In diesem Leitfaden wird gezeigt, wie Sie einen Vertex AI Neural Architecture Search-Job ausführen, indem Sie die von Google vorgefertigten Suchbereiche und den vorgefertigten Trainer-Code basierend auf TF-Vision für MnasNet und SpineNet verwenden. End-to-End-Beispiele finden Sie im MnasNet-Notebook zur Klassifizierung und im SpineNet-Notebook zur Objekterkennung.
Datenvorbereitung für den vordefinierten Trainer
Für den vorgefertigten Neural Architecture Search-Trainer müssen Ihre Daten im Format TFRecord vorliegen und tf.train.Examples enthalten. Die tf.train.Examples müssen die folgenden Felder enthalten:
'image/encoded': tf.FixedLenFeature(tf.string)
'image/height': tf.FixedLenFeature(tf.int64)
'image/width': tf.FixedLenFeature(tf.int64)
# For image classification only.
'image/class/label': tf.FixedLenFeature(tf.int64)
# For object detection only.
'image/object/bbox/xmin': tf.VarLenFeature(tf.float32)
'image/object/bbox/xmax': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymin': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymax': tf.VarLenFeature(tf.float32)
'image/object/class/label': tf.VarLenFeature(tf.int64)
Folgen Sie der Anleitung zur Vorbereitung von ImageNet-Daten.
Verwenden Sie zum Konvertieren Ihrer benutzerdefinierten Daten das Parsing-Script, das im Beispielcode und den heruntergeladenen Dienstprogrammen enthalten ist. Ändern Sie die Dateien tf_vision/dataloaders/*_input.py, um das Datenparsen anzupassen.
Weitere Informationen zu
TFRecord und tf.train.Example.
Testumgebungsvariablen definieren
Bevor Sie Ihre Tests ausführen, müssen Sie mehrere Umgebungsvariablen definieren, darunter:
- TRAINER_DOCKER_ID:
${USER}_nas_experiment(empfohlenes Format) Cloud Storage-Speicherorte Ihrer Trainings- und Validierungs-Datasets, die vom Test verwendet werden. Beispiel (CoCo zur Erkennung):
gs://cloud-samples-data/ai-platform/built-in/image/coco/train*gs://cloud-samples-data/ai-platform/built-in/image/coco/val*
Cloud Storage-Ort für die Testausgabe. Empfohlenes Format:
gs://${USER}_nas_experiment
REGION: Eine Region, die Ihrer Region im Testausgabe-Bucket entsprechen sollte. Beispiel:
us-central1.PARAM_OVERRIDE: Eine .yaml-Datei, die Parameter des vordefinierten Trainers überschreibt. Die Neural Architecture Search bietet einige Standardkonfigurationen, die Sie verwenden können:
PROJECT_ID=PROJECT_ID
TRAINER_DOCKER_ID=TRAINER_DOCKER_ID
LATENCY_CALCULATOR_DOCKER_ID=LATENCY_CALCULATOR_DOCKER_ID
GCS_ROOT_DIR=OUTPUT_DIR
REGION=REGION
PARAM_OVERRIDE=tf_vision/configs/experiments/spinenet_search_gpu.yaml
TRAINING_DATA_PATH=gs://PATH_TO_TRAINING_DATA
VALIDATION_DATA_PATH=gs://PATH_TO_VALIDATION_DATA
Sie können die Überschreibungsdatei, die Ihren Trainingsanforderungen entspricht, auswählen und/oder ändern. Beachten Sie dabei Folgendes:
- Sie können
--accelerator_typefestlegen, um aus GPU oder CPU zu wählen. Wenn Sie nur einige wenige Epochen für schnelle Tests mit der CPU ausführen möchten, können Sie das Flag--accelerator_type=""festlegen und die Konfigurationsdateitf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yamlverwenden. - Anzahl der Epochen
- Trainingslaufzeit
- Hyperparameter wie die Lernrate
Eine Liste aller Parameter zur Steuerung der Trainingsjobs finden Sie unter tf_vision/configs/. Im Folgenden sind die wichtigsten Parameter aufgeführt:
task:
train_data:
global_batch_size: 80
validation_data:
global_batch_size: 16
init_checkpoint: null
trainer:
train_steps: 16634
steps_per_loop: 1386
optimizer_config:
learning_rate:
cosine:
initial_learning_rate: 0.16
decay_steps: 16634
type: 'cosine'
warmup:
type: 'linear'
linear:
warmup_learning_rate: 0.0067
warmup_steps: 1386
Erstellen Sie einen Cloud Storage-Bucket für die Suche in der neuronalen Architektur, um Ihre Jobausgaben zu speichern (d. h. Prüfpunkte):
gsutil mkdir $GCS_ROOT_DIR
Trainercontainer und Latenzrechner-Container erstellen
Mit dem folgenden Befehl wird in Google Cloud ein Trainer-Image mit dem URI gcr.io/PROJECT_ID/TRAINER_DOCKER_ID erstellt, der im nächsten Schritt im Neural Architecture Search-Job verwendet wird.
python3 vertex_nas_cli.py build \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--latency_calculator_docker_id=LATENCY_CALCULATOR_DOCKER_ID \
--trainer_docker_file=tf_vision/nas_multi_trial.Dockerfile \
--latency_calculator_docker_file=tf_vision/latency_computation_using_saved_model.Dockerfile
Wenn Sie den Suchbereich und die Prämien ändern möchten, aktualisieren Sie diese in der Python-Datei und erstellen Sie das Docker-Image neu.
Trainer lokal testen
Da das Starten eines Jobs im Google Cloud-Dienst einige Minuten dauert, ist es möglicherweise einfacher, den Trainer-Docker lokal zu testen, z. B. durch die Validierung des TFRecord-Formats. Verwenden Sie den Suchbereich spinenet als Beispiel. Sie können den Suchjob lokal ausführen (das Modell wird nach dem Zufallsprinzip erfasst):
# Define the local job output dir.
JOB_DIR="/tmp/iod_${search_space}"
python3 vertex_nas_cli.py search_in_local \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--prebuilt_search_space=spinenet \
--use_prebuilt_trainer=True \
--local_output_dir=${JOB_DIR} \
--search_docker_flags \
params_override="tf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yaml" \
training_data_path=TEST_COCO_TF_RECORD \
validation_data_path=TEST_COCO_TF_RECORD \
model=retinanet
Die training_data_path und validation_data_path sind die Pfade zu Ihren TFRecords.
stage-1-Suche gefolgt von einem stage-2-Trainingsjob in Google Cloud starten
End-to-End-Beispiele finden Sie im MnasNet-Notebook zur Klassifizierung und im SpineNet-Notebook zur Objekterkennung.
Sie können das Flag
--max_parallel_nas_trialund--max_nas_trialzum Anpassen festlegen. Die Neural Architecture Search startetmax_parallel_nas_trial-Tests parallel und endet nachmax_nas_trial-Tests.Wenn das Flag
--target_device_latency_msfestgelegt ist, wird ein separaterlatency calculator-Job mit dem Beschleuniger gestartet, der durch das Flag--target_device_typeangegeben wird.Der Neural Architecture Search Controller stellt jedem Test einen Vorschlag für einen neuen Architekturkandidaten über das FLAG
--nas_params_strbereit.Bei jedem Test wird ein Diagramm mit dem Wert des FLAG
nas_params_strerstellt und ein Trainingsjob gestartet. Bei jedem Test wird außerdem der Wert in einer JSON-Datei gespeichert (unteros.path.join(nas_job_dir, str(trial_id), "nas_params_str.json")).
Latenzbeschränkung als Prämie
Das MnasNet-Notebook zur Klassifizierung zeigt ein Beispiel für eine auf Cloud-CPU-Geräten basierende latenzbeschränkte Suche.
Wenn Sie Modelle mit Latenzbeschränkung suchen, kann der Trainer als Prämien sowohl die Genauigkeit als auch die Latenz melden.
Im freigegebenen Quellcode wird die Prämie so berechnet:
def compute_reward(target_latency, accuracy, inference_latency, weight=0.07):
"""Compute reward from accuracy and latency."""
speed_ratio = target_latency / inference_latency
return accuracy * (speed_ratio**weight)
Sie können andere Varianten der reward-Berechnung auf Seite 3 des Mnasnet-Papiers verwenden.
target_device_typegibt den Zielgerätetyp an, der in Google Cloud unterstützt wird, z. B.NVIDIA_TESLA_P100.use_prebuilt_latency_calculatorverwendet unseren vordefinierten Latenzrechnertf_vision/latency_computation_using_saved_model.py.target_device_latency_msgibt die Latenz des Zielgeräts an.
Informationen zum Anpassen der Funktion zur Latenzberechnung finden Sie unter tf_vision/latency_computation_using_saved_model.py.
Fortschritt von Neural Architecture Search-Jobs überwachen
In der Google Cloud Console wird auf der Jobseite im Diagramm der reward vs. trial number angezeigt, während in der Tabelle die Prämien für jeden Test angezeigt werden. Sie finden die Top-Tests mit der höchsten Prämie.
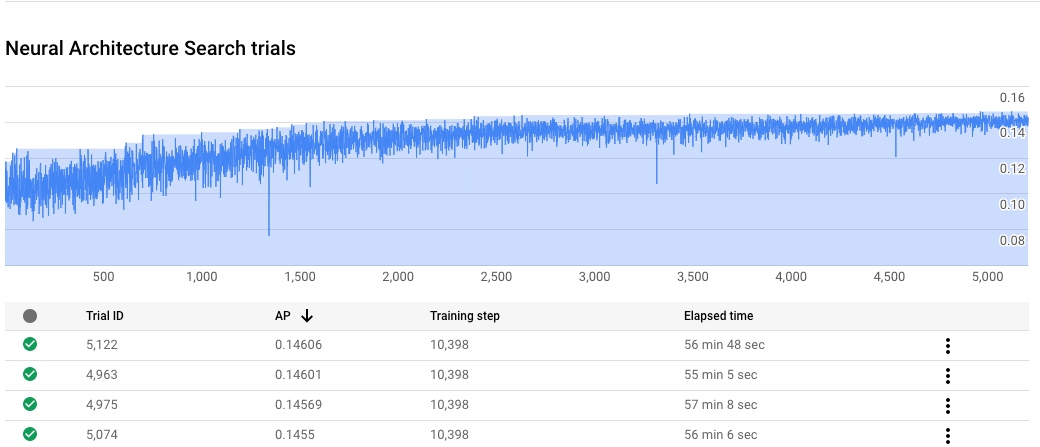
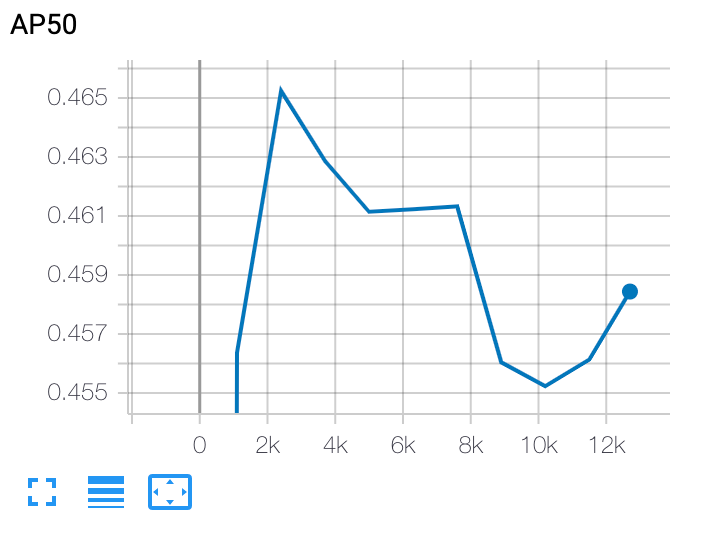
stage-2-Trainingskurve darstellen
Nach dem stage-2-Training verwenden Sie entweder Cloud Shell oder TensorBoard von Google Cloud, um die Trainingskurve darzustellen, indem Sie sie auf das Jobverzeichnis verweisen lassen:
Ausgewähltes Modell bereitstellen
Zum Erstellen eines SavedModel können Sie das Skript export_saved_model.py mit params_override=${GCS_ROOT_DIR}/${TRIAL_ID}/params.yaml verwenden.