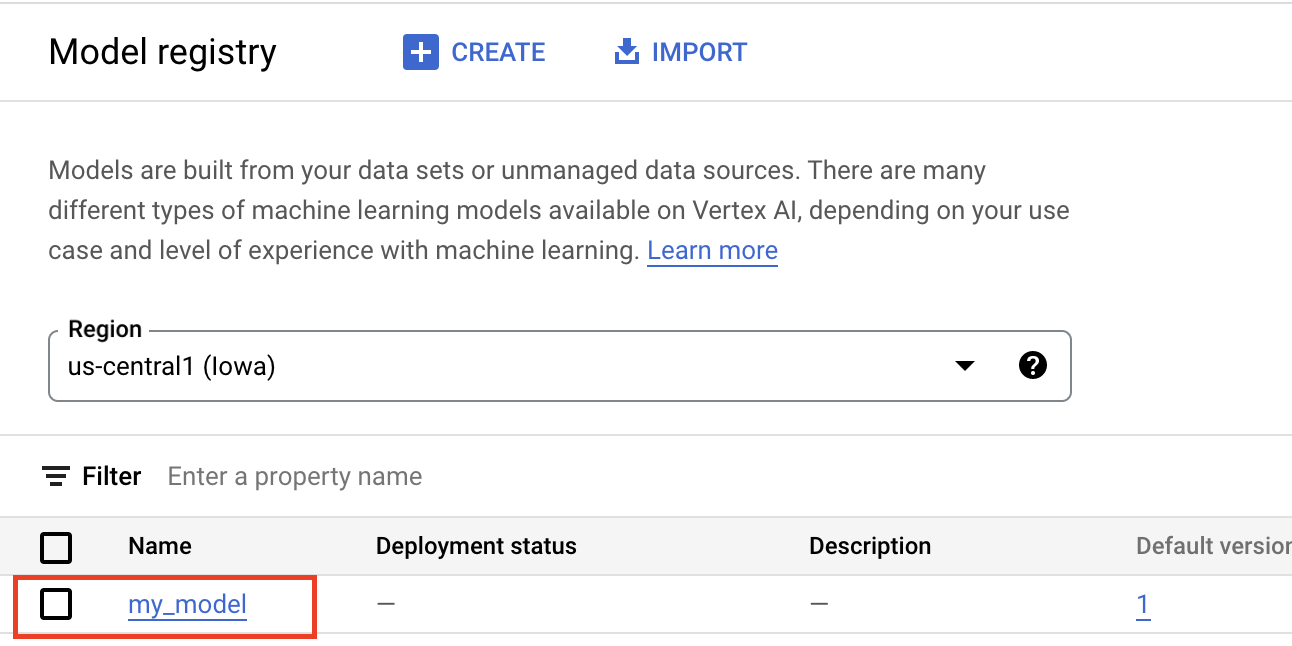
如需使用预测服务,第一步是将经过训练的机器学习模型上传到 Vertex AI Model Registry。这是一个注册表,您可以在其中管理模型的生命周期。
创建模型资源
使用 Vertex AI 自定义训练服务训练模型时,您可以在训练作业完成后将模型自动导入注册表。如果您跳过了该步骤,或者在 Vertex AI 之外训练了模型,则可以指向包含已保存的模型工件的 Cloud Storage 位置,通过 Google Cloud 控制台或 Python 版 Vertex AI SDK 手动上传该模型。这些模型工件的格式可以是 savedmodel.pb、model.joblib、model.pkl 等,具体取决于您使用的机器学习框架。
将工件上传到 Vertex AI Model Registry 会创建 Model 资源,这些资源在 Google Cloud 控制台中可见,如下所示。
选择容器
将模型导入 Vertex AI Model Registry 时,您需要将它与 Vertex AI 的容器关联以处理预测请求。
预构建容器
Vertex AI 提供了可用于预测的预构建容器。预构建容器按机器学习框架和框架版本进行组织,并提供 HTTP 预测服务器,您可以使用这些服务器以最少的配置执行预测。由于它们仅执行机器学习框架的预测操作,因此如果您需要预处理数据,则必须在发出预测请求之前进行。同样,任何后处理都必须在执行预测请求后进行。如需查看预构建容器的使用示例,请参阅笔记本在 Vertex AI 上使用预构建容器提供 PyTorch 映像模型
自定义容器
如果您的使用场景需要的库未包含在预构建容器中,或者您可能需要在预测请求中执行自定义数据转换,则可以使用您构建的自定义容器并将其推送到 Artifact Registry。虽然自定义容器允许进行更多自定义操作,但该容器必须运行一个 HTTP 服务器。具体而言,容器必须监听并响应活跃性检查、健康检查和预测请求。在大多数情况下,建议尽可能使用预构建容器,这种方法更简单。如需查看自定义容器的使用示例,请参阅笔记本将 Vertex Training 与自定义容器搭配使用的 PyTorch 图片分类单 GPU
自定义预测例程
如果您的使用场景确实需要自定义预处理和后处理转换,并且您不想要产生构建和维护自定义容器的开销,则可以使用自定义预测例程。 借助自定义预测例程,您可以以 Python 代码的形式提供数据转换,而 Python 版 Vertex AI SDK 将在后台构建一个自定义容器,您可以在本地测试该容器并将其部署到 Vertex AI。 如需查看自定义预测例程的使用示例,请参阅笔记本Sklearn 的自定义预测例程
进行批量预测
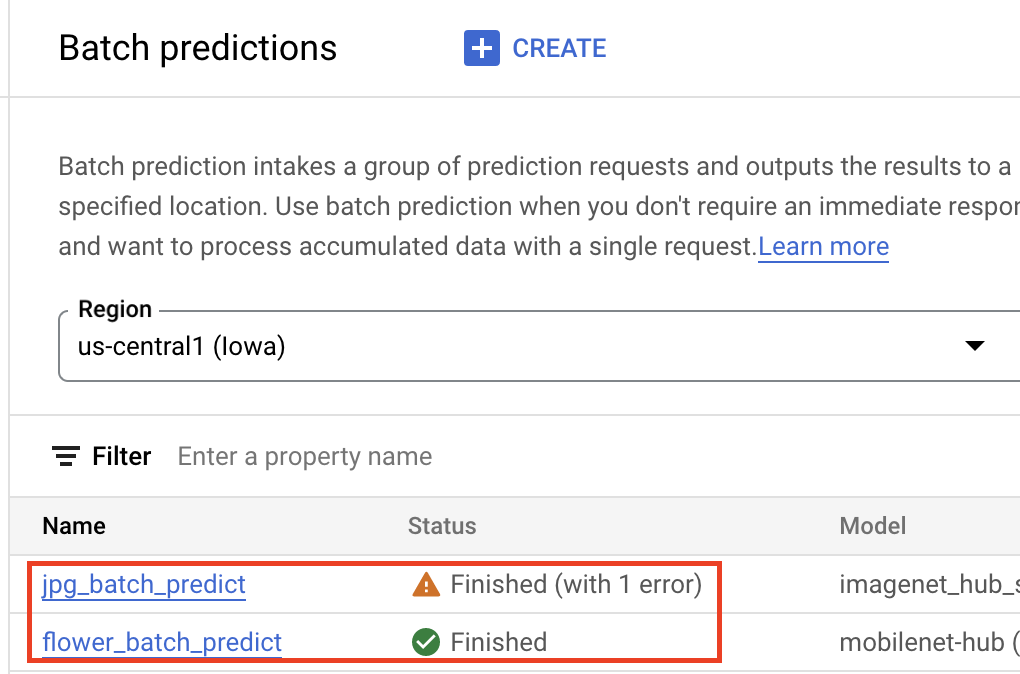
您的模型进入 Vertex AI Model Registry 后,您可以从 Google Cloud 控制台或 Python 版 Vertex AI SDK 提交批量预测作业。您将指定源数据的位置,以及 Cloud Storage 或 BigQuery 中您希望保存结果的位置。您还可以指定要运行此作业的机器类型,以及任何可选的加速器。由于预测服务是全代管式的,因此 Vertex AI 自动预配了计算资源、执行预测任务,并确保在预测作业完成后删除计算资源。您可以在 Google Cloud 控制台中跟踪批量预测作业的状态。
进行在线预测
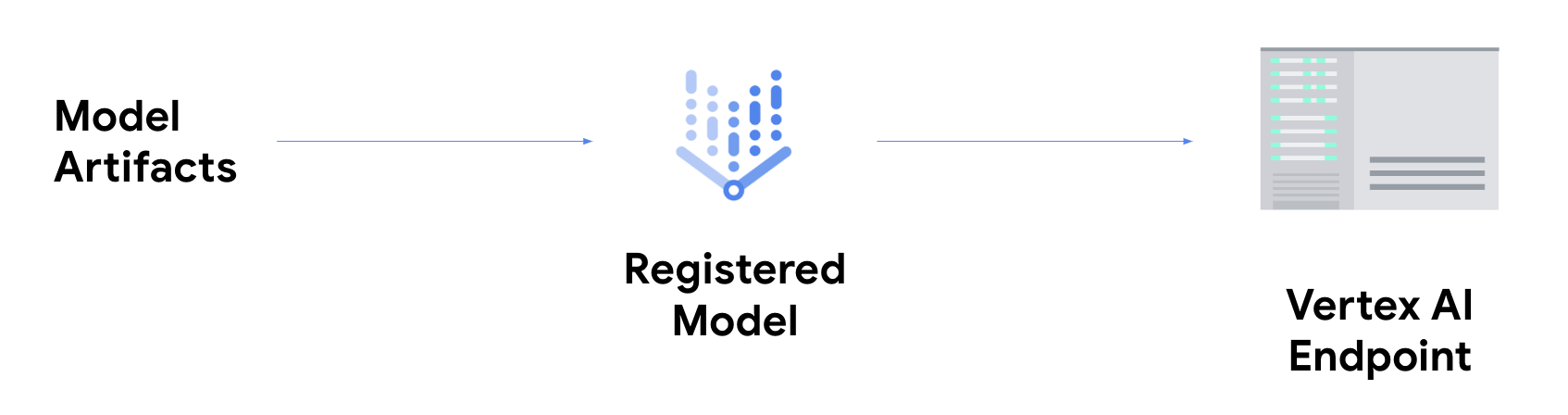
如果您想进行在线预测,则需要执行额外的步骤,将模型部署到 Vertex AI 端点。
这会将模型工件与物理资源相关联以实现低延迟响应,并创建一个 DeployedModel 资源。
模型部署到端点后,它会像任何其他 REST 端点一样接受请求,这意味着您可以从 Cloud Functions、聊天机器人、Web 应用等调用该模型。请注意,您可以将多个模型部署到单个端点,以在这些模型之间拆分流量。此功能在某些情况下非常有用,例如,如果您想要发布新的模型版本,但不想立即将所有流量定向到新模型。您还可以将同一模型部署到多个端点。
有关通过 Vertex AI 上的自定义模型进行预测的资源
如需详细了解如何在 Vertex AI 上托管和提供模型,请参阅以下资源或参阅 Vertex AI 示例 GitHub 代码库。
- “进行预测”视频
- 使用预构建容器训练和提供 TensorFlow 模型
- 在 Vertex AI 上使用预构建容器提供 PyTorch 映像模型
- 使用预构建容器提供稳定的扩散模型
- Sklearn 的自定义预测例程