Dieser Leitfaden für Einsteiger ist eine Einführung in das benutzerdefinierte Training in Vertex AI. Benutzerdefiniertes Training bezieht sich auf das Trainieren eines Modells mit einem ML-Framework wie TensorFlow, PyTorch oder XGBoost.
Lernziele
Vertex AI-Erfahrungsstufe: Einsteiger
Geschätzte Lesezeit: 15 Minuten
Lerninhalte:
- Vorteile des verwalteten Dienstes für das benutzerdefinierte Training
- Best Practices für das Verpacken von Trainingscode
- Trainingsjob senden und beobachten
Vorteile eines verwalteten Trainingsdienstes
Stellen Sie sich vor, Sie arbeiten an einem neuen ML-Problem. Sie öffnen ein Notebook, importieren Ihre Daten und führen Tests durch. In diesem Szenario erstellen Sie ein Modell mit dem ML-Framework Ihrer Wahl und führen Notebook-Zellen aus, um eine Trainingsschleife auszuführen. Wenn das Training abgeschlossen ist, bewerten Sie die Ergebnisse Ihres Modells, nehmen Änderungen vor und führen das Training dann noch einmal aus. Dieser Workflow ist nützlich für Experimente. Wenn Sie jedoch anfangen, Produktionsanwendungen mit ML zu erstellen, stellen Sie möglicherweise fest, dass die manuelle Ausführung der Zellen Ihres Notebooks nicht die praktischste Option ist.
Beispiel: Wenn Ihr Dataset und Ihr Modell groß sind, sollten Sie das verteilte Training testen. In einer Produktionsumgebung ist es außerdem unwahrscheinlich, dass Sie Ihr Modell nur einmal trainieren müssen. Im Laufe der Zeit trainieren Sie Ihr Modell neu, um sicherzustellen, dass es aktuell bleibt und wertvolle Ergebnisse liefert. Wenn Sie umfangreiche Tests automatisieren oder Modelle für eine Produktionsanwendung neu trainieren möchten, vereinfacht die Verwendung eines verwalteten ML-Trainingsdienstes Ihre Workflows.
Diese Anleitung bietet eine Einführung in das Training benutzerdefinierter Modelle in Vertex AI. Da der Trainingsdienst vollständig verwaltet ist, stellt Vertex AI automatisch Rechenressourcen bereit, führt die Trainingsaufgabe aus und sorgt für das Löschen von Rechenressourcen, sobald der Trainingsjob abgeschlossen ist. Beachten Sie, dass es zusätzliche Anpassungen, Funktionen und Möglichkeiten zur Nutzung des Dienstes gibt, die hier nicht behandelt werden. Dieser Leitfaden bietet einen Überblick. Weitere Informationen finden Sie in der Dokumentation zu Vertex AI Training.
Benutzerdefiniertes Training – Übersicht
Das Training benutzerdefinierter Modelle in Vertex AI folgt diesem Standardworkflow:
Verpacken Sie den Trainingsanwendungscode.
Konfigurieren und senden Sie einen benutzerdefinierten Trainingsjob.
Benutzerdefinierten Trainingsjob überwachen.
Paket für Trainingsanwendung erstellen
Das Ausführen eines benutzerdefinierten Trainingsjobs auf Vertex AI erfolgt mit Containern. Container sind Pakete Ihres Anwendungscodes, in diesem Fall Ihr Trainingscode, zusammen mit Abhängigkeiten wie bestimmten Bibliothekenversionen, die zum Ausführen des Codes erforderlich sind. Neben der Unterstützung durch das Abhängigkeitsmanagement können Container praktisch überall ausgeführt werden, was eine erhöhte Portabilität ermöglicht. Das Packen Ihres Trainingscodes mit Parametern und Abhängigkeiten in einen Container, um eine portable Komponente zu erstellen, ist ein wichtiger Schritt beim Verschieben Ihrer ML-Anwendungen von Protoype in die Produktion.
Bevor Sie einen benutzerdefinierten Trainingsjob starten können, müssen Sie ein Paket für Ihre Trainingsanwendung erstellen. Eine Trainingsanwendung bezieht sich in diesem Fall auf eine oder mehrere Dateien, die Aufgaben wie das Laden von Daten, das Vorverarbeiten von Daten, das Definieren eines Modells und das Ausführen einer Trainingsschleife ausführen. Der Vertex AI-Trainingsdienst führt den von Ihnen bereitgestellten Code aus. Es liegt ganz bei Ihnen, welche Schritte Sie in Ihrer Trainingsanwendung verwenden.
Vertex AI bietet vordefinierte Container für TensorFlow, PyTorch, XGBoost und Scikit-learn. Diese Container werden regelmäßig aktualisiert und enthalten möglicherweise gängige Bibliotheken im Trainingscode. Sie können Ihren Trainingscode mit einem dieser Container ausführen oder einen benutzerdefinierten Container erstellen, in dem der Trainingscode und die Abhängigkeiten vorinstalliert sind.
Es gibt drei Optionen zum Verpacken Ihres Codes in Vertex AI:
- Senden Sie eine einzelne Python-Datei.
- Erstellen Sie eine Python-Quelldistribution.
- Verwenden Sie benutzerdefinierte Container.
Python-Datei
Diese Option eignet sich für schnelle Tests. Sie können diese Option verwenden, wenn sich der gesamte Code, der zum Ausführen Ihrer Trainingsanwendung erforderlich ist, in einer Python-Datei befindet und einer der vordefinierten Vertex AI-Trainingscontainer alle erforderlichen Bibliotheken zum Ausführen Ihrer Anwendung hat. Ein Beispiel für das Verpacken Ihrer Trainingsanwendung als einzelne Python-Datei finden Sie in der Notebook-Anleitung Benutzerdefiniertes Training und Batchvorhersage.
Python-Quelldistribution
Sie können eine Python-Quelldistribution erstellen, die Ihre Trainingsanwendung enthält. Sie speichern die Quelldistribution mit dem Trainingscode und den Abhängigkeiten in einem Cloud Storage-Bucket. Ein Beispiel für das Verpacken Ihrer Trainingsanwendung als Python-Quelldistribution finden Sie in der Notebook-Anleitung Training, Feinabstimmung und Bereitstellung eines PyTorch-Klassifizierungsmodells.
Benutzerdefinierter Container
Diese Option ist nützlich, wenn Sie mehr Kontrolle über Ihre Anwendung haben oder Code ausführen möchten, der nicht in Python geschrieben wurde. In diesem Fall müssen Sie ein Dockerfile schreiben, Ihr benutzerdefiniertes Image erstellen und es in Artifact Registry übertragen. Ein Beispiel für die Containerisierung Ihrer Trainingsanwendung finden Sie in der Notebook-Anleitung Leistung des Profilmodelltrainings mit Profiler bestimmen.
Empfohlene Struktur für Trainingsanwendungen
Wenn Sie Ihren Code als Python-Quelldistribution oder als benutzerdefinierten Container verpacken, wird empfohlen, Ihre Anwendung so zu strukturieren:
training-application-dir/
....setup.py
....Dockerfile
trainer/
....task.py
....model.py
....utils.py
Erstellen Sie ein Verzeichnis zum Speichern Ihres gesamten Trainingsanwendungscodes, in diesem Fall training-application-dir. Dieses Verzeichnis enthält die Datei setup.py, wenn Sie eine Python-Quelldistribution verwenden, oder eine Dockerfile-Datei, wenn Sie einen benutzerdefinierten Container verwenden.
In beiden Szenarien enthält dieses übergeordnete Verzeichnis auch ein Unterverzeichnis trainer, das den gesamten Code zum Ausführen des Trainings enthält. Innerhalb von trainer ist task.py der Haupteinstiegspunkt Ihrer Anwendung. Diese Datei führt das Modelltraining aus. Sie können Ihren gesamten Code in diese Datei einfügen, aber bei Produktionsanwendungen werden Sie wahrscheinlich noch weitere Dateien haben, zum Beispiel model.py, data.py und utils.py um nur einige zu nennen.
Benutzerdefiniertes Training ausführen
Trainingsjobs in Vertex AI stellen automatisch Rechenressourcen bereit, führen den Trainingsanwendungscode aus und sorgen für das Löschen von Rechenressourcen, sobald der Trainingsjob abgeschlossen ist.
Wenn Sie komplexere Workflows erstellen, werden Sie Ihre Trainingsjobs wahrscheinlich mit dem Vertex AI SDK for Python konfigurieren, senden und überwachen. Wenn Sie einen benutzerdefinierten Trainingsjob zum ersten Mal ausführen, ist es jedoch möglicherweise einfacher, die Google Cloud Console zu verwenden.
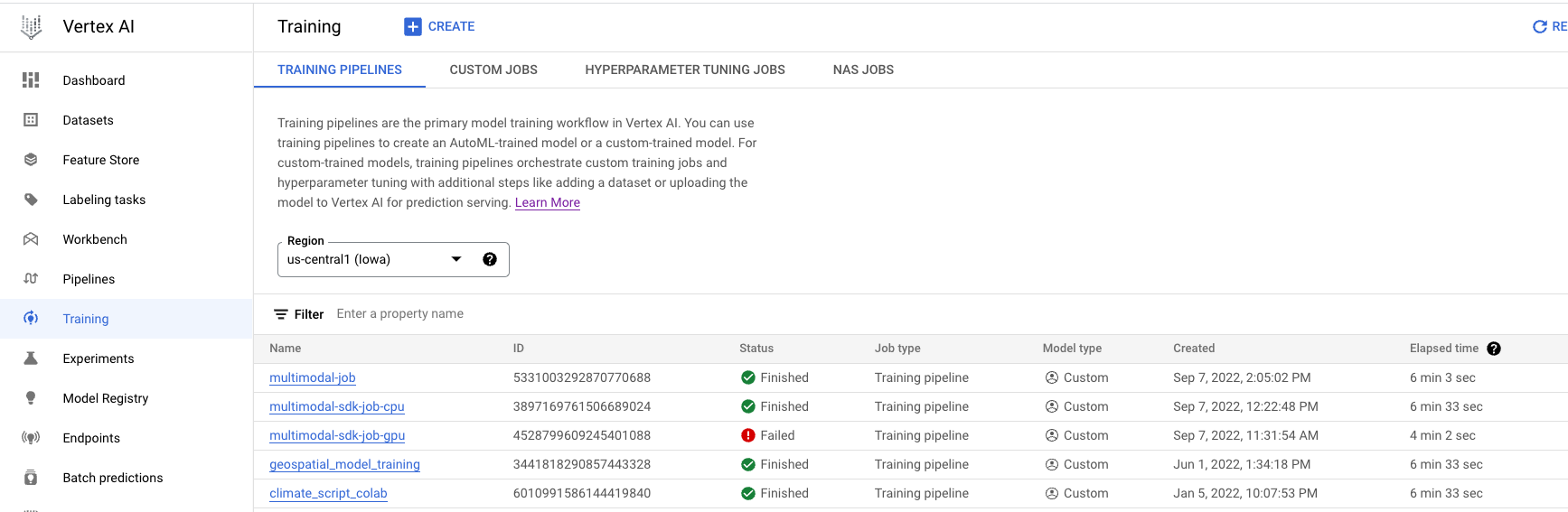
- Wechseln Sie im Bereich „Vertex AI” der Cloud Console zu Training. Sie können einen neuen Trainingsjob erstellen, indem Sie auf ERSTELLEN klicken.
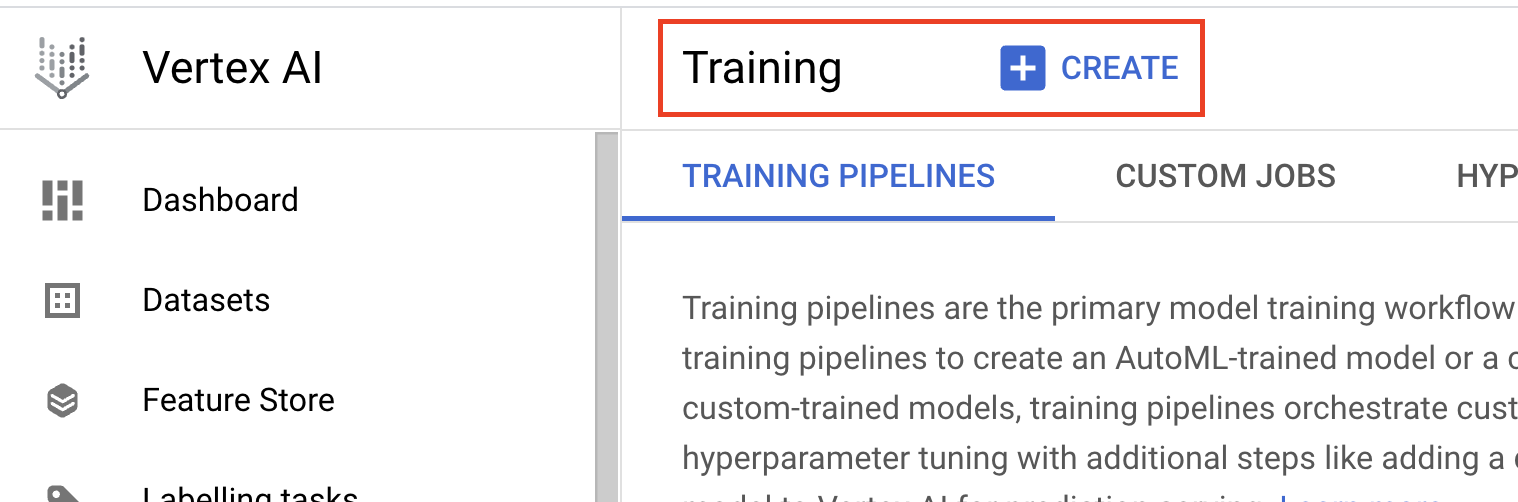
- Wählen Sie unter Trainingsmethode die Option Benutzerdefiniertes Training (erweitert) aus.
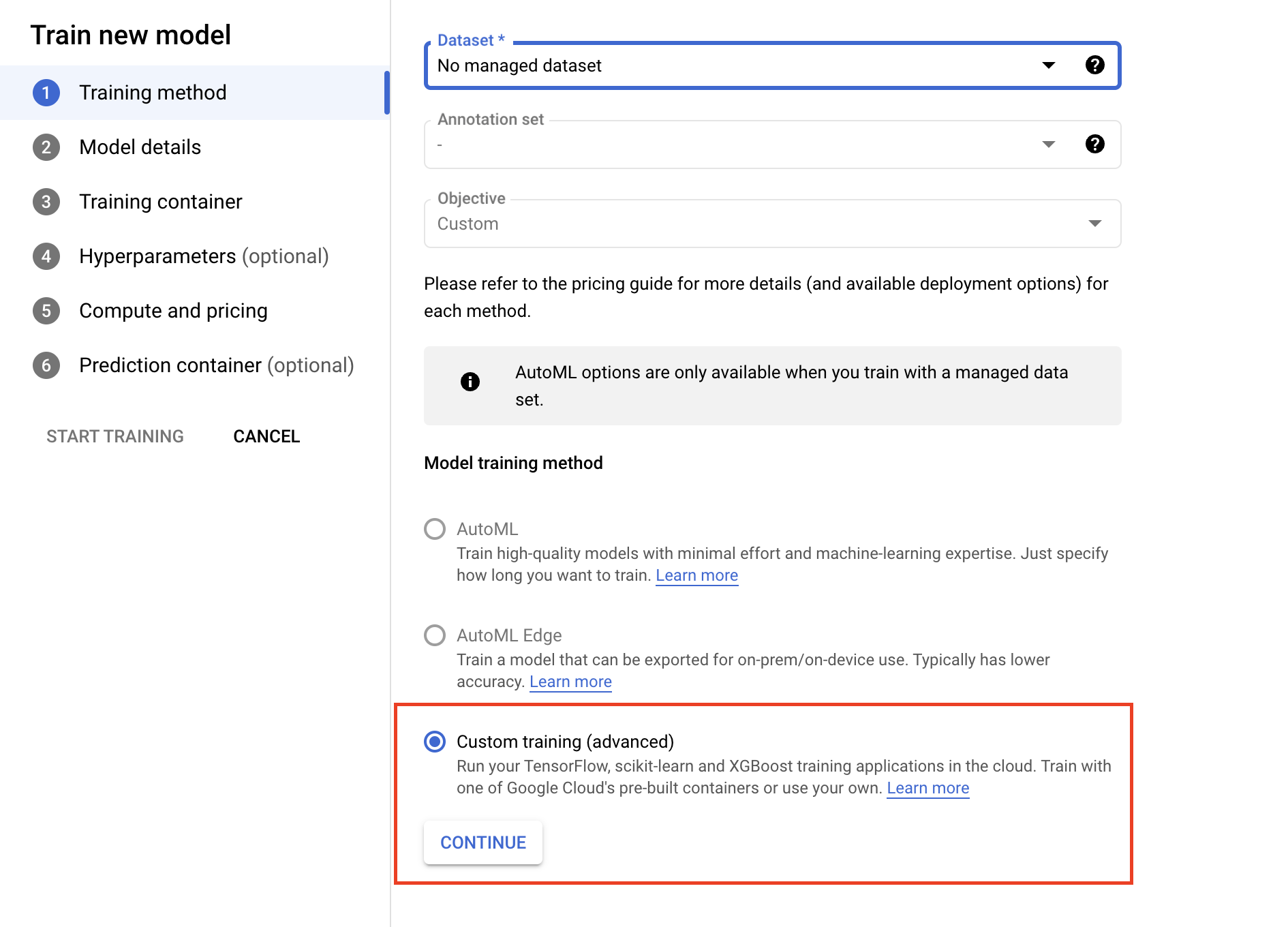
- Wählen Sie im Bereich „Trainingscontainer” entweder einen vordefinierten oder einen benutzerdefinierten Container aus, je nachdem, wie Sie Ihre Anwendung verpackt haben.
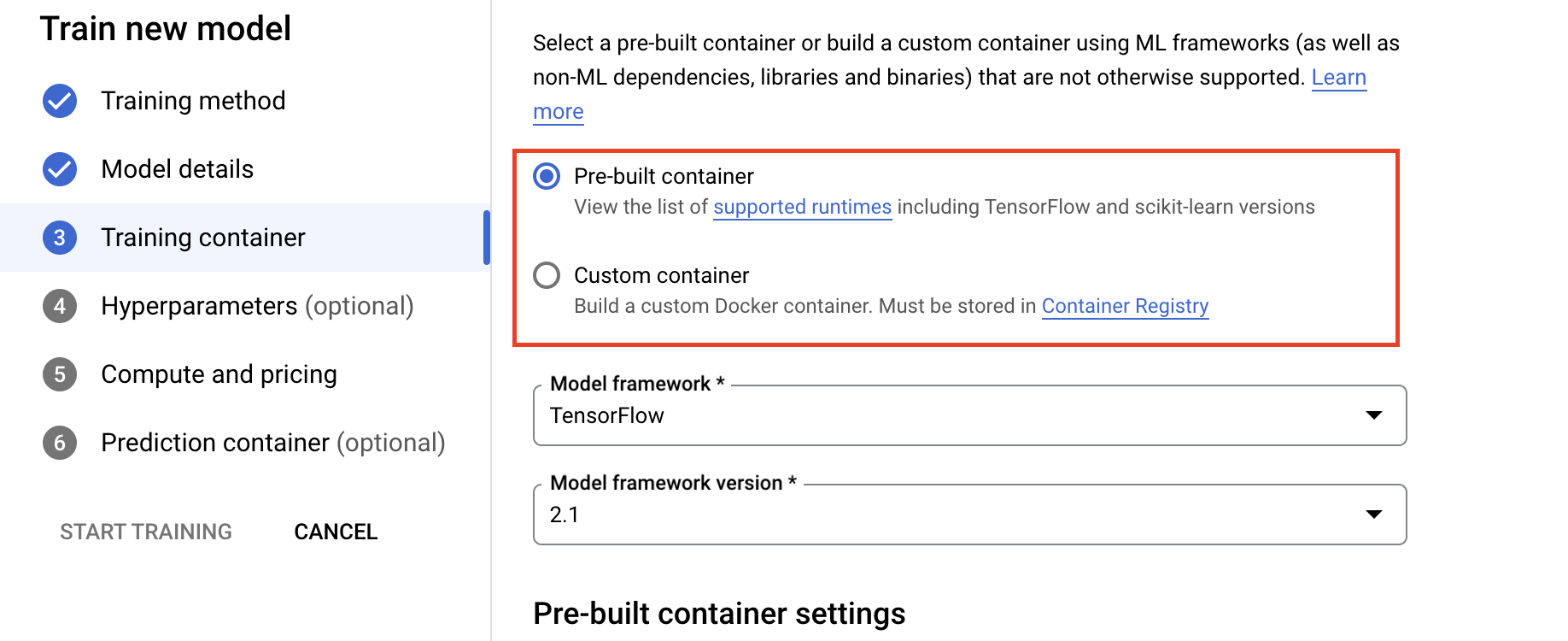
- Geben Sie unter Computing und Preise die Hardware für den Trainingsjob an. Für das Training mit einem einzelnen Knoten müssen Sie nur Worker-Pool 0 konfigurieren. Wenn Sie verteiltes Training ausführen möchten, müssen Sie sich mit den anderen Worker-Pools vertraut machen und mehr über verteiltes Training erfahren.
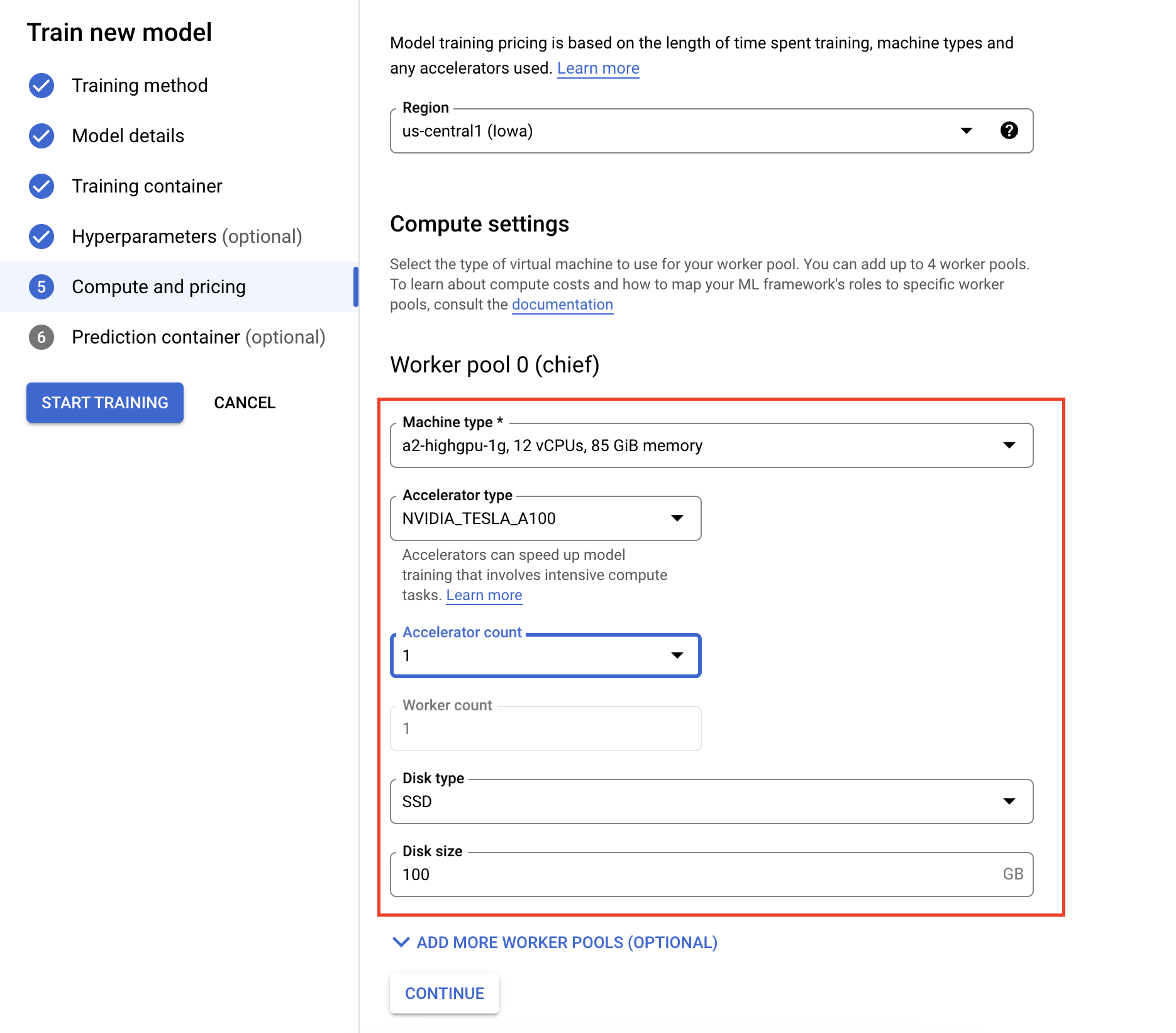
Die Konfiguration des Vorhersagecontainers ist optional. Wenn Sie nur ein Modell in Vertex AI trainieren und auf die resultierenden gespeicherten Modellartefakte zugreifen möchten, können Sie diesen Schritt überspringen. Wenn Sie das resultierende Modell im verwalteten Vertex AI-Vorhersagedienst hosten und bereitstellen möchten, müssen Sie einen Vorhersagecontainer konfigurieren. Weitere Informationen zu Vorhersagecontainern finden Sie hier.
Trainingsjobs beobachten
Sie können Ihren Trainingsjob in der Google Cloud Console beobachten. Sie sehen eine Liste aller ausgeführten Jobs. Sie können auf einen bestimmten Job klicken und die Logs prüfen, wenn Probleme auftreten.