Quando utilizzi un set di dati per addestrare un modello AutoML, i dati vengono suddivisi in tre suddivisioni: una suddivisione addestramento, una suddivisione convalida e una suddivisione test. L'obiettivo principale della creazione di suddivisioni dei dati è garantire che il set di test rappresenti accuratamente i dati di produzione. Ciò garantisce che le metriche di valutazione forniscano un indicatore preciso delle prestazioni del modello sui dati reali.
Questa pagina descrive in che modo Vertex AI utilizza i set di addestramento, convalida e test dei tuoi dati per addestrare un modello AutoML, nonché i modi in cui puoi controllare in che modo i dati vengono suddivisi in questi tre set. Gli algoritmi di suddivisione dei dati per la classificazione e la regressione sono diversi da quelli per la suddivisione dei dati per le previsioni.
Suddivisione dei dati per classificazione e regressione
Come vengono utilizzate le suddivisioni di dati
Le suddivisioni dei dati vengono utilizzate nel processo di addestramento come segue:
Prove del modello
Il set di addestramento viene utilizzato per addestrare modelli con diverse combinazioni di opzioni di pre-elaborazione, architettura e iperparametri. Questi modelli vengono valutati in base al set di convalida della qualità, che guida l'esplorazione di ulteriori combinazioni di opzioni. Il set di convalida serve anche per selezionare il miglior checkpoint dalla valutazione periodica durante l'addestramento. I parametri e le architetture migliori determinati nella fase di ottimizzazione parallela vengono utilizzati per addestrare due modelli di insieme come descritto di seguito.
Valutazione del modello
Vertex AI addestra un modello di valutazione, utilizzando i set di addestramento e convalida come dati di addestramento. Vertex AI genera le metriche di valutazione del modello finali su questo modello utilizzando il set di test. È la prima volta nel processo in cui viene utilizzato il set di test. Questo approccio garantisce che le metriche di valutazione finale rispecchino imparzialmente le prestazioni del modello addestrato finale in produzione.
Modello di pubblicazione
Un modello viene addestrato con i set di addestramento, convalida e test per massimizzare la quantità di dati di addestramento. Questo modello è quello che si utilizza per richiedere previsioni online o previsioni batch.
Suddivisione dati predefinita
Per impostazione predefinita, Vertex AI utilizza un algoritmo di suddivisione casuale per separare i dati in tre suddivisioni. Vertex AI seleziona in modo casuale l'80% delle righe di dati per il set di addestramento, il 10% per il set di convalida e il 10% per il set di test. Ti consigliamo la suddivisione predefinita per i set di dati che sono:
- Non cambia nel tempo.
- Relativamente bilanciata.
- Distribuiti come i dati utilizzati per le previsioni in produzione.
Per utilizzare la suddivisione dati predefinita, accetta il valore predefinito nella console Google Cloud o lascia vuoto il campo split per l'API.
Opzioni per il controllo delle suddivisioni dei dati
Puoi controllare quali righe vengono selezionate per quale suddivisione utilizzando uno dei seguenti approcci:
- Suddivisione casuale: imposta le percentuali di suddivisione e assegna le righe di dati in modo casuale.
- Suddivisione manuale: seleziona righe specifiche da utilizzare per l'addestramento, la convalida e il test nella colonna di suddivisione dati.
- Suddivisione cronologica: consente di suddividere i dati in base all'ora nella colonna Temporale.
Puoi scegliere solo una di queste opzioni; sei tu a scegliere quando addestra il modello. Alcune di queste opzioni richiedono modifiche ai dati di addestramento (ad esempio, la colonna di suddivisione dati o la colonna del tempo). L'inclusione dei dati per le opzioni di suddivisione dei dati non richiede l'utilizzo di queste opzioni; puoi comunque scegliere un'altra opzione durante l'addestramento del modello.
La suddivisione predefinita non è la scelta migliore se:
Non stai addestrando un modello di previsione, ma i tuoi dati sono sensibili al tempo.
In questo caso, devi utilizzare una suddivisione cronologica o una suddivisione manuale che generi i dati più recenti utilizzati come set di test.
I dati di test includono dati di popolazioni che non verranno rappresentate in produzione.
Ad esempio, supponiamo che tu stia addestrando un modello con dati di acquisto da una serie di negozi. Tuttavia, sai che il modello verrà utilizzato principalmente per fare previsioni per gli archivi non inclusi nei dati di addestramento. Per assicurarti che il modello possa essere generalizzato ad archivi non considerati, devi separare i set di dati in base agli archivi. In altre parole, il set di test deve includere solo archivi diversi dal set di convalida e il set di convalida deve includere solo archivi diversi dal set di addestramento.
I tuoi corsi non sono bilanciati.
Se nei tuoi dati di addestramento sono presenti più classi rispetto a un'altra, potrebbe essere necessario includere manualmente più esempi della classe di minoranza nei dati di test. Vertex AI non esegue il campionamento stratificato, quindi il set di test potrebbe includere un numero troppo basso o addirittura pari a zero di esempi della classe minoritaria.
Suddivisione casuale
La suddivisione casuale è nota anche come "suddivisione matematica" o "suddivisione frazione".
Per impostazione predefinita, le percentuali dei dati di addestramento utilizzati per i set di addestramento, convalida e test sono rispettivamente 80, 10 e 10. Se usi la console Google Cloud, puoi modificare le percentuali in qualsiasi valore la cui somma sia 100. Se usi l'API Vertex AI, impiegherai frazioni che corrispondono a 1,0.
Per modificare le percentuali (frazioni), utilizza l'oggetto FractionSplit per definire le frazioni.
Per una suddivisione dei dati in modo casuale, vengono selezionate le righe in modo deterministico. Se la composizione delle suddivisioni dei dati generate non ti soddisfa, devi utilizzare una suddivisione manuale o modificare i dati di addestramento. Addestrare un nuovo modello con gli stessi dati di addestramento produce la stessa suddivisione dei dati.
Suddivisione manuale
La suddivisione manuale è nota anche come "suddivisione predefinita".
Una colonna di suddivisione dati consente di selezionare righe specifiche da utilizzare per addestramento, convalida e test. Quando crei i dati di addestramento, aggiungi una colonna che può contenere uno dei seguenti valori (sensibili alle maiuscole):
TRAINVALIDATETESTUNASSIGNED
I valori in questa colonna devono corrispondere a una delle due seguenti combinazioni:
- Tutti in
TRAIN,VALIDATEeTEST - Solo
TESTeUNASSIGNED
Ogni riga deve avere un valore per questa colonna; non può essere la stringa vuota.
Ad esempio, con tutti gli insiemi specificati:
"TRAIN","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "TRAIN","Roger","Rogers","123-45-6789" "VALIDATE","Sarah","Smith","333-33-3333"
Con solo il set di test specificato:
"UNASSIGNED","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "UNASSIGNED","Roger","Rogers","123-45-6789" "UNASSIGNED","Sarah","Smith","333-33-3333"
La colonna di suddivisione dati può avere qualsiasi nome di colonna valido; il suo tipo di trasformazione può essere Categorical, Testo o Automatico.
Se il valore della colonna di suddivisione dati è UNASSIGNED, Vertex AI assegna automaticamente la riga al set di addestramento o convalida.
Specifica una colonna come colonna di suddivisione dati durante l'addestramento del modello.
Suddivisione cronologica
La suddivisione cronologica è nota anche come "suddivisione timestamp".
Se i dati sono dipendenti dal tempo, puoi designare una colonna come colonna Temporale. Vertex AI usa la colonna Tempo per suddividere i dati, con le prime righe utilizzate per l'addestramento, le righe successive per la convalida e le righe più recenti per i test.
Vertex AI considera ogni riga come un esempio di addestramento indipendente e distribuito in modo identico; l'impostazione della colonna Tempo non cambia. La colonna Tempo viene utilizzata solo per suddividere il set di dati.
Se specifichi una colonna Tempo, devi includere un valore per questa colonna per ogni riga del set di dati. Assicurati che la colonna Tempo abbia valori distinti sufficienti in modo che i set di convalida e test non siano vuoti. In genere, avere almeno 20 valori distinti dovrebbe essere sufficiente.
I dati nella colonna Data/ora devono essere conformi a uno dei formati supportati dalla trasformazione timestamp. Tuttavia, la colonna Tempo può avere qualsiasi trasformazione supportata, poiché la trasformazione interessa solo il modo in cui la colonna viene utilizzata nell'addestramento; le trasformazioni non influiscono sulla suddivisione dei dati.
Puoi anche specificare le percentuali dei dati di addestramento che vengono assegnati a ogni set.
Specifica una colonna come colonna Tempo durante l'addestramento del modello.
Suddivisione dei dati per la previsione
Per impostazione predefinita, Vertex AI utilizza un algoritmo di suddivisione cronologica per separare i dati di previsione nelle tre suddivisioni di dati. Ti consigliamo di utilizzare la suddivisione predefinita. Tuttavia, se vuoi controllare quali righe di dati di addestramento vengono utilizzate per una determinata suddivisione, utilizza una suddivisione manuale.
Come vengono utilizzate le suddivisioni di dati
Le suddivisioni dei dati vengono utilizzate nel processo di addestramento come segue:
Prove del modello
Il set di addestramento viene utilizzato per addestrare modelli con diverse combinazioni di opzioni di pre-elaborazione, architettura e iperparametri. Questi modelli vengono valutati in base al set di convalida della qualità, che guida l'esplorazione di ulteriori combinazioni di opzioni. Il set di convalida serve anche per selezionare il miglior checkpoint dalla valutazione periodica durante l'addestramento. I parametri e le architetture migliori determinati nella fase di ottimizzazione parallela vengono utilizzati per addestrare due modelli di insieme come descritto di seguito.
Valutazione del modello
Vertex AI addestra un modello di valutazione, utilizzando i set di addestramento e convalida come dati di addestramento. Vertex AI genera le metriche di valutazione del modello finali su questo modello utilizzando il set di test. È la prima volta nel processo in cui viene utilizzato il set di test. Questo approccio garantisce che le metriche di valutazione finale rispecchino imparzialmente le prestazioni del modello addestrato finale in produzione.
Modello di pubblicazione
Un modello viene addestrato con il set di addestramento e convalida. Viene convalidato (per selezionare il checkpoint migliore) utilizzando il set di test. Il set di test non viene mai addestrato nel senso che la perdita viene calcolata a partire da questo. Questo modello è quello che utilizzi per richiedere previsioni.
Suddivisione predefinita
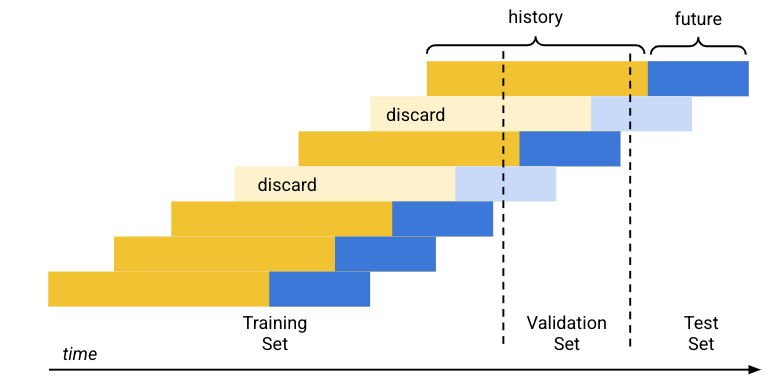
La suddivisione dei dati predefinita (cronologica) funziona come segue:
- I dati di addestramento sono ordinati per data.
- Utilizzando le percentuali impostate predeterminate (80/10/10), il periodo di tempo coperto dai dati di addestramento viene separato in tre blocchi, uno per ogni set di addestramento.
- Le righe vuote vengono aggiunte all'inizio di ogni serie temporale per consentire al modello di apprendere dalle righe che non hanno una cronologia sufficiente (finestra di contesto). Il numero di righe aggiunte è la dimensione della finestra di contesto impostata al momento dell'addestramento.
Utilizzando la dimensione dell'orizzonte di previsione impostata al momento dell'addestramento, ogni riga i cui dati futuri (orizzonte di previsione) rientrano completamente in uno dei set di dati viene utilizzata per l'insieme in questione. Le righe il cui orizzonte di previsione si trova a cavallo di due set vengono eliminate per evitare una fuga di dati.
Suddivisione manuale
Una colonna di suddivisione dati consente di selezionare righe specifiche da utilizzare per addestramento, convalida e test. Quando crei i dati di addestramento, aggiungi una colonna che può contenere uno dei seguenti valori (sensibili alle maiuscole):
TRAINVALIDATETEST
Ogni riga deve avere un valore per questa colonna; non può essere la stringa vuota.
Ad esempio:
"TRAIN","sku_id_1","2020-09-21","10" "TEST","sku_id_1","2020-09-22","23" "TRAIN","sku_id_2","2020-09-22","3" "VALIDATE","sku_id_2","2020-09-23","45"
La colonna di suddivisione dati può avere qualsiasi nome di colonna valido; il suo tipo di trasformazione può essere Categorical, Testo o Automatico.
Specifica una colonna come colonna di suddivisione dati durante l'addestramento del modello.
Assicurati di evitare fuga di dati tra le serie temporali.