简介
本页面从概念上简要介绍了 Vertex AI 提供的特征归因方法。如需查看对技术的深入讨论,请参阅 AI Explanations 白皮书。
全局特征重要性(模型特征归因)显示每个特征对模型的影响程度。这些值是以每个特征的百分比形式提供的:百分比越高,特征对模型训练的影响就越大。如需查看模型的全局特征重要性,请检查评估指标。
时间序列模型的局部特征归因指出了数据中每个特征对预测结果的影响程度。然后,您可以使用这些信息验证模型的行为是否符合预期、识别模型中的偏差,并在寻找改进模型和训练数据的方法时获得启发。请求预测时,您会获得适合您模型的预测值。请求说明时,您会获得预测结果以及特征归因信息。
请考虑以下示例:深度神经网络经训练后可根据天气数据和之前的骑行共享数据来预测骑行时长。如果您仅使用此模型请求预测结果,则可以在几分钟后获得预计的骑行时长。如果您请求说明,则会获得预计的骑行时长,以及说明请求中每个特征的归因分数。归因分数显示特征对预测值相对于指定基准值的变化的影响程度。选择对模型有意义的基准,在本例中,基准为骑行时长的中间值。
您可以绘制特征归因分数,查看哪些特征对生成的预测结果影响最大:
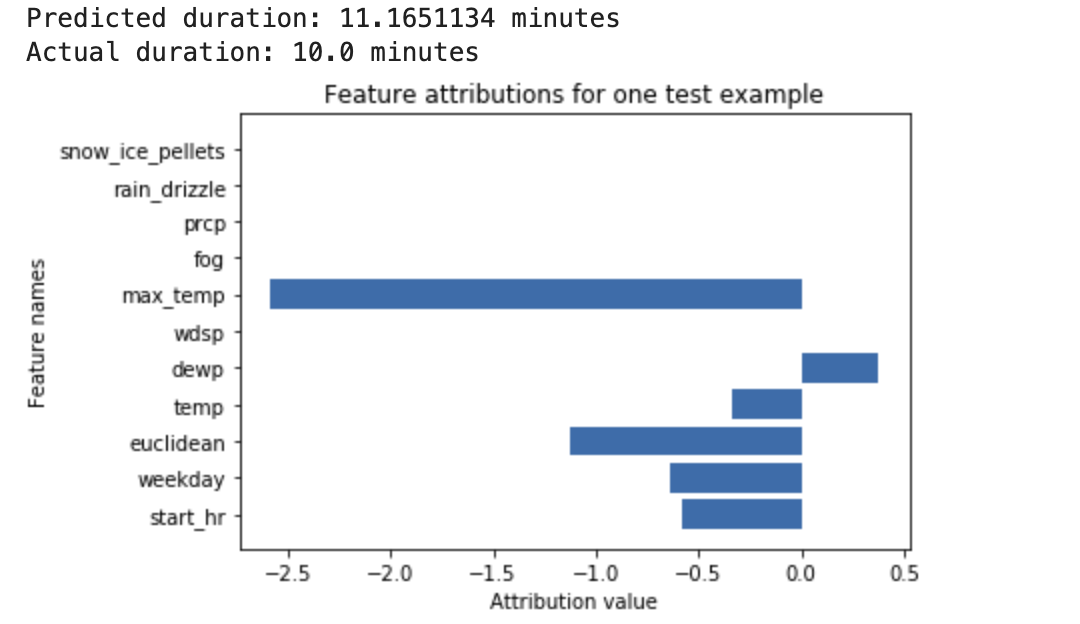
您可以在执行在线预测作业或批量预测作业时生成并查询局部特征归因。
优点
如果您在训练数据集中检查特定实例并汇总特征归因,就可以更深入地了解模型的工作原理。请考虑以下优点:
调试模型:特征归因有助于检测出数据中通常被标准模型评估技术忽略的问题。
优化模型:您可以识别和移除不太重要的特征,从而生成更有效率的模型。
概念限制
请考虑特征归因的以下限制:
特征归因(包括 AutoML 的本地特征重要性)特定于个别预测。检查个别预测结果的特征归因可能会提供有用的见解,但对于该实例的整个类或整个模型来说,该见解可能不具备概括性。
如需获得更通用的 AutoML 模型数据分析,请参阅模型特征重要性。如需获得针对其他模型的更多数据洞见,请通过数据集内的子集或整个数据集聚合归因。
每个归因只会反映特征对该特定样本的预测结果的影响程度。单一归因可能无法反映模型的总体行为。如需了解模型在处理整个数据集方面的大致行为,请对整个数据集进行归因汇总。
虽然特征归因有助于调试模型,但它们无法保证总能清楚指出问题是由模型引起的,还是由训练模型所采用的数据引起的。您必须尽量正确地做出判断,并诊断常见的数据问题,以筛查出可能的原因。
归因完全取决于模型以及用于训练该模型的数据。它们只能展示模型在数据中发现的模式,而无法检测到数据中的任何基本关系。某个特征是否存在强有力的归因并不意味着该特征与目标之间是否存在关系。归因只是表明模型是否在其预测中使用该特征。
您不能仅凭归因,就判断模型是否公平、无偏差或可靠。除了相应归因之外,您还要仔细评估训练数据和评估指标。
如需详细了解限制,请参阅 AI Explanations 白皮书。
改善特征归因
以下因素对特征归因的影响最大:
- 归因方法只会大致估计 Shapley 值。您可以通过增加采样 Shapley 方法的路径数来提高近似值的精确率。因此,归因可能会发生巨大变化。
- 归因只能表明相对于基准值,特征对预测值变化的影响程度。请确保选择有意义的基准,该基准应与您向模型询问的问题相关。归因值及其解释可能会随着基准的改变而发生显著变化。
算法
Vertex AI 使用 Shapley 值提供特征归因,这是一种合作博弈论算法,用于根据游戏结果为特定玩家分配积分。应用到机器学习模型中,就意味着每个模型特征都被视作游戏中的一个“玩家”,积分按特定预测结果的比例分配。对于结构化数据模型,Vertex AI 使用精确 Shapley 值的采样近似值,称为采样 Shapley。
如需深入了解采样的 Shapley 方法的工作原理,请参阅论文《限定采样 Shapley 值逼近法的估计误差》。
后续步骤
以下资源提供了更多有用的教育材料: