Il s'agit d'une introduction aux parcours des données tabulaires avec AutoML. Pour comprendre les principales différences entre AutoML et entraînement personnalisé, consultez la section Choisir une méthode d'entraînement.
Cas d'utilisation des données tabulaires
Imaginez que vous travaillez dans le service marketing d'un marchand en ligne. Avec votre équipe, vous créez un programme de diffusion d'e-mails personnalisés basé sur des personas de clients. Vous avez créé les personas et les e-mails marketing sont prêts pour diffusion. Vous devez maintenant créer un système qui classe les clients par personnage selon les préférences de vente et le comportement d'achat, même pour les nouveaux clients. Pour optimiser l'engagement client, vous souhaitez également prédire leurs habitudes d'achat afin de déterminer le meilleur moment pour envoyer les e-mails.
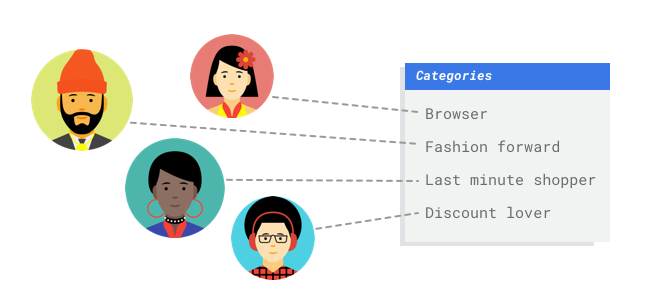
Grâce aux ventes en ligne, vous disposez de données sur vos clients et les achats qu'ils ont effectués. Mais qu'en est-il des nouveaux clients ? Les approches classiques peuvent calculer ces données pour les clients existants ayant de longs historiques d'achats, mais ne sont pas adaptées aux clients dont l'historique est récent. Et si vous pouviez créer un système permettant de prédire ces valeurs et de proposer plus rapidement des programmes marketing personnalisés à tous vos clients ?
Les systèmes de machine learning et Vertex AI constituent des outils adaptés pour répondre à ces questions.
Ce guide décrit le fonctionnement de Vertex AI pour les ensembles de données et les modèles AutoML, et illustre les types de problèmes que Vertex AI est conçu pour résoudre.
Comment fonctionne Vertex AI ?
 Vertex AI applique le machine learning supervisé pour obtenir le résultat souhaité.
Les spécificités de l'algorithme et les méthodes d'entraînement varient selon le type de données et le cas d'utilisation. Il existe de nombreuses sous-catégories de machine learning, qui résolvent toutes des problèmes différents et fonctionnent avec des contraintes variées.
Vertex AI applique le machine learning supervisé pour obtenir le résultat souhaité.
Les spécificités de l'algorithme et les méthodes d'entraînement varient selon le type de données et le cas d'utilisation. Il existe de nombreuses sous-catégories de machine learning, qui résolvent toutes des problèmes différents et fonctionnent avec des contraintes variées.
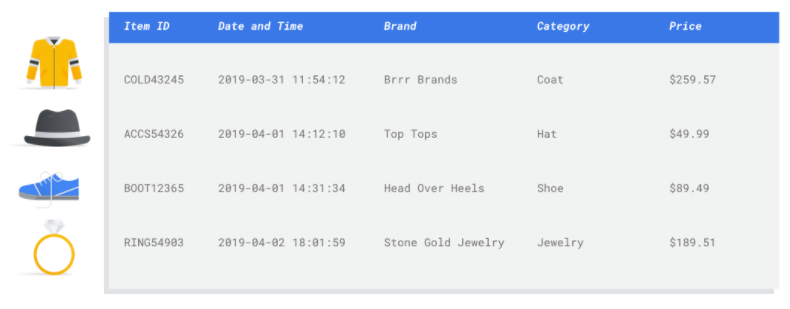
Vous entraînez un modèle de machine learning à l'aide d'exemples de données. Vertex AI utilise des données tabulaires (structurées) pour entraîner un modèle de machine learning à réaliser des prédictions sur de nouvelles données. Une colonne de votre ensemble de données, dénommée cible, indique ce que le modèle va apprendre à prédire. Parmi les autres colonnes de données, certaines contiennent des entrées (dénommées caractéristiques) à partir desquelles le modèle va identifier des tendances pour son apprentissage. Vous pouvez utiliser les mêmes caractéristiques d'entrée pour créer plusieurs types de modèles en modifiant simplement la colonne cible et les options d'entraînement. Dans l'exemple de marketing par e-mail, cela signifie que vous pouvez créer des modèles avec les mêmes caractéristiques d'entrée, mais avec des prédictions cibles différentes. Un modèle peut prédire le persona d'un client (cible catégorielle), un autre modèle peut prédire ses dépenses mensuelles (cible numérique), et un autre modèle peut prévoir la demande quotidienne de vos produits pour les trois prochains mois (séries de cibles numériques).
Workflow de Vertex AI
Vertex AI utilise un workflow de machine learning standard :
- Collecte de données : vous déterminez les données dont vous avez besoin pour entraîner et tester votre modèle en fonction du résultat que vous souhaitez obtenir.
- Préparation des données : vous vérifiez que vos données sont correctement formatées et étiquetées.
- Entraînement : vous définissez les paramètres et construisez votre modèle.
- Évaluation : vous examinez les métriques du modèle.
- Déploiement et prédiction : vous rendez votre modèle disponible à l'utilisation.
Avant de commencer à collecter des données, vous devez toutefois réfléchir au problème que vous essayez de résoudre. Cela vous permettra de déterminer vos besoins en termes de données.
Data preparation
Appréciation de votre cas d'utilisation
Commencez par réfléchir à votre problème : quel résultat souhaitez-vous obtenir ?
À quel type de données la colonne cible correspond-elle ? À quelle quantité de données avez-vous accès ? En fonction des réponses, Vertex AI crée le modèle nécessaire pour trouver une solution à votre cas d'utilisation :
- Les modèles de classification binaire prédisent un résultat binaire (l'une des deux classes). Utilisez ce type de modèle pour les questions fermées, c'est-à-dire dont la réponse peut être "oui" ou "non". Par exemple, vous pouvez créer un modèle de classification binaire pour prédire si un client achètera un abonnement. En règle générale, un problème de classification binaire nécessite moins de données que les autres types de modèle.
- Les modèles de classification à classes multiples prédisent une classe à partir de trois classes distinctes ou plus. Utilisez ce type de modèle pour la catégorisation. Par exemple, en tant que revendeur, vous pouvez créer un modèle de classification à classes multiples pour segmenter les clients en différents personas.
- Les modèles de régression prédisent une valeur continue. Par exemple, en tant que revendeur, vous pouvez créer un modèle de régression pour prédire le montant qu'un client dépensera le mois prochain.
- Les modèles de prévision prédisent une séquence de valeurs. Par exemple, en tant que revendeur, vous souhaitez peut-être prévoir la demande quotidienne de vos produits pour les trois prochains mois afin de pouvoir anticiper convenablement les stocks de produits nécessaires.
Les prévisions sur les données tabulaires diffèrent de la classification et de la régression de deux manières principales :
Dans la classification et la régression, la valeur prédite de la cible ne dépend que des valeurs des colonnes de caractéristiques sur la même ligne. Dans les prévisions, les valeurs prédites dépendent également des valeurs de contexte de la cible et des caractéristiques.
Dans les problèmes de régression et de classification, le résultat est une valeur. Dans les problèmes de prévision, le résultat est une séquence de valeurs.
Collecter les données
Une fois que vous avez établi votre cas d'utilisation, vous devez collecter les données qui vous permettront de créer le modèle souhaité.
 Une fois que vous avez établi votre cas d'utilisation, vous devez collecter des données pour entraîner votre modèle.
La collecte et la préparation des données sont des étapes essentielles dans la création d'un modèle de machine learning.
Les données dont vous disposez permettent de déterminer le type de problèmes que vous pouvez résoudre. De combien de données disposez-vous ? Sont-elles pertinentes pour les questions auxquelles vous tentez de répondre ? Lors de la collecte de données, gardez à l'esprit les considérations suivantes.
Une fois que vous avez établi votre cas d'utilisation, vous devez collecter des données pour entraîner votre modèle.
La collecte et la préparation des données sont des étapes essentielles dans la création d'un modèle de machine learning.
Les données dont vous disposez permettent de déterminer le type de problèmes que vous pouvez résoudre. De combien de données disposez-vous ? Sont-elles pertinentes pour les questions auxquelles vous tentez de répondre ? Lors de la collecte de données, gardez à l'esprit les considérations suivantes.
Sélectionner les caractéristiques pertinentes
Les caractéristiques sont des attributs d'entrée utilisés pour l'entraînement d'un modèle. Elles lui permettent d'identifier des tendances pour réaliser des prédictions. Leur pertinence par rapport à votre problème est donc importante. Par exemple, pour créer un modèle permettant de prédire si une transaction par carte de crédit est frauduleuse ou non, vous devez créer un ensemble de données contenant les détails de la transaction : acheteur, vendeur, montant, date et heure, et articles achetés. D'autres informations peuvent être utiles, telles que les données historiques de l'acheteur et du vendeur, et la fréquence à laquelle l'article acheté a été impliqué dans une fraude. Existe-t-il d'autres caractéristiques pouvant s'avérer pertinentes ?
Considérons le cas d'utilisation de marketing par e-mail du marchand présenté en introduction. Voici quelques colonnes de caractéristiques dont vous pourriez avoir besoin :
- Liste des articles achetés (y compris marques, catégories, prix, remises)
- Quantité d'articles achetés (jour précédent, semaine, mois, année)
- Somme d'argent dépensée (jour précédent, semaine, mois, année)
- Pour chaque article, nombre total de produits vendus chaque jour
- Pour chaque article, le total en stock chaque jour
- Si vous diffusez ou non une promotion certains jours
- Profil démographique connu de l'acheteur
Inclure suffisamment de données
 En général, plus vous avez d’exemples d'entraînement, meilleur sera le résultat. La quantité d'exemples de données nécessaires varie également en fonction de la complexité du problème que vous tentez de résoudre. Vous n'aurez pas besoin d'autant de données pour obtenir un modèle de classification binaire précis comparé à un modèle à classes multiples, car il est moins compliqué de prédire à partir de deux classes qu'à partir de plusieurs.
En général, plus vous avez d’exemples d'entraînement, meilleur sera le résultat. La quantité d'exemples de données nécessaires varie également en fonction de la complexité du problème que vous tentez de résoudre. Vous n'aurez pas besoin d'autant de données pour obtenir un modèle de classification binaire précis comparé à un modèle à classes multiples, car il est moins compliqué de prédire à partir de deux classes qu'à partir de plusieurs.
Si la formule parfaite n'existe pas, le nombre minimal conseillé d'exemples de données est le suivant :
- Problème de classification : nombre de caractéristiques x 50 lignes
- Problème de prévision :
- 5 000 lignes x nombre d'éléments de caractéristiques
- 10 valeurs uniques dans la colonne "Identifiant de série temporelle" x nombre de caractéristiques
- Problème de régression : nombre de caractéristiques x 200
Capturer les nuances
Votre ensemble de données doit capturer la diversité de votre espace-problème. Plus un modèle traite des exemples diversifiés au cours de son entraînement, plus il peut facilement se généraliser à des exemples nouveaux ou moins courants. Imaginez que votre modèle de vente au détail n'ait été entraîné que sur les données d'achat de l'hiver. Serait-il capable de prédire correctement les préférences de vêtements ou les comportements d'achat de l'été ?
Préparer vos données
 Une fois que vous avez identifié les données disponibles, vous devez vérifier qu'elles sont prêtes pour l'entraînement.
Si vos données sont biaisées ou comportent des valeurs manquantes ou erronées, cela affectera la qualité du modèle. Considérez ce qui suit avant de commencer à entraîner votre modèle.
En savoir plus
Une fois que vous avez identifié les données disponibles, vous devez vérifier qu'elles sont prêtes pour l'entraînement.
Si vos données sont biaisées ou comportent des valeurs manquantes ou erronées, cela affectera la qualité du modèle. Considérez ce qui suit avant de commencer à entraîner votre modèle.
En savoir plus
Prévenir les fuites de données et le décalage entraînement/diffusion
Une fuite de données se produit lorsque vous utilisez des caractéristiques d'entrée lors de l'entraînement qui "divulguent" des informations sur la cible que vous essayez de prédire, lesquelles ne sont pas disponibles lorsque le modèle est réellement diffusé. Cela peut être détecté lorsqu'une caractéristique fortement corrélée à la colonne cible est incluse parmi les caractéristiques d'entrée. Par exemple, si vous créez un modèle pour prédire si un client souscrira un abonnement le mois prochain et que l'une des caractéristiques d'entrée est un futur paiement d'abonnement de ce client. Les performances du modèle peuvent être très élevées lors des tests, mais de faible niveau lors du déploiement en production, car les informations de paiement d'abonnement futur ne sont pas disponibles au moment de la diffusion.
Le décalage entraînement/diffusion survient lorsque les caractéristiques d'entrée utilisées pendant l'entraînement diffèrent de celles fournies au modèle au moment de la diffusion, ce qui entraîne une baisse de qualité du modèle en production. Par exemple, créer un modèle de prédiction des températures par heure, mais l'entraîner avec des données ne contenant que des températures par semaine. Autre exemple : fournir les notes d'un élève dans les données d'entraînement pour prédire le décrochage scolaire, mais ne pas les inclure au moment de la diffusion.
Il est important de comprendre vos données d’entraînement pour prévenir les fuites de données et éviter tout décalage entraînement/diffusion :
- Avant d'utiliser des données, veillez à bien comprendre leur signification pour déterminer s'il convient de les utiliser comme caractéristiques.
- Vérifiez la corrélation dans l'onglet "Entraînement". Les corrélations élevées doivent être signalées pour examen.
- Décalage entraînement/diffusion : veillez à ne fournir au modèle que des caractéristiques d'entrée disponibles dans un format identique au moment de la diffusion.
Nettoyer les données manquantes, incomplètes et incohérentes
Il est fréquent que des valeurs manquantes et inexactes figurent dans les exemples de données. Prenez le temps d'examiner et, si possible, d'améliorer la qualité de vos données avant de les utiliser pour l'entraînement. Plus il y a de valeurs manquantes, moins les données seront utiles pour l'entraînement d'un modèle de machine learning.
- Vérifiez les valeurs manquantes dans vos données et corrigez-les si possible. Sinon, vous pouvez laisser la valeur vide si la colonne est définie comme pouvant être vide. Vertex AI peut gérer les valeurs manquantes, mais vous avez plus de chances d'obtenir des résultats optimaux si toutes les valeurs sont disponibles.
- Pour les prévisions, vérifiez que l'intervalle entre les lignes d'entraînement est cohérent. Vertex AI peut imputer les valeurs manquantes, mais vous avez plus de chances d'obtenir des résultats optimaux si toutes les lignes sont disponibles.
- Nettoyez vos données en corrigeant ou en supprimant les erreurs ou le bruit. Assurez leur cohérence : vérifiez l'orthographe, les abréviations et le formatage.
Analyser les données après l'importation
Vertex AI fournit une vue d'ensemble de votre ensemble de données après son importation. Examinez l'ensemble de données importé pour vérifier que chaque colonne comporte bien le type de variable correct. Vertex AI détecte automatiquement le type de variable en fonction des valeurs des colonnes, mais il est préférable de les examiner une par une. Vous devez également vérifier le paramètre de valeur vide de chaque colonne, qui détermine si la colonne peut contenir des valeurs manquantes ou NULL.
Entraîner le modèle
Une fois votre ensemble de données importé, l'étape suivante consiste à entraîner un modèle. Vertex AI génère un modèle de machine learning fiable avec les valeurs d’entraînement par défaut, mais vous pouvez ajuster certains paramètres en fonction de votre cas d'utilisation.
Sélectionnez autant de colonnes de caractéristiques que possible pour l'entraînement, mais examinez chacune d'entre elles afin d'être certain de leur pertinence pour l'entraînement. Tenez compte des éléments suivants dans votre sélection :
- Ne sélectionnez pas de colonnes de caractéristiques qui produiront du bruit, comme les colonnes d'identifiants attribuées de manière aléatoire contenant une valeur unique pour chaque ligne.
- Assurez-vous de bien comprendre chaque colonne de caractéristique et les valeurs correspondantes.
- Si vous créez plusieurs modèles à partir d'un ensemble de données, supprimez les colonnes cibles qui ne font pas partie du problème de prédiction en cours.
- Rappelez-vous les principes d'équité : entraînez-vous le modèle avec une caractéristique qui pourrait conduire à une prise de décision biaisée ou injuste pour des groupes marginalisés ?
Comment Vertex AI utilise l'ensemble de données
Votre ensemble de données sera divisé en trois : ensemble d'entraînement, ensemble de validation et ensemble de test. La répartition par défaut que Vertex AI applique dépend du type de modèle que vous entraînez. Vous pouvez également spécifier les répartitions (répartitions manuelles) si nécessaire. Pour en savoir plus, consultez la section À propos des répartitions de données pour les modèles AutoML.
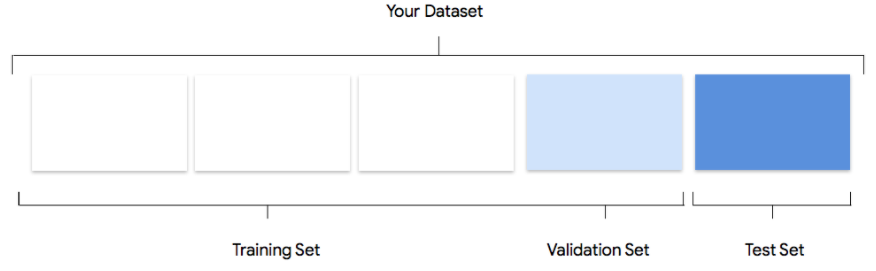
Ensemble d'entraînement
 La grande majorité de vos données doit figurer dans l'ensemble d'entraînement. Il s'agit des données auxquelles votre modèle accède pendant l'entraînement : elles sont utilisées pour apprendre les paramètres du modèle, à savoir la pondération des connexions entre les nœuds du réseau de neurones.
La grande majorité de vos données doit figurer dans l'ensemble d'entraînement. Il s'agit des données auxquelles votre modèle accède pendant l'entraînement : elles sont utilisées pour apprendre les paramètres du modèle, à savoir la pondération des connexions entre les nœuds du réseau de neurones.
Ensemble de validation
 L'ensemble de validation, parfois aussi appelé ensemble "dev", est également utilisé lors du processus d'entraînement.
Une fois que le framework d'apprentissage du modèle a incorporé les données d'entraînement à chaque itération du processus, il utilise les performances du modèle sur l'ensemble de validation pour ajuster ses hyperparamètres, qui sont des variables spécifiant sa structure. Si vous essayez d'utiliser l'ensemble d'entraînement pour régler les hyperparamètres, il est fort probable que le modèle finisse par trop se focaliser sur les données d'entraînement. Vous aurez alors du mal à généraliser le modèle à des exemples légèrement différents.
L'utilisation d'un ensemble de données relativement nouveau pour affiner la structure du modèle permet une meilleure généralisation du modèle à d'autres données.
L'ensemble de validation, parfois aussi appelé ensemble "dev", est également utilisé lors du processus d'entraînement.
Une fois que le framework d'apprentissage du modèle a incorporé les données d'entraînement à chaque itération du processus, il utilise les performances du modèle sur l'ensemble de validation pour ajuster ses hyperparamètres, qui sont des variables spécifiant sa structure. Si vous essayez d'utiliser l'ensemble d'entraînement pour régler les hyperparamètres, il est fort probable que le modèle finisse par trop se focaliser sur les données d'entraînement. Vous aurez alors du mal à généraliser le modèle à des exemples légèrement différents.
L'utilisation d'un ensemble de données relativement nouveau pour affiner la structure du modèle permet une meilleure généralisation du modèle à d'autres données.
Ensemble de test
 L'ensemble de test n'est pas du tout impliqué dans le processus d'entraînement. Une fois l'entraînement du modèle terminé, Vertex AI exploite l'ensemble de test qui représente un défi complètement nouveau pour le modèle.
Ses performances sur l'ensemble de test sont supposées vous fournir une idée plutôt fidèle de son comportement sur des données réelles.
L'ensemble de test n'est pas du tout impliqué dans le processus d'entraînement. Une fois l'entraînement du modèle terminé, Vertex AI exploite l'ensemble de test qui représente un défi complètement nouveau pour le modèle.
Ses performances sur l'ensemble de test sont supposées vous fournir une idée plutôt fidèle de son comportement sur des données réelles.
Évaluer, tester et déployer votre modèle
Évaluer le modèle
 Après avoir entraîné le modèle, vous recevez un résumé de ses performances. Les métriques d'évaluation du modèle sont basées sur ses performances par rapport à une tranche de l'ensemble de données (ensemble de données de test). Il existe plusieurs métriques et concepts clés à prendre en compte pour déterminer si votre modèle est prêt à traiter des données réelles.
Après avoir entraîné le modèle, vous recevez un résumé de ses performances. Les métriques d'évaluation du modèle sont basées sur ses performances par rapport à une tranche de l'ensemble de données (ensemble de données de test). Il existe plusieurs métriques et concepts clés à prendre en compte pour déterminer si votre modèle est prêt à traiter des données réelles.
Métriques de classification
Seuil de score
Examinons un modèle de machine learning qui prédit si un client achètera un blouson l’année prochaine. Quel doit être le degré de certitude du modèle avant de prédire qu'un client donné achètera un blouson ? Dans les modèles de classification, un score de confiance est attribué à chaque prédiction, soit une évaluation numérique de la certitude du modèle quant à l'exactitude de la classe prédite. Le seuil de score est la valeur numérique qui détermine le moment où un score donné est converti en une décision positive ou négative, c'est-à-dire la valeur à laquelle le modèle indique "oui, ce score de confiance est suffisamment élevé pour conclure que ce client achètera un blouson au cours de la prochaine année".
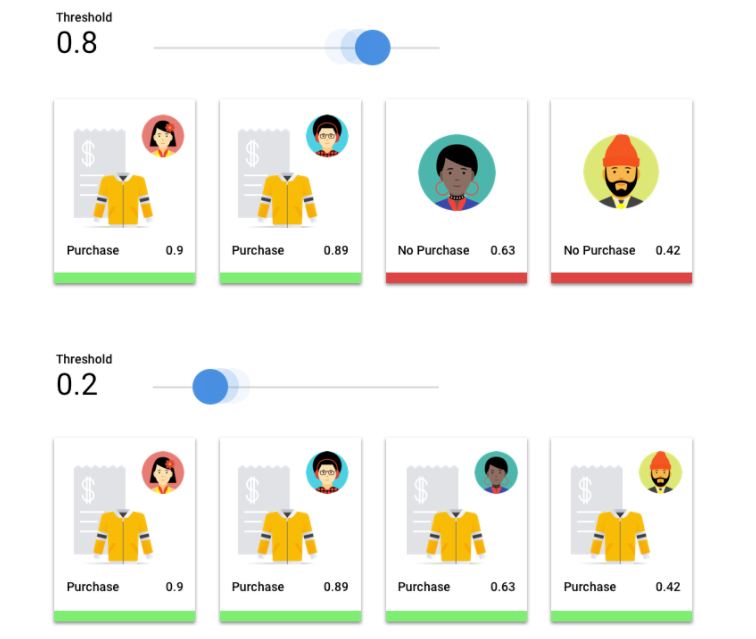
Si votre seuil de score est bas, votre modèle risque de générer des erreurs de classification. C'est pourquoi ce seuil devrait être déterminé en fonction d'un cas d'utilisation donné.
Résultats de prédiction
Après l'application du seuil de score, les prédictions effectuées par votre modèle entrent dans l'une des quatre catégories ci-dessous. Pour comprendre ces catégories, imaginons à nouveau un modèle de classification binaire pour un blouson. Dans cet exemple, la classe positive (ce que le modèle tente de prédire) est que le client achètera un blouson l'année prochaine.
- Vrai positif : le modèle prédit correctement la classe positive. Le modèle a correctement prédit qu'un client allait acheter un blouson.
- Faux positif : le modèle prédit incorrectement la classe positive. Le modèle a prédit qu'un client allait acheter un blouson, ce qu'il n'a pas fait.
- Vrai négatif : le modèle prédit correctement la classe négative. Le modèle a correctement prédit qu'un client n'allait pas acheter de blouson.
- Faux négatif : le modèle prédit incorrectement une classe négative. Le modèle a prédit qu'un client n'allait pas acheter de blouson, or c'est ce qu'il a fait.

Précision et rappel
Les métriques de précision et de rappel permettent d'évaluer la capacité de votre modèle à capturer des informations et à en laisser certaines de côté. En savoir plus sur la précision et le rappel.
- La précision est la fraction des prédictions positives qui étaient correctes. Quelle était la fraction d'achats réels de toutes les prédictions d'achat d'un client ?
- Le rappel est la fraction des lignes comportant cette étiquette que le modèle a correctement prédites. Quelle était la fraction de tous les achats clients qui auraient pu être identifiés ?
Selon votre cas d'utilisation, vous devrez peut-être optimiser la précision ou le rappel.
Autres métriques de classification
- AUC PR : aire sous la courbe de précision/rappel (PR). Cette valeur est comprise entre zéro et un. Plus elle est élevée, plus le modèle est de bonne qualité.
- AUC ROC : aire sous la courbe ROC (Receiver Operating Characteristic). Cette valeur est comprise entre zéro et un. Plus elle est élevée, plus le modèle est de bonne qualité.
- Justesse : fraction des prédictions de classification produites par le modèle qui étaient correctes.
- Perte logistique : entropie croisée entre les prédictions du modèle et les valeurs cibles. Cette valeur varie de zéro à l'infini. Plus elle est faible, plus le modèle est de bonne qualité.
- Score F1 : moyenne harmonique de la précision et du rappel. F1 est une métrique utile si vous souhaitez équilibrer précision et rappel, et que les classes sont réparties de façon inégale.
Métriques de prévision et de régression
Une fois votre modèle créé, Vertex AI fournit une variété de métriques standards que vous pouvez examiner. Il n'existe pas de réponse parfaite quant à la façon d'évaluer un modèle. Considérez les métriques d'évaluation dans le contexte de votre type de problème et de ce que vous souhaitez obtenir avec votre modèle. La liste suivante présente certaines métriques que Vertex AI peut fournir.
Erreur absolue moyenne (EAM)
L'EAM correspond à l'écart absolu moyen entre les valeurs cibles et les valeurs prédites. Cette métrique mesure la magnitude moyenne des erreurs dans un ensemble de prédictions, soit la différence entre une valeur cible et une valeur prédite. En outre, comme elle utilise des valeurs absolues, l'EAM ne prend pas en compte l'orientation de la relation et n'indique ni sous-performance, ni surperformance. Lors de l'évaluation de l'EAM, une valeur inférieure indique un modèle de qualité supérieure (0 représentant un prédicteur parfait).
Racine carrée de l'erreur quadratique moyenne (RMSE)
La RMSE correspond à la racine carrée de l'écart moyen au carré entre la valeur cible et la valeur prédite. La RMSE est plus sensible aux anomalies que l'EAM. Par conséquent, si vous craignez des erreurs importantes, cette métrique est sans doute plus utile pour procéder à une évaluation. Comme pour l'EAM, une valeur inférieure indique un modèle de qualité supérieure (0 représentant un prédicteur parfait).
Erreur logarithmique quadratique moyenne (RMSLE)
La RMSLE est équivalente à la RMSE sur une échelle logarithmique. La RMSLE est plus sensible aux erreurs relatives qu'aux erreurs absolues et se focalise davantage sur la sous-performance que sur la surperformance.
Quantile observé (prévisions uniquement)
Pour un quantile cible donné, le quantile observé indique la fraction réelle des valeurs observées en dessous des valeurs de prédiction des quantiles spécifiées. Le quantile observé montre à quel point le modèle est éloigné ou proche du quantile cible. Une différence plus faible entre les deux valeurs indique un modèle de meilleure qualité.
Perte pinball mise à l'échelle (prévision uniquement)
Mesure la qualité d'un modèle à un quantile cible donné. Plus le nombre est faible, plus le modèle est de bonne qualité. Vous pouvez comparer la métrique de perte pinball mise à l'échelle à différents quantiles pour déterminer la justesse relative de votre modèle entre ces différents quantiles.
Tester votre modèle
L'évaluation des métriques de votre modèle consiste principalement à déterminer s'il est prêt à être déployé, mais vous pouvez également le tester avec de nouvelles données. Importez d'autres données pour vérifier si les prédictions du modèle correspondent à vos attentes. En fonction des métriques d'évaluation ou des tests avec de nouvelles données, vous devrez peut-être continuer à améliorer les performances du modèle.
Déployer le modèle
Lorsque vous êtes satisfait des performances de votre modèle, il est temps de l'utiliser dans la réalité. Quel que soit votre cas d'utilisation, qu'il s'agisse de l'appliquer en production ou de traiter une requête de prédiction unique, vous pouvez exploiter votre modèle de différentes manières.
Prédiction par lot
La prédiction par lot est utile pour effectuer plusieurs requêtes de prédiction à la fois. La prédiction par lot est asynchrone, c'est-à-dire que le modèle attend d'avoir traité toutes les requêtes de prédiction avant de renvoyer un fichier CSV ou une table BiqQuery contenant les valeurs de prédiction.
Prédiction en ligne
Déployez votre modèle pour le rendre disponible aux requêtes de prédiction à l'aide d'une API REST. Les prédictions en ligne sont synchrones (en temps réel), ce qui signifie qu'elles sont renvoyées rapidement, mais le système n'accepte qu'une seule requête de prédiction par appel de l'API. Les prédictions en ligne sont utiles si votre modèle est intégré à une application et que certaines parties de votre système dépendent d'une résolution rapide des prédictions.
Effectuer un nettoyage
Pour éviter des frais inutiles, annulez le déploiement de votre modèle lorsqu'il n'est pas utilisé.
Lorsque vous avez terminé d'utiliser votre modèle, supprimez les ressources que vous avez créées pour éviter que des frais inutiles ne soient facturés sur votre compte.
- Données d'images Hello : nettoyer votre projet
- Données tabulaires Hello : nettoyer votre projet
- Données textuelles Hello : nettoyer votre projet
- Données vidéo Hello : nettoyer votre projet