Este guia para iniciantes é uma introdução ao treinamento personalizado na Vertex AI. O treinamento personalizado se refere ao treinamento de um modelo usando um framework de ML, como TensorFlow, PyTorch ou XGBoost.
Objetivos de aprendizado
Nível de experiência da Vertex AI: iniciante
Tempo de leitura estimado: 15 minutos
Você aprenderá a:
- Benefícios do serviço gerenciado para treinamento personalizado
- Práticas recomendadas para empacotar o código de treinamento
- Como enviar e monitorar um job de treinamento
Por que usar um serviço de treinamento gerenciado?
Imagine que você está trabalhando em um novo problema de ML. Você abre um notebook, importa os dados e executa os experimentos. Nesse cenário, você cria um modelo com o framework de ML que você preferir e executa células de notebook para executar um loop de treinamento. Quando o treinamento for concluído, você vai avaliar os resultados do modelo, fazer alterações e executar o treinamento novamente. Esse fluxo de trabalho é útil para testes, mas quando você começa a pensar em criar aplicativos de produção com ML, talvez a execução manual das células do notebook não seja a melhor opção.
Por exemplo, se o conjunto de dados e o modelo forem grandes, convém testar o treinamento distribuído. Além disso, em uma configuração de produção, é improvável que você precise treinar o modelo apenas uma vez. Com o tempo, você treina novamente seu modelo para garantir que ele continue atualizado e produza resultados valiosos. Quando você quer automatizar os experimentos em grande escala ou treinar novamente os modelos de um aplicativo de produção, a utilização de um serviço gerenciado de treinamento de ML simplifica os fluxos de trabalho.
Neste guia, apresentamos uma introdução ao treinamento de modelos personalizados na Vertex AI. Como o serviço de treinamento é totalmente gerenciado, a Vertex AI provisiona automaticamente os recursos de computação, executa a tarefa de treinamento e garante a exclusão de recursos de computação quando o job de treinamento é concluído. Há outras personalizações, recursos e maneiras de interagir com o serviço que não são abordados aqui. O objetivo deste guia é fornecer uma visão geral. Para mais detalhes, consulte a documentação de treinamento da Vertex AI.
Visão geral do treinamento personalizado
O treinamento de modelos personalizados na Vertex AI segue este fluxo de trabalho padrão:
Empacotar o código do aplicativo de treinamento
Configurar e enviar o job de treinamento personalizado
Monitorar o job de treinamento personalizado
Como empacotar o código do aplicativo de treinamento
A execução de um job personalizado de treinamento na Vertex AI é feita com contêineres. Eles são pacotes do código do aplicativo, neste caso o código de treinamento, além de dependências como versões específicas de bibliotecas necessárias para executar o código. Além de ajudar no gerenciamento de dependências, os contêineres podem ser executados em praticamente qualquer lugar, aumentando a portabilidade. Empacotar o código de treinamento com parâmetros e dependências dele em um contêiner para criar um componente portátil é uma etapa importante ao mover aplicativos de ML de protótipo para a produção.
Antes de lançar um job personalizado de treinamento, é necessário empacotar o aplicativo de treinamento. Neste caso, o aplicativo de treinamento se refere a um ou vários arquivos que realizam tarefas como carregar e pré-processar dados, definir um modelo e executar um loop de treinamento. O serviço de treinamento da Vertex AI executa qualquer código que você fornecer. Portanto, cabe a você definir quais etapas incluir no aplicativo de treinamento.
A Vertex AI oferece contêineres pré-criados para TensorFlow, PyTorch, XGBoost e Scikit-learn. Esses contêineres são atualizados regularmente e incluem bibliotecas comuns que podem ser necessárias no código de treinamento. É possível executar o código de treinamento com um desses contêineres ou criar um contêiner personalizado que tenha o código de treinamento e as dependências pré-instalados.
Há três opções para empacotar o código na Vertex AI:
- Enviar um único arquivo Python
- Criar uma distribuição de origem do Python
- Usar contêineres personalizados
Arquivo Python
Essa opção é adequada para experimentos rápidos. Use essa opção se todo o código necessário para executar o aplicativo de treinamento estiver em um arquivo Python e um dos contêineres de treinamento pré-criados da Vertex AI tiver todas as bibliotecas necessárias para executar o aplicativo. Para um exemplo de empacotamento do aplicativo de treinamento como um único arquivo Python, consulte o tutorial do notebook Treinamento personalizado e previsão em lote.
Distribuição de origem do Python
É possível criar uma distribuição de origem Python com o aplicativo de treinamento. Você vai armazenar a distribuição de origem com o código de treinamento e as dependências em um bucket do Cloud Storage. Para um exemplo de empacotamento do aplicativo de treinamento como uma distribuição de origem Python, consulte o tutorial do notebook Como treinar, ajustar e implantar um modelo de classificação do PyTorch.
Contêiner personalizado
Essa opção é útil quando você quer ter mais controle sobre seu aplicativo, ou se quiser executar código que não foi escrito em Python. Nesse caso, você precisará gravar um Dockerfile, criar sua imagem personalizada e enviá-la para o Artifact Registry. Para um exemplo de conteinerização do aplicativo de treinamento, consulte o tutorial do notebook Desempenho do treinamento do modelo de perfil usando o Profiler.
Estrutura recomendada de aplicativo de treinamento
Se você escolher empacotar o código como uma distribuição de origem Python ou como um contêiner personalizado, é recomendável estruturar o aplicativo da seguinte maneira:
training-application-dir/
....setup.py
....Dockerfile
trainer/
....task.py
....model.py
....utils.py
Crie um diretório para armazenar todo o código do aplicativo de treinamento. Neste caso, training-application-dir. Esse diretório vai conter um arquivo setup.py, se você estiver usando uma distribuição de origem Python, ou um Dockerfile, se você estiver usando um contêiner personalizado.
Em ambos os cenários, esse diretório de alto nível também vai conter um subdiretório trainer, que contém todo o código para executar o treinamento. Em trainer, task.py é o ponto de entrada principal do aplicativo. Esse arquivo executa o treinamento de modelo. É possível colocar todo o código nesse arquivo, mas para aplicativos de produção é provável que você tenha outros arquivos, por exemplo, model.py, data.py e utils.py, para citar alguns.
Treinamento personalizado em execução
Os jobs de treinamento na Vertex AI provisionam automaticamente os recursos de computação, executam o código do aplicativo de treinamento e garantem a exclusão de recursos de computação quando o job de treinamento é concluído.
À medida que você criar fluxos de trabalho mais complexos, é provável que use o SDK da Vertex AI para Python para configurar, enviar e monitorar os jobs de treinamento. Porém, na primeira vez que você executar um job de treinamento personalizado, será mais fácil usar o Console do Google Cloud.
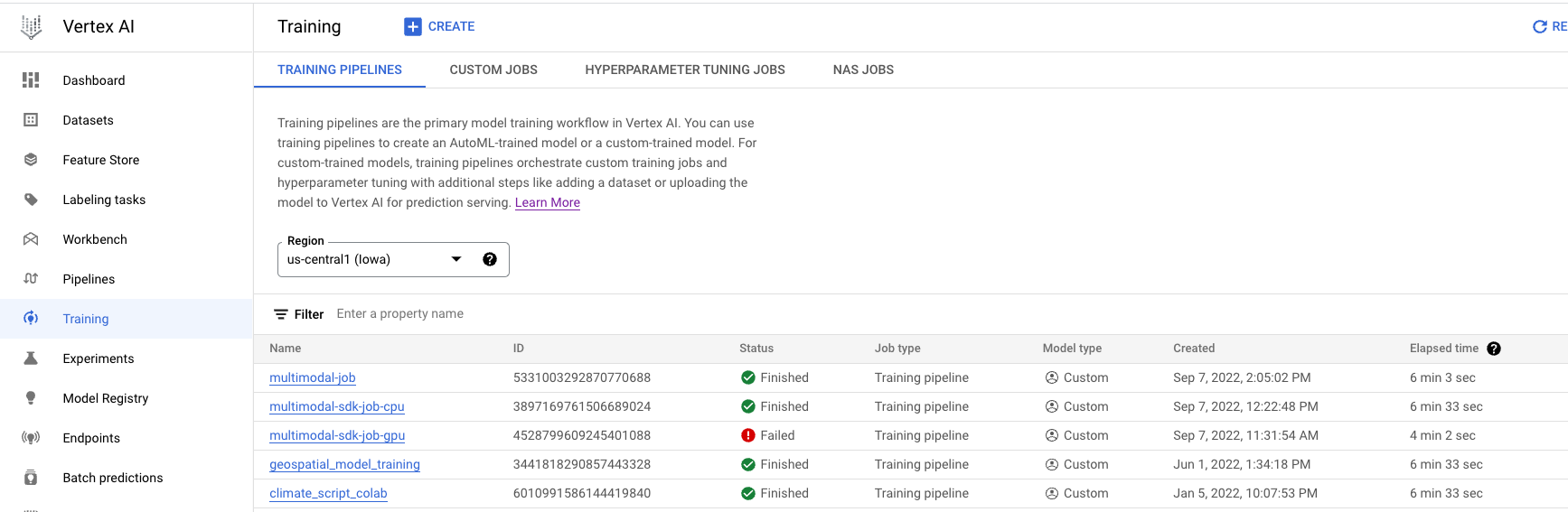
- Navegue até Treinamento na seção "Vertex AI" do console do Cloud. Para criar um job de treinamento, clique no botão CRIAR.
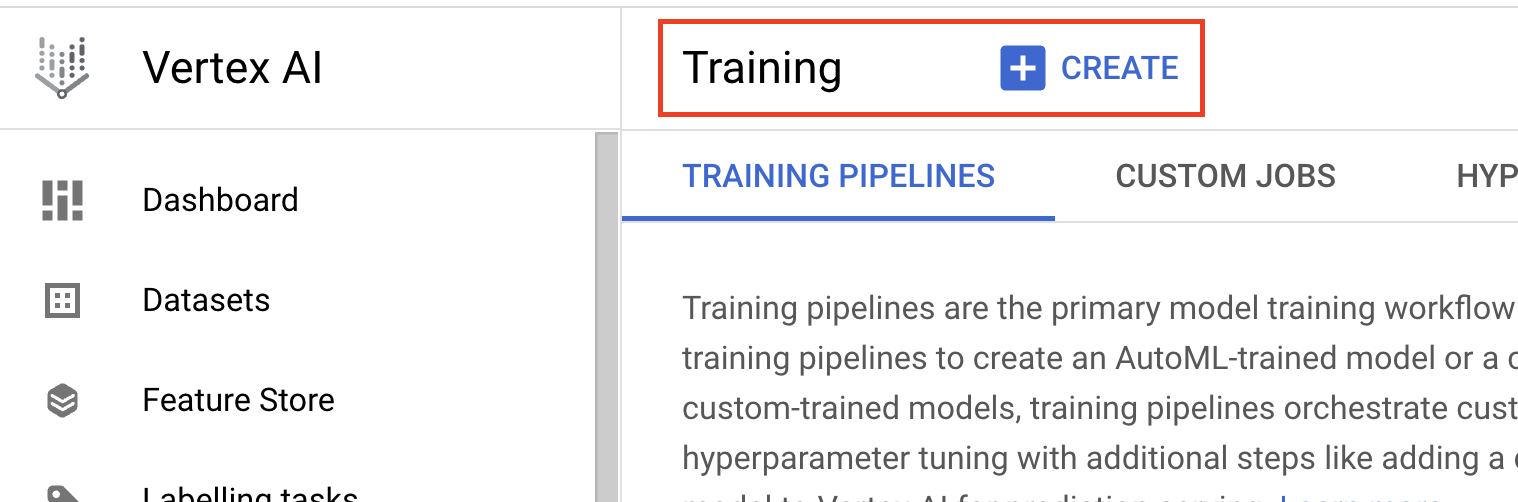
- Em Método de treinamento do modelo, selecione Treinamento personalizado (avançado).
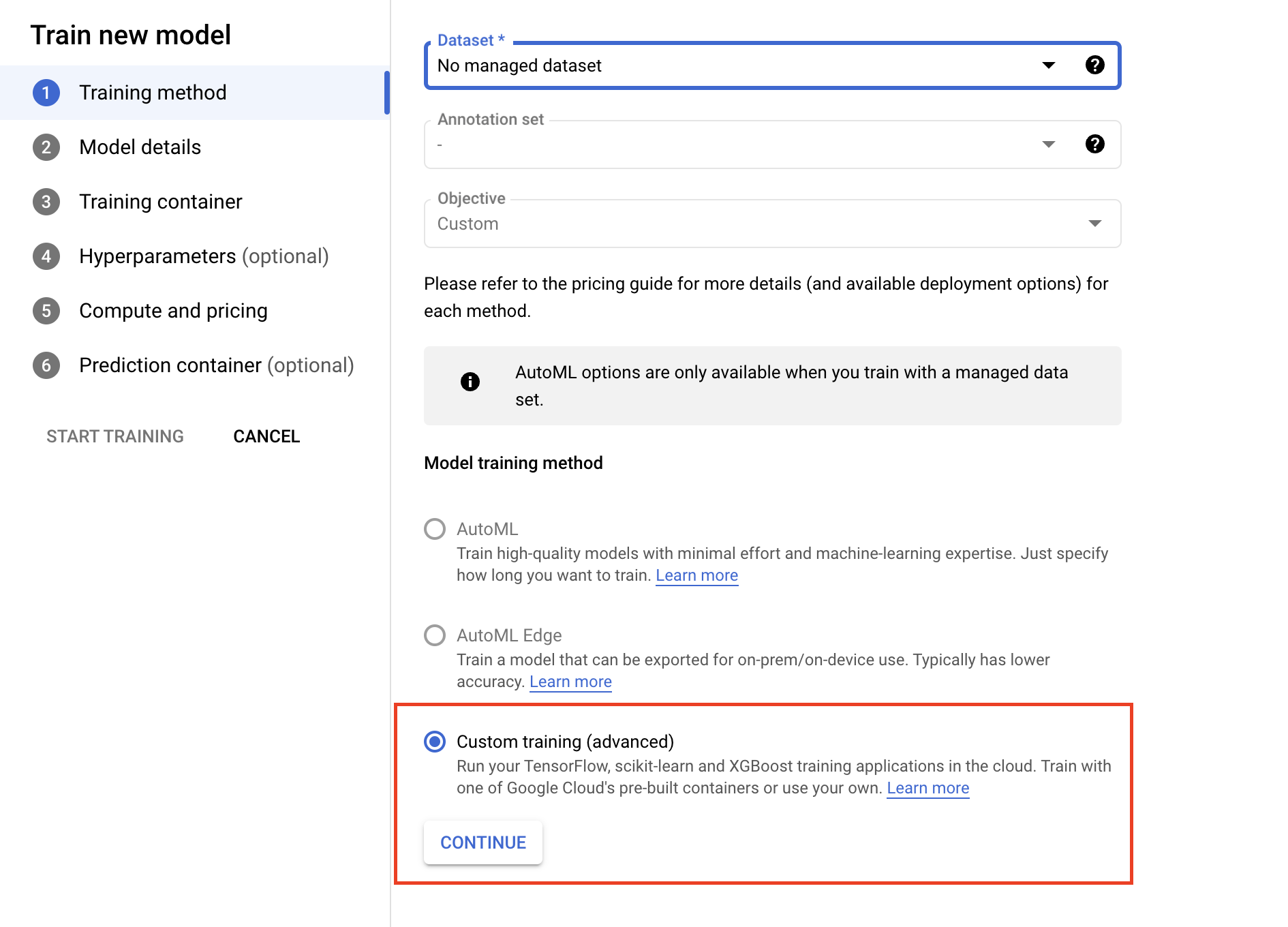
- Na seção "Contêiner de treinamento", selecione o contêiner pré-criado ou personalizado, dependendo de como você empacota o aplicativo.
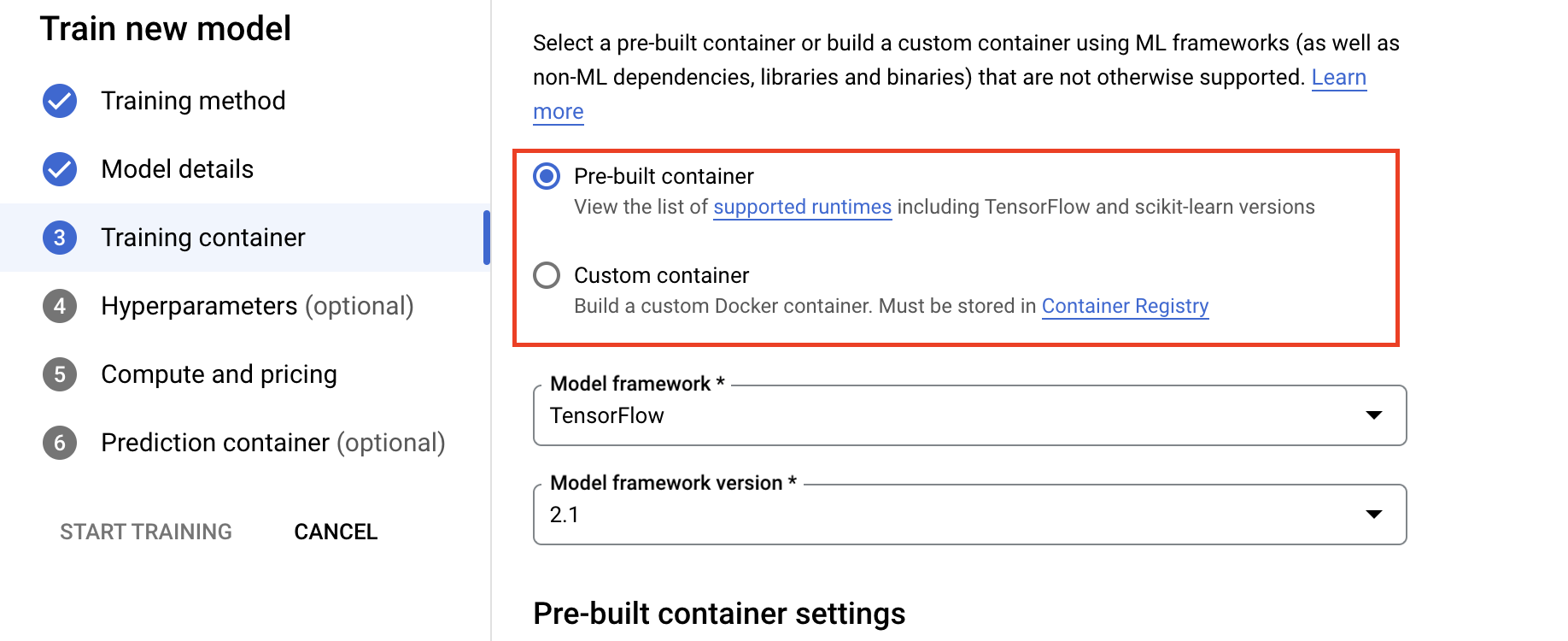
- Em Computação e preços, especifique o hardware para o job de treinamento. Para o treinamento de nó único, você só precisa configurar o pool de workers 0. Se você tiver interesse em executar o treinamento distribuído, precisará entender os outros pools de workers e saber mais sobre Treinamento distribuído.
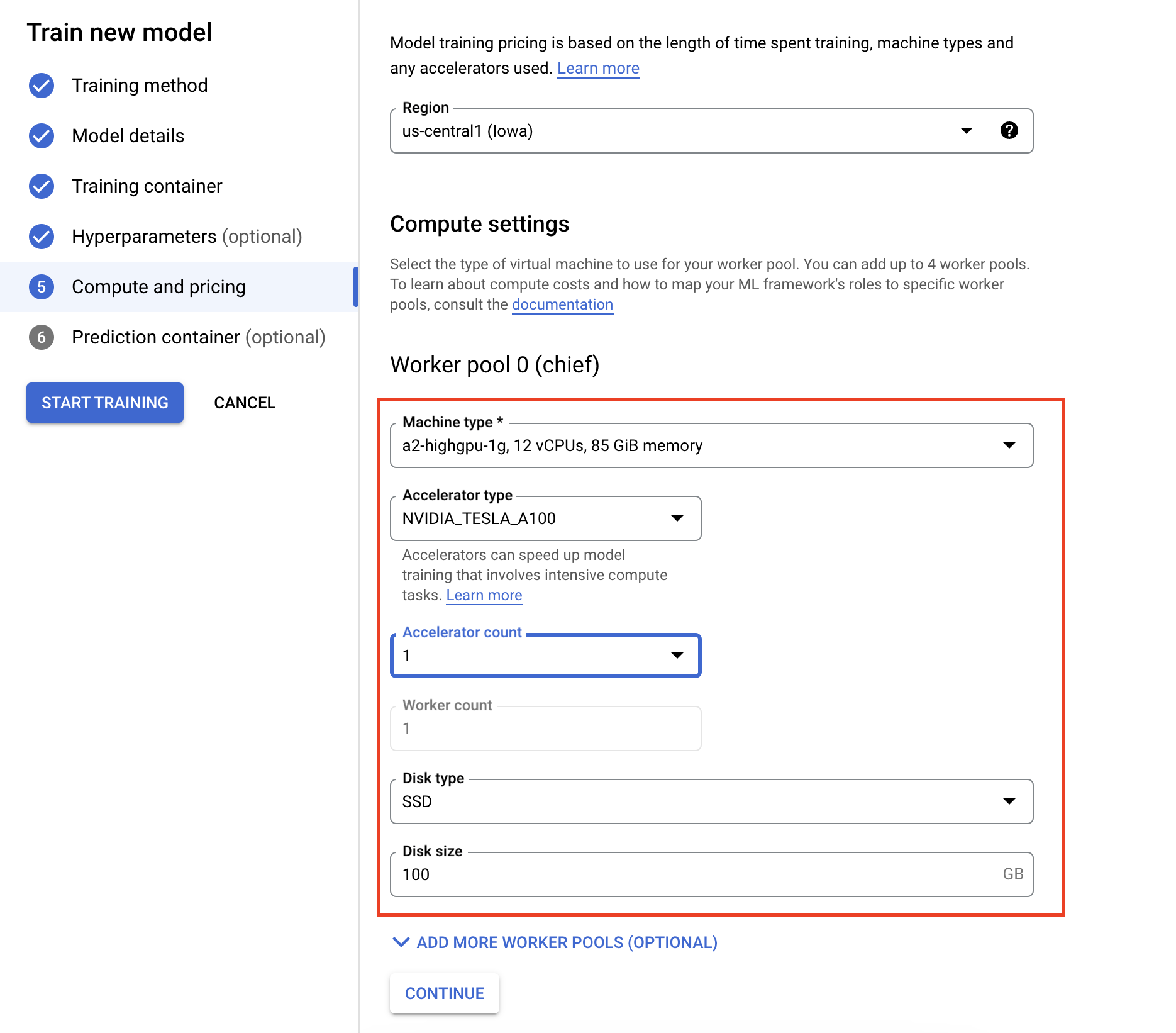
A configuração do contêiner de previsão é opcional. Se você quiser apenas treinar um modelo na Vertex AI e acessar os artefatos de modelo salvos resultantes, pule esta etapa. Se quiser hospedar e implantar o modelo resultante no serviço de previsão gerenciado da Vertex AI, você precisará configurar um contêiner de previsão. Saiba mais sobre contêineres de previsão.
Como monitorar jobs de treinamento
É possível monitorar um job de treinamento no console do Google Cloud. Você verá uma lista de todos os jobs que foram executados. Clique em um job específico e examine os registros se algo der errado.