En esta página, se muestra cómo entrenar un modelo de previsión a partir de un conjunto de datos tabular con el flujo de trabajo tabular para la previsión.
Para obtener información sobre las cuentas de servicio que usa este flujo de trabajo, consulta Cuentas de servicio para Workflows tabulares.
Si recibes un error relacionado con las cuotas mientras ejecutas el flujo de trabajo tabular para la previsión, es posible que debas solicitar una cuota más alta. Para obtener más información, consulta Administra cuotas para Tabular Workflows.
El flujo de trabajo tabular para la previsión no admite la exportación de modelos.
APIs de flujo de trabajo
En este flujo de trabajo, se usan las siguientes APIs:
- Vertex AI
- Dataflow
- Compute Engine
- Cloud Storage
Obtén el URI del resultado de ajuste de hiperparámetros anterior
Si completaste una ejecución del flujo de trabajo tabular para la previsión, puedes usar el resultado del ajuste de hiperparámetros de una ejecución anterior para ahorrar tiempo y recursos de entrenamiento. Puedes encontrar el resultado del ajuste de hiperparámetros anterior con la consola de Google Cloud o cargarlo de manera programática mediante la API.
Consola de Google Cloud
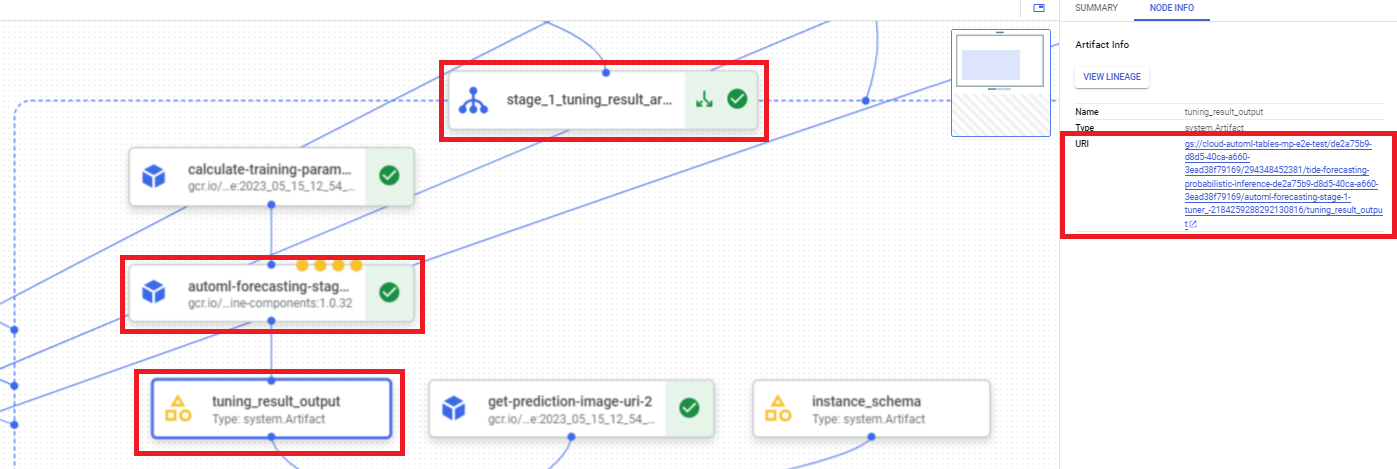
Para encontrar el URI de resultado de ajuste de hiperparámetros mediante la consola de Google Cloud, sigue estos pasos:
En la sección Vertex AI de la consola de Google Cloud, ve a la página Canalizaciones.
Selecciona la pestaña Ejecuciones.
Selecciona la ejecución de la canalización que deseas usar.
Selecciona Expandir artefactos.
Haz clic en el componente exit-handler-1.
Haz clic en el componente stage_1_tuning_result_artifact_uri_empty.
Busca el componente automl-forecasting-stage-1-tuner.
Haz clic en el artefacto asociado tuning_result_output.
Selecciona la pestaña Información del nodo.
Copia el URI para usarlo en el paso Entrena un modelo.
API: Python
En el código de muestra siguiente, se demuestra cómo puedes cargar el resultado del ajuste de hiperparámetros mediante la API. La variable job hace referencia a la ejecución de la canalización de entrenamiento del modelo anterior.
def get_task_detail(
task_details: List[Dict[str, Any]], task_name: str
) -> List[Dict[str, Any]]:
for task_detail in task_details:
if task_detail.task_name == task_name:
return task_detail
pipeline_task_details = job.gca_resource.job_detail.task_details
stage_1_tuner_task = get_task_detail(
pipeline_task_details, "automl-forecasting-stage-1-tuner"
)
stage_1_tuning_result_artifact_uri = (
stage_1_tuner_task.outputs["tuning_result_output"].artifacts[0].uri
)
Entrenar un modelo
En el siguiente código de muestra, se ilustra cómo puedes ejecutar una canalización de entrenamiento de modelos:
job = aiplatform.PipelineJob(
...
template_path=template_path,
parameter_values=parameter_values,
...
)
job.run(service_account=SERVICE_ACCOUNT)
El parámetro service_account opcional en job.run() te permite configurar la cuenta de servicio de Vertex AI Pipelines en una cuenta que elijas.
Vertex AI admite los siguientes métodos para entrenar tu modelo:
Codificador denso de la serie temporal (TiDE) Para usar este método de entrenamiento de modelos, define la canalización y los valores de los parámetros con la siguiente función:
template_path, parameter_values = automl_forecasting_utils.get_time_series_dense_encoder_forecasting_pipeline_and_parameters(...)Transformador de fusión temporal (TFT) Para usar este método de entrenamiento de modelos, define la canalización y los valores de los parámetros con la siguiente función:
template_path, parameter_values = automl_forecasting_utils.get_temporal_fusion_transformer_forecasting_pipeline_and_parameters(...)AutoML (L2L) Para usar este método de entrenamiento de modelos, define la canalización y los valores de los parámetros con la siguiente función:
template_path, parameter_values = automl_forecasting_utils.get_learn_to_learn_forecasting_pipeline_and_parameters(...)Seq2Seq+. Para usar este método de entrenamiento de modelos, define la canalización y los valores de los parámetros con la siguiente función:
template_path, parameter_values = automl_forecasting_utils.get_sequence_to_sequence_forecasting_pipeline_and_parameters(...)
Para obtener más información, consulta Métodos de entrenamiento de modelos.
Los datos de entrenamiento pueden ser un archivo CSV en Cloud Storage o una tabla en BigQuery.
El siguiente es un subconjunto de los parámetros de entrenamiento del modelo:
| Nombre del parámetro | Tipo | Definición |
|---|---|---|
optimization_objective |
Cadena | De forma predeterminada, Vertex AI minimiza el error de la raíz cuadrada de la media (RMSE). Si desea tener un objetivo de optimización diferente para su modelo de previsión, elija una de las opciones en Objetivos de optimización para los modelos de previsión. Si eliges minimizar la pérdida cuantil, también debes especificar un valor para quantiles. |
enable_probabilistic_inference |
Booleano | Si se configura como true, Vertex AI modela la distribución de probabilidad de la previsión. La inferencia probabilística puede mejorar la calidad del modelo mediante el manejo de datos ruidosos y la cuantificación de la incertidumbre. Si se especifica quantiles, Vertex AI también muestra los cuantiles de la distribución. La inferencia probabilística solo es compatible con los métodos de entrenamiento de Decodificador denso de series temporales (TiDE) y de AutoML (L2L). La inferencia probabilística no es compatible con el objetivo de optimización minimize-quantile-loss. |
quantiles |
Lista[float] | Cuantiles para usar en el objetivo de optimización de minimize-quantile-loss y la inferencia probabilística. Proporciona una lista de hasta cinco números únicos entre 0 y 1, sin incluir. |
time_column |
Cadena | La columna de tiempo. Para obtener más información, consulta Requisitos de estructura de los datos. |
time_series_identifier_columns |
List[str] | Las columnas de identificador de serie temporal. Para obtener más información, consulta Requisitos de estructura de los datos. |
weight_column |
Cadena | (Opcional) La columna de ponderación. Para obtener más información, consulta Agrega ponderaciones a tus datos de entrenamiento. |
time_series_attribute_columns |
List[str] | (Opcional) El nombre o los nombres de las columnas que son atributos de serie temporal. Para obtener más información, consulta Tipo de atributo y disponibilidad en la previsión. |
available_at_forecast_columns |
List[str] | (Opcional) El nombre o los nombres de las columnas de covarianza cuyo valor se conoce en el momento de la previsión. Para obtener más información, consulta Tipo de atributo y disponibilidad en la previsión. |
unavailable_at_forecast_columns |
List[str] | (Opcional) El nombre o los nombres de las columnas de variables cuyo valor es desconocido en el momento de la previsión. Para obtener más información, consulta Tipo de atributo y disponibilidad en la previsión. |
forecast_horizon |
Integer | (Opcional) El horizonte de previsión determina hasta qué punto del futuro el modelo predice el valor objetivo de cada fila de datos de predicción. Para obtener más información, consulta horizonte de previsión, ventana de contexto y ventana de previsión. |
context_window |
Integer | (Opcional) La ventana de contexto establece la extensión del período que el modelo consulta durante el entrenamiento (y para las previsiones). En otras palabras, para cada dato de entrenamiento, la ventana de contexto determina la extensión del período en el que el modelo busca patrones predictivos. Para obtener más información, consulta horizonte de previsión, ventana de contexto y ventana de previsión. |
window_max_count |
Integer | (Opcional) Vertex AI genera ventanas de previsión a partir de los datos de entrada mediante una estrategia de ventana progresiva. La estrategia predeterminada es Recuento. El valor predeterminado para la cantidad máxima de ventanas es 100,000,000. Establece este parámetro a fin de proporcionar un valor personalizado para la cantidad máxima de ventanas. Para obtener más información, consulta Estrategias de ventana progresiva. |
window_stride_length |
Integer | (Opcional) Vertex AI genera ventanas de previsión a partir de los datos de entrada mediante una estrategia de ventana progresiva. Para seleccionar la estrategia Segmentación, establece este parámetro en el valor de la longitud del segmentación. Para obtener más información, consulta Estrategias de ventana progresiva. |
window_predefined_column |
Cadena | (Opcional) Vertex AI genera ventanas de previsión a partir de los datos de entrada mediante una estrategia de ventana progresiva. Para seleccionar la estrategia Columna, establece este parámetro en el nombre de la columna con valores True o False. Para obtener más información, consulta Estrategias de ventana progresiva. |
holiday_regions |
List[str] | (Opcional) Puedes seleccionar una o más regiones geográficas para habilitar el modelado de efectos de festividades. Durante el entrenamiento, Vertex AI crea atributos categóricos para las festividades dentro del modelo en función de la fecha de time_column y las regiones geográficas especificadas. De forma predeterminada, el modelado de efectos de festividades está inhabilitado. Para obtener más información, consulta Regiones de festividades. |
predefined_split_key |
Cadena | De forma predeterminada, Vertex AI usa un algoritmo de división cronológica para separar los datos de previsión en las tres divisiones de datos. Si deseas controlar qué filas de datos de entrenamiento se usan para cada división, proporciona el nombre de la columna que contiene los valores de división de datos (TRAIN, VALIDATION y TEST). Si deseas obtener más información, consulta Divisiones de datos para la previsión. |
training_fraction |
Número de punto flotante | De forma predeterminada, Vertex AI usa un algoritmo de división cronológica para separar los datos de previsión en las tres divisiones de datos. El 80% de los datos se asigna al conjunto de entrenamiento, el 10% se asigna a la división de validación y el 10% a la división de prueba. Establece este parámetro si deseas personalizar la fracción de los datos asignados al conjunto de entrenamiento. Si deseas obtener más información, consulta Divisiones de datos para la previsión. |
validation_fraction |
Número de punto flotante | De forma predeterminada, Vertex AI usa un algoritmo de división cronológica para separar los datos de previsión en las tres divisiones de datos. El 80% de los datos se asigna al conjunto de entrenamiento, el 10% se asigna a la división de validación y el 10% a la división de prueba. Establece este parámetro si deseas personalizar la fracción de los datos asignados al conjunto de validación. Si deseas obtener más información, consulta Divisiones de datos para la previsión. |
test_fraction |
Número de punto flotante | De forma predeterminada, Vertex AI usa un algoritmo de división cronológica para separar los datos de previsión en las tres divisiones de datos. El 80% de los datos se asigna al conjunto de entrenamiento, el 10% se asigna a la división de validación y el 10% a la división de prueba. Establece este parámetro si deseas personalizar la fracción de los datos asignados al conjunto de prueba. Si deseas obtener más información, consulta Divisiones de datos para la previsión. |
data_source_csv_filenames |
Cadena | Un URI para un archivo CSV almacenado en Cloud Storage. |
data_source_bigquery_table_path |
Cadena | Un URI para una tabla de BigQuery. |
dataflow_service_account |
Cadena | Cuenta de servicio personalizada para ejecutar trabajos de Dataflow (opcional). El trabajo de Dataflow se puede configurar para usar IP privadas y una subred de VPC específica. Este parámetro actúa como una anulación para la cuenta de servicio predeterminada del trabajador de Dataflow. |
run_evaluation |
Booleano | Si se configura como True, Vertex AI evalúa el modelo de ensamble en la división de prueba. |
evaluated_examples_bigquery_path |
Cadena | La ruta del conjunto de datos de BigQuery que se usó durante la evaluación del modelo. El conjunto de datos sirve como destino para los ejemplos previstos. El valor del parámetro se debe establecer si run_evaluation se establece en True y debe tener el siguiente formato: bq://[PROJECT].[DATASET]. |
Transformaciones
Puedes proporcionar una asignación de diccionario de resoluciones automáticas o de tipo a las columnas de atributos. Los tipos admitidos son: automático, numérico, categórico, texto y marca de tiempo.
| Nombre del parámetro | Tipo | Definición |
|---|---|---|
transformations |
Dict[str, List[str]] | Asignación de diccionarios de resoluciones automáticas o de tipo |
El siguiente código proporciona una función auxiliar para propagar el parámetro transformations. También se muestra cómo puedes usar esta función para aplicar transformaciones automáticas a un conjunto de columnas definidas por una variable features.
def generate_transformation(
auto_column_names: Optional[List[str]]=None,
numeric_column_names: Optional[List[str]]=None,
categorical_column_names: Optional[List[str]]=None,
text_column_names: Optional[List[str]]=None,
timestamp_column_names: Optional[List[str]]=None,
) -> List[Dict[str, Any]]:
if auto_column_names is None:
auto_column_names = []
if numeric_column_names is None:
numeric_column_names = []
if categorical_column_names is None:
categorical_column_names = []
if text_column_names is None:
text_column_names = []
if timestamp_column_names is None:
timestamp_column_names = []
return {
"auto": auto_column_names,
"numeric": numeric_column_names,
"categorical": categorical_column_names,
"text": text_column_names,
"timestamp": timestamp_column_names,
}
transformations = generate_transformation(auto_column_names=features)
Para obtener más información sobre las transformaciones, consulta Tipos de datos y transformaciones.
Opciones de personalización del flujo de trabajo
Puedes personalizar el flujo de trabajo tabular para la previsión si defines valores de argumento que se pasan durante la definición de la canalización. Puedes personalizar tu flujo de trabajo de las siguientes maneras:
- Configura hardware
- Omitir la búsqueda de arquitectura
Configura hardware
El siguiente parámetro de entrenamiento de modelos te permite configurar los tipos de máquinas y la cantidad de máquinas para el entrenamiento. Esta es una buena opción si tienes un conjunto de datos grande y deseas optimizar el hardware de la máquina según corresponda.
| Nombre del parámetro | Tipo | Definición |
|---|---|---|
stage_1_tuner_worker_pool_specs_override |
Dict[String, Any] | La configuración personalizada de los tipos de máquinas y la cantidad de máquinas para entrenamiento (opcional). Este parámetro configura el componente automl-forecasting-stage-1-tuner de la canalización. |
En el siguiente código, se muestra cómo configurar el tipo de máquina n1-standard-8 para el nodo principal de TensorFlow y el tipo de máquina n1-standard-4 para el nodo evaluador de TensorFlow:
worker_pool_specs_override = [
{"machine_spec": {"machine_type": "n1-standard-8"}}, # override for TF chief node
{}, # override for TF worker node, since it's not used, leave it empty
{}, # override for TF ps node, since it's not used, leave it empty
{
"machine_spec": {
"machine_type": "n1-standard-4" # override for TF evaluator node
}
}
]
Omitir la búsqueda de arquitectura
En el siguiente parámetro de entrenamiento de modelos te permite ejecutar la canalización sin la búsqueda de arquitectura y proporcionar un conjunto de hiperparámetros de una ejecución de canalización anterior en su lugar.
| Nombre del parámetro | Tipo | Definición |
|---|---|---|
stage_1_tuning_result_artifact_uri |
Cadena | El URI del resultado del ajuste de hiperparámetros de una ejecución de canalización anterior (opcional). |
¿Qué sigue?
- Obtén información sobre las predicciones por lotes para los modelos de previsión.
- Obtén más información sobre los precios para el entrenamiento de modelos.