Sebelum menjalankan tugas Penelusuran Arsitektur Neural untuk menelusuri model yang optimal, tentukan tugas proxy Anda. Penelusuran Tahap 1 menggunakan representasi pelatihan model lengkap yang jauh lebih kecil, yang biasanya selesai dalam waktu dua jam. Representasi ini disebut tugas proxy dan mengurangi biaya penelusuran secara signifikan. Setiap uji coba selama penelusuran akan melatih model menggunakan setelan tugas proxy.
Bagian berikut menjelaskan hal-hal yang terlibat dalam menerapkan desain tugas proxy:
- Pendekatan untuk membuat tugas proxy.
- Persyaratan tugas proxy yang baik.
- Cara menggunakan tiga alat desain tugas proxy untuk menemukan tugas proxy optimal, yang menurunkan biaya penelusuran dan sekaligus mempertahankan kualitas penelusuran.
Pendekatan untuk membuat tugas proxy
Ada tiga pendekatan umum untuk membuat tugas proxy, yang meliputi:
- Menggunakan lebih sedikit langkah pelatihan.
- Menggunakan set data pelatihan sub-sampel.
- Menggunakan model dengan skala yang diperkecil.
Menggunakan lebih sedikit langkah pelatihan
Cara paling sederhana untuk membuat tugas proxy adalah mengurangi jumlah langkah pelatihan untuk pelatih Anda dan melaporkan kembali skor ke pengontrol berdasarkan pelatihan parsial ini.
Menggunakan set data pelatihan sub-sampel.
Bagian ini menjelaskan penggunaan set data pelatihan subsampel untuk penelusuran arsitektur dan penelusuran kebijakan augmentasi.
Penelusuran arsitektur
Tugas proxy dapat dibuat menggunakan set data pelatihan dengan subsampel selama penelusuran arsitektur. Namun, saat subsampling ikuti panduan berikut:
- Shuffle data secara acak di antara shard.
- Jika data pelatihan tidak seimbang, lakukan subsampling untuk menyeimbangkannya.
Meningkatkan penelusuran kebijakan menggunakan augmentasi otomatis
Lewati bagian ini jika Anda tidak menjalankan penelusuran khusus augmentasi dan hanya menjalankan penelusuran arsitektur reguler. Gunakan augmentasi otomatis untuk menelusuri kebijakan augmentasi. Sebaiknya lakukan subsampling data pelatihan dan jalankan pelatihan penuh daripada mengurangi jumlah langkah pelatihan. Menjalankan pelatihan penuh dengan augmentasi berat akan menjaga skor lebih stabil. Selain itu, gunakan pengurangan data pelatihan untuk menekan biaya penelusuran.
Tugas proxy berdasarkan model yang skalanya diperkecil
Anda juga dapat memperkecil skala model secara relatif terhadap model dasar pengukuran untuk membuat tugas proxy. Hal ini juga dapat berguna saat Anda ingin memisahkan penelusuran desain blok dari penelusuran penskalaan.
Namun, saat Anda memperkecil skala model dan ingin menggunakan batasan latensi, gunakan batasan latensi yang lebih ketat untuk model yang skalanya diperkecil. Petunjuk: Anda dapat memperkecil skala model dasar pengukuran dan mengukur latensinya untuk menetapkan batasan latensi yang lebih ketat ini.
Untuk model yang skalanya diperkecil, Anda juga dapat mengurangi jumlah augmentasi dan regularisasi dibandingkan dengan model dasar pengukuran yang asli.
Contoh model yang diperkecil skalanya
Untuk tugas computer vision tempat Anda melatih image, ada tiga cara umum untuk memperkecil skala model:
- Mengurangi lebar model: Sejumlah saluran.
- Mengurangi kedalaman model: Sejumlah lapisan dan blok berulang.
- Mengurangi sedikit ukuran image pelatihan (agar tidak menghilangkan fitur) atau memangkas image pelatihan jika diizinkan oleh tugas Anda.
Pembacaan yang disarankan: Dokumen EfficientNet memberikan insight yang bagus tentang penskalaan model untuk tugas computer vision. Dokumen ini juga menjelaskan keterkaitan ketiga cara penskalaan tersebut.
Penelusuran Spinenet adalah contoh lain dari penskalaan model yang digunakan dengan Penelusuran Arsitektur Neural. Untuk penelusuran tahap 1, jumlah saluran dan ukuran image akan diperkecil skalanya.
Tugas proxy berdasarkan kombinasi
Pendekatan ini berfungsi secara independen dan dapat digabungkan dalam tingkat yang berbeda untuk membuat tugas proxy.
Persyaratan tugas proxy yang baik
Tugas proxy harus memenuhi persyaratan tertentu sebelum dapat mengembalikan reward yang stabil ke pengontrol dan menjaga kualitas penelusuran.
Korelasi peringkat antara penelusuran tahap 1 dan pelatihan penuh tahap 2
Saat menggunakan tugas proxy untuk Penelusuran Arsitektur Neural, asumsi utama untuk keberhasilan penelusuran adalah jika model-A memiliki performa lebih baik daripada model-B selama pelatihan tugas proxy tahap 1, model-A memiliki performa lebih baik daripada model-B untuk pelatihan penuh tahap 2. Untuk memvalidasi asumsi ini, Anda harus mengevaluasi korelasi peringkat antara reward penelusuran tahap 1 dan pelatihan penuh tahap 2 pada sekitar 10-20 model di ruang penelusuran Anda. Model ini disebut model korelasi-kandidat.
Gambar di bawah menunjukkan contoh korelasi yang buruk (skor korelasi = -0,03), yang menjadikan tugas proxy ini kandidat yang buruk untuk penelusuran:
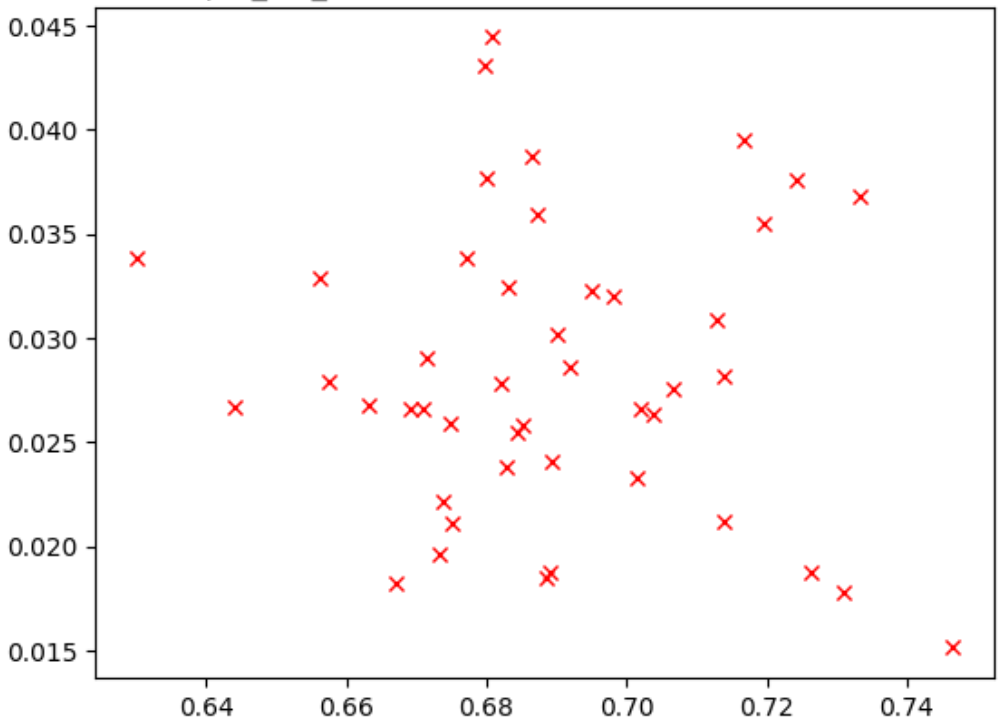
Setiap poin dalam plot mewakili model korelasi-kandidat.
Sumbu x merepresentasikan skor pelatihan penuh tahap 2 untuk model
dan sumbu y mewakili skor tugas proxy tahap 1 untuk model yang sama.
Amati poin tertinggi. Model ini
memberikan skor tugas proxy tertinggi (sumbu y), tetapi memiliki performa buruk selama
pelatihan penuh tahap 2 (sumbu x) dibandingkan dengan model lain. Sebaliknya,
gambar di bawah menunjukkan contoh korelasi yang baik
(skor korelasi = 0,67) yang menjadikan tugas proxy ini
kandidat yang cocok untuk penelusuran:
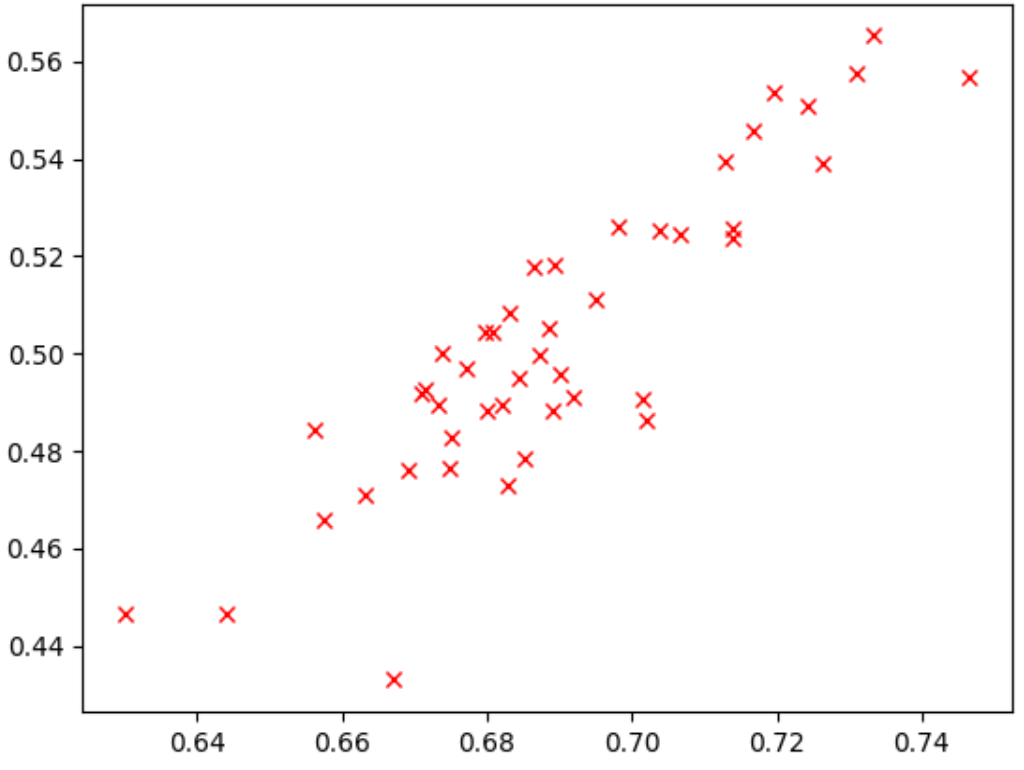
Jika penelusuran Anda melibatkan batasan latensi, verifikasi juga korelasi yang baik untuk nilai latensi.
Perhatikan bahwa reward model korelasi-kandidat memiliki rentang reward yang baik dan sampling rentang reward yang memadai. Jika tidak, Anda tidak dapat mengevaluasi korelasi peringkat. Misalnya, jika semua reward tahap 1 model korelasi-kandidat dipusatkan hanya di sekitar dua nilai: 0,9 dan 0,1, variasi sampling yang dihasilkan tidak akan cukup.
Pemeriksaan varians
Persyaratan lain dari tugas proxy adalah tidak boleh memiliki variasi besar dalam akurasi atau skor latensinya saat diulang beberapa kali untuk model yang sama tanpa perubahan apa pun. Jika ini terjadi, sinyal bising akan dikirimkan ke pengontrol. Alat untuk mengukur varians ini telah disediakan.
Contoh diberikan untuk memitigasi varians yang besar
selama pelatihan. Salah satu caranya adalah menggunakan cosine decay sebagai jadwal kecepatan
pembelajaran. Plot berikut membandingkan tiga strategi kecepatan pembelajaran:
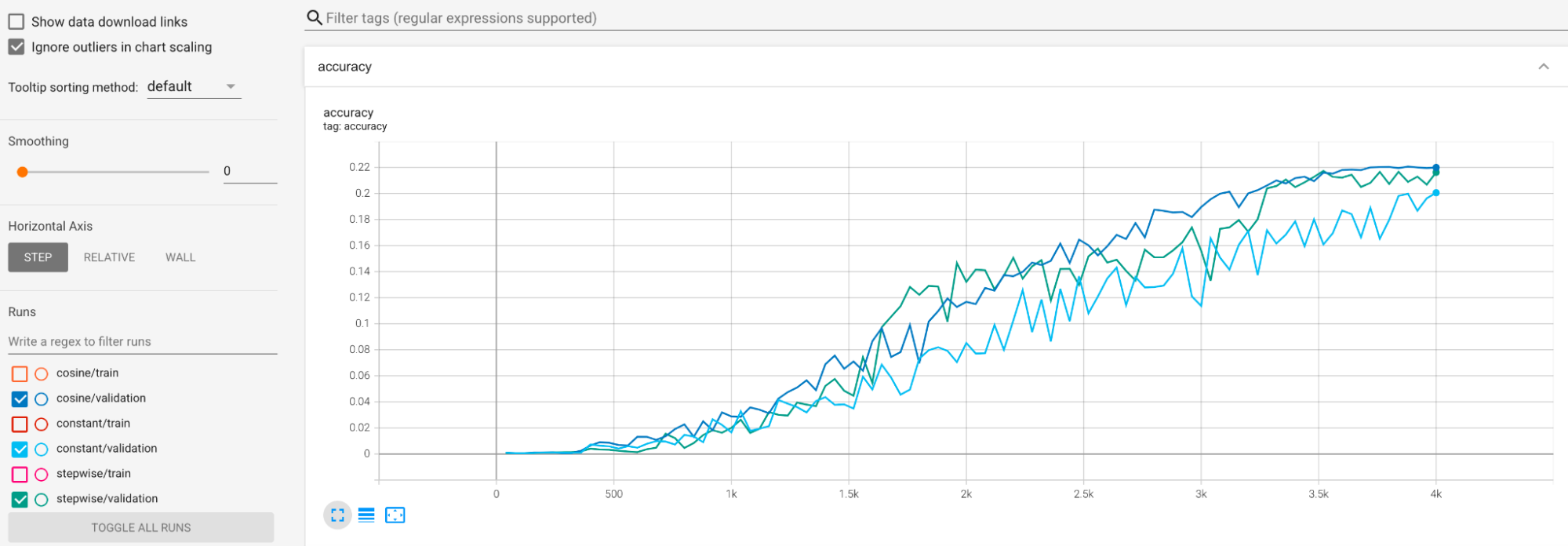
Plot terendah sesuai dengan kecepatan pembelajaran yang konstan. Ketika skor berubah-ubah di akhir pelatihan, perubahan kecil pada pilihan jumlah langkah pelatihan yang dikurangi dapat menyebabkan perubahan besar pada reward tugas proxy akhir. Agar reward tugas proxy lebih stabil, sebaiknya gunakan peluruhan kecepatan pembelajaran kosinus seperti ditunjukkan oleh skor validasi yang sesuai pada plot tertinggi. Perhatikan bagaimana plot tertinggi menjadi lebih lancar menjelang akhir pelatihan. Plot tengah menunjukkan skor yang sesuai dengan peluruhan kecepatan pembelajaran bertahap. Hal ini lebih baik daripada laju konstan, tetapi masih tidak semulus peluruhan kosinus dan juga memerlukan penyesuaian manual.
Jadwal kecepatan pembelajaran ditampilkan di bawah:
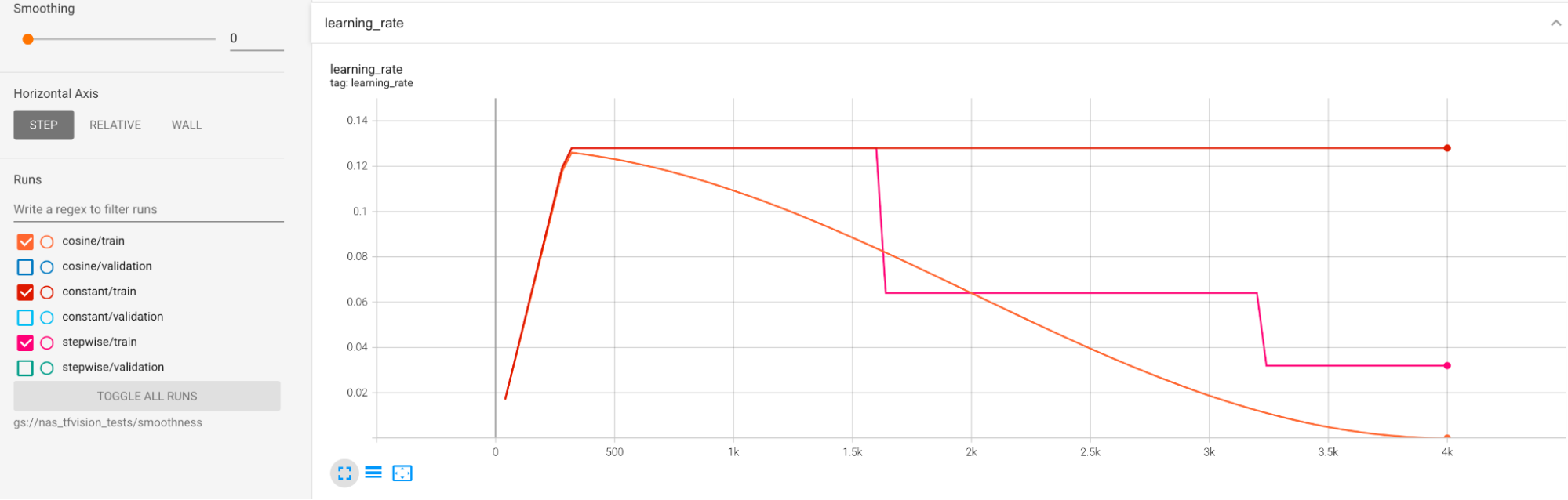
Penghalusan tambahan
Jika menggunakan augmentasi berat, kurva validasi Anda mungkin tidak akan cukup lancar dengan peluruhan kosinus. Penggunaan augmentasi berat menunjukkan kurangnya data pelatihan. Dalam hal ini, penggunaan Penelusuran Arsitektur Neural tidak direkomendasikan, dan sebaiknya gunakan penelusuran augmentasi.
Jika augmentasi berat bukan merupakan penyebabnya dan Anda telah mencoba peluruhan kosinus, tetapi masih ingin mencapai kelancaran yang lebih besar, gunakan rata-rata pergerakan eksponensial untuk TensorFlow-2 atau rata-rata bobot stokastik untuk PyTorch. Lihat pointer kode ini untuk mengetahui contoh yang menggunakan pengoptimal rata-rata pergerakan eksponensial dengan TensorFlow 2, dan lihat contoh rata-rata tertimbang stokastik untuk PyTorch.
Jika grafik akurasi/epoch untuk uji coba tampak seperti ini:
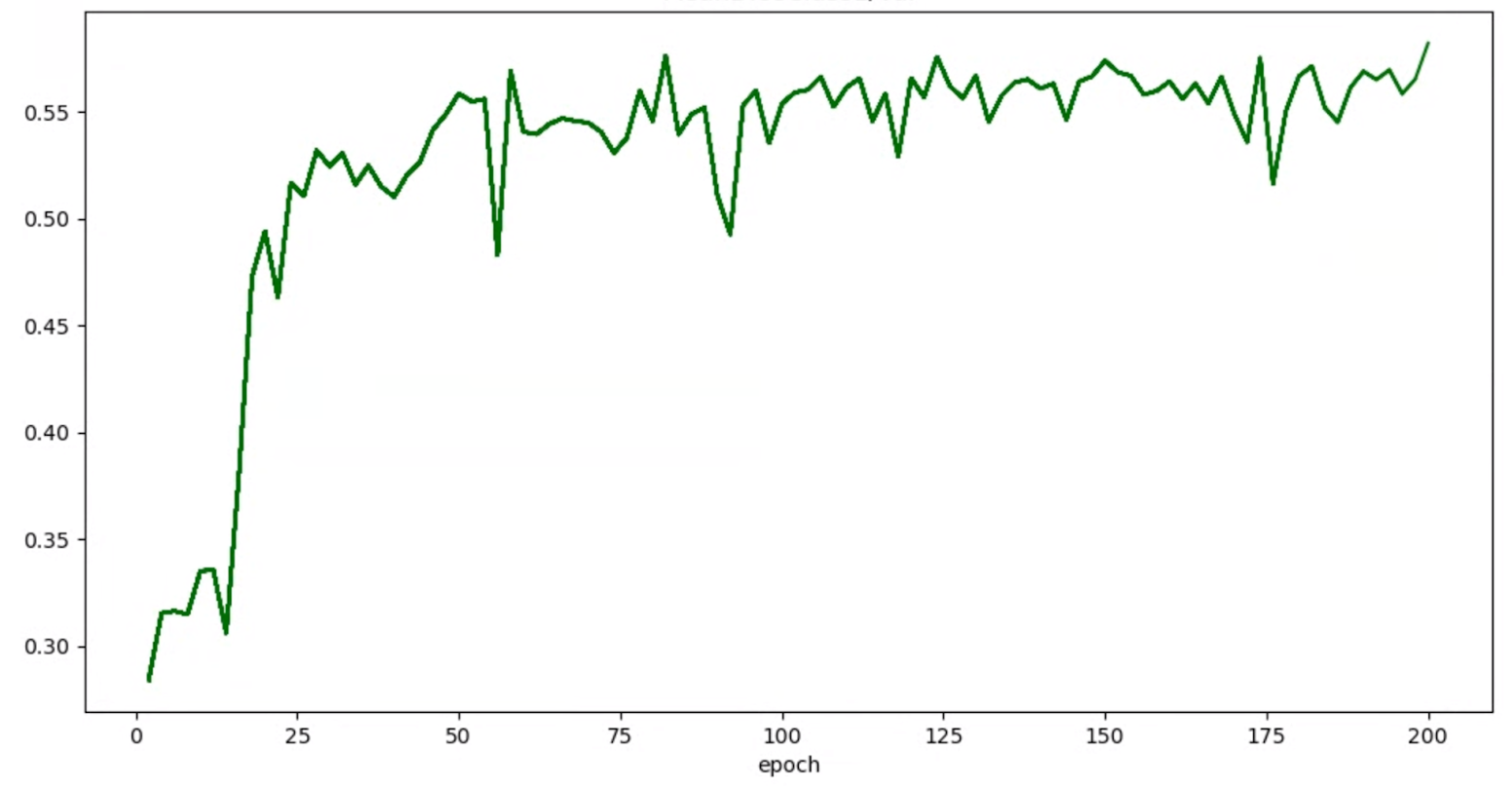
Anda dapat menerapkan teknik penghalusan yang disebutkan di atas (seperti rata-rata tertimbang stokastik atau menggunakan rata-rata pergerakan eksponensial) untuk mendapatkan grafik yang lebih konsisten, seperti:
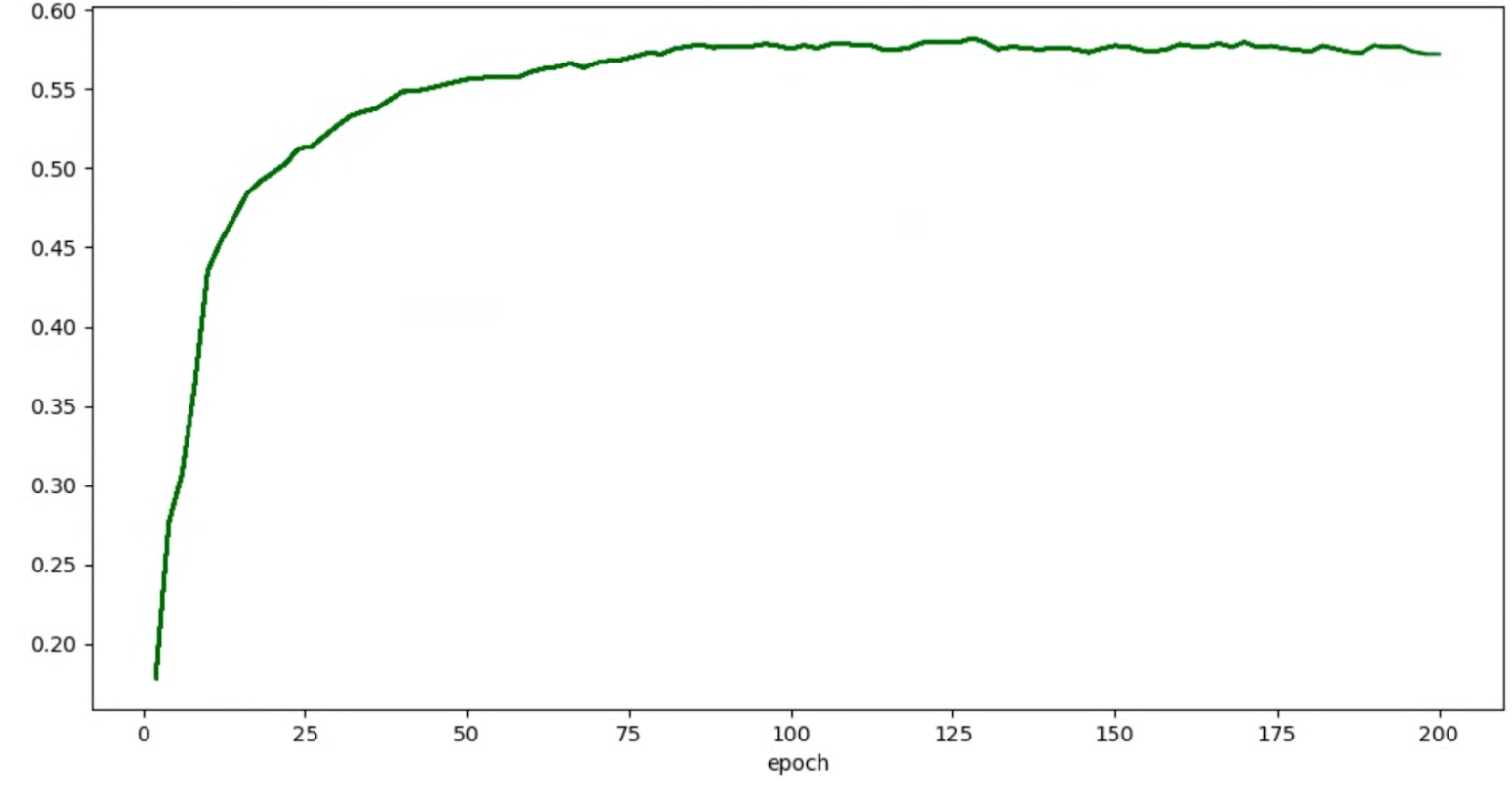
Error terkait kehabisan memori (OOM) dan kecepatan pembelajaran
Ruang penelusuran arsitektur dapat menghasilkan model yang jauh lebih besar dari dasar pengukuran Anda. Anda mungkin telah menyesuaikan ukuran tumpukan untuk model dasar pengukuran, tetapi setelan ini mungkin gagal jika model yang lebih besar diambil sampelnya selama penelusuran yang menyebabkan error OOM. Dalam hal ini, Anda perlu mengurangi ukuran tumpukan.
Jenis error lain yang muncul adalah error NaN (bukan angka). Anda harus mengurangi kecepatan pembelajaran awal atau menambahkan pemotongan gradien.
Seperti disebutkan dalam tutorial-2, jika lebih dari 20% model ruang penelusuran menampilkan skor yang tidak valid, Anda tidak akan menjalankan penelusuran lengkap. Alat desain tugas proxy kami menyediakan cara untuk menilai tingkat kegagalan.
Alat desain tugas proxy
Bagian sebelumnya membahas tentang prinsip-prinsip desain tugas proxy. Bagian ini menyediakan tiga alat desain tugas proxy untuk menemukan tugas proxy yang optimal secara otomatis berdasarkan pendekatan desain yang berbeda dan yang memenuhi semua persyaratan.
Perubahan kode yang diperlukan
Anda harus sedikit memodifikasi kode pelatih terlebih dahulu
agar dapat berinteraksi dengan
alat desain tugas proxy selama proses iterasi.
tf_vision/train_lib.py
menunjukkan contoh. Anda harus mengimpor
library terlebih dahulu:
from google.cloud.visionsolutions.nas.proxy_task import proxy_task_utils
Sebelum siklus pelatihan dimulai di loop pelatihan, periksa apakah Anda perlu menghentikan pelatihan lebih awal, karena alat desain tugas proxy ingin Anda menggunakan library kami:
if proxy_task_utils.get_stop_training(
model_dir,
end_training_cycle_step=<last-training-step-idx done so far>,
total_training_steps=<total-training-steps>):
break
Setelah setiap siklus pelatihan di loop pelatihan selesai, perbarui skor akurasi yang baru, langkah awal dan akhir siklus pelatihan, waktu siklus pelatihan dalam detik, dan total langkah pelatihan.
proxy_task_utils.update_trial_training_accuracy_metric(
model_dir=model_dir,
accuracy=<latest accuracy value>,
begin_training_cycle_step=<beginning training step for this cycle>,
end_training_cycle_step=<end training step for this cycle>,
training_cycle_time_in_secs=<training cycle time (excluding validation)>,
total_training_steps=<total-training-steps>)
Perhatikan bahwa waktu siklus pelatihan tidak boleh menyertakan waktu untuk evaluasi skor validasi. Pastikan pelatih Anda menghitung skor validasi dengan sering (frekuensi evaluasi) sehingga Anda memiliki sampling kurva validasi yang cukup. Jika Anda menggunakan batasan latensi, perbarui metrik latensi setelah komputasi latensi:
proxy_task_utils.update_trial_training_latency_metric(
model_dir=model_dir,
latency=<measured_latency>)
Alat pemilihan model memerlukan
pemuatan checkpoint sebelumnya untuk iterasi berturut-turut.
Untuk memungkinkan penggunaan kembali checkpoint sebelumnya, tambahkan flag ke pelatih
seperti yang ditunjukkan pada tf_vision/cloud_search_main.py:
parser.add_argument(
"--retrain_use_search_job_checkpoint",
type=cloud_nas_utils.str_2_bool,
default=False,
help="True to use previous NAS search job checkpoint."
)
Muat checkpoint ini sebelum Anda melatih model:
if FLAGS.retrain_use_search_job_checkpoint:
prev_checkpoint_dir = cloud_nas_utils.get_retrain_search_job_model_dir(
retrain_search_job_trials=FLAGS.retrain_search_job_trials,
retrain_search_job_dir=FLAGS.retrain_search_job_dir)
logging.info("Setting checkpoint to %s.", prev_checkpoint_dir)
# Now set your checkpoint using 'prev_checkpoint_dir'.
Anda juga memerlukan metric-id yang sesuai dengan nilai akurasi dan latensi
yang dilaporkan oleh pelatih Anda. Jika reward pelatih Anda
(yang terkadang merupakan kombinasi akurasi dan latensi) berbeda
dengan akurasi, pastikan Anda juga
melaporkan kembali metrik khusus akurasi menggunakan other_metrics dari pelatih Anda.
Misalnya, contoh berikut menunjukkan metrik khusus akurasi dan latensi
yang dilaporkan oleh pelatih bawaan kami:
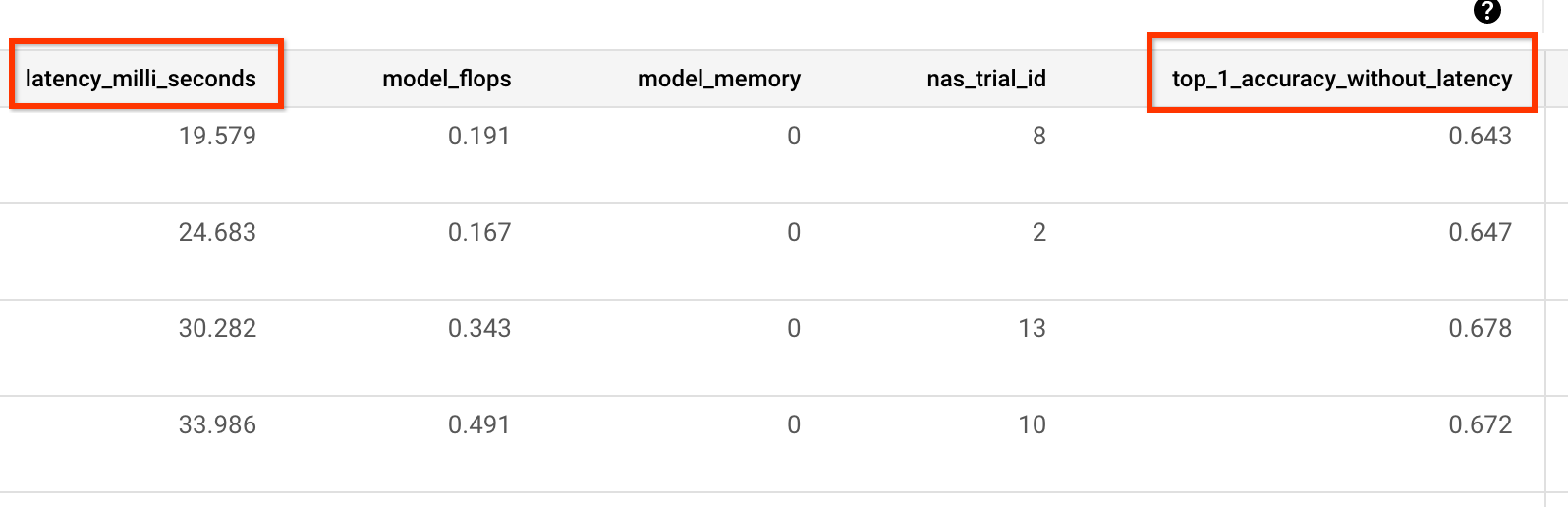
Pengukuran varians
Setelah mengubah kode pelatih, langkah pertama adalah mengukur varians untuk pelatih Anda. Untuk pengukuran varians, ubah konfigurasi pelatihan dasar pengukuran Anda untuk hal berikut:
- mengurangi langkah pelatihan agar berjalan hanya selama sekitar satu jam dengan satu atau dua GPU. Kita memerlukan sedikit sampel pelatihan penuh.
- menggunakan kecepatan pembelajaran peluruhan kosinus dan menetapkan langkah-langkahnya agar sama dengan langkah-langkah yang dikurangi sehingga kecepatan pembelajaran menjadi hampir nol menjelang akhir.
Alat pengukuran varians mengambil sampel satu model dari ruang penelusuran, memastikan bahwa model ini dapat memulai pelatihan tanpa menyebabkan error OOM atau NAN, menjalankan lima salinan model ini dengan setelan Anda selama sekitar satu jam, dan kemudian melaporkan varians dan kelancaran skor pelatihan. Total biaya untuk menjalankan alat ini kira-kira sama dengan menjalankan lima model dengan setelan Anda selama sekitar satu jam.
Luncurkan tugas pengukuran varians dengan menjalankan perintah berikut (Anda memerlukan akun layanan):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
####### Variance measurement related parameters ######
proxy_task_variance_measurement_docker_id=${USER}_variance_measurement_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id}
# The command below passes 'dummy' arguments for the training docker.
# You need to modify them for your own docker.
python3 vertex_nas_cli.py measure_proxy_task_variance \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id} \
--project_id=${project_id} \
--service_account=${service_account} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Setelah meluncurkan tugas pengukuran varians ini, Anda akan mendapatkan link tugas. Nama
pekerjaan harus dimulai dengan awalan Variance_Measurement. Contoh UI tugas
ditampilkan di bawah ini:
variance_measurement_dir akan berisi semua output, dan Anda dapat memeriksa log dengan mengklik link Lihat log.
Tugas ini secara default menggunakan satu CPU di cloud untuk berjalan di latar belakang
sebagai tugas kustom, lalu meluncurkan dan mengelola tugas
NAS turunan.
Di bagian tugas NAS, Anda akan melihat tugas bernama
Find_workable_model_<your job name>. Tugas ini akan mengambil sampel
ruang penelusuran Anda untuk menemukan satu model, yang tidak menghasilkan error apa pun. Setelah
model tersebut ditemukan, tugas pengukuran varians akan meluncurkan
tugas NAS lain <your job name>, yang menjalankan lima salinan model ini
untuk jumlah langkah pelatihan yang Anda tetapkan sebelumnya. Setelah pelatihan untuk
model ini selesai, tugas pengukuran varians mengukur
varians dan kelancaran skornya, serta melaporkannya dalam log:
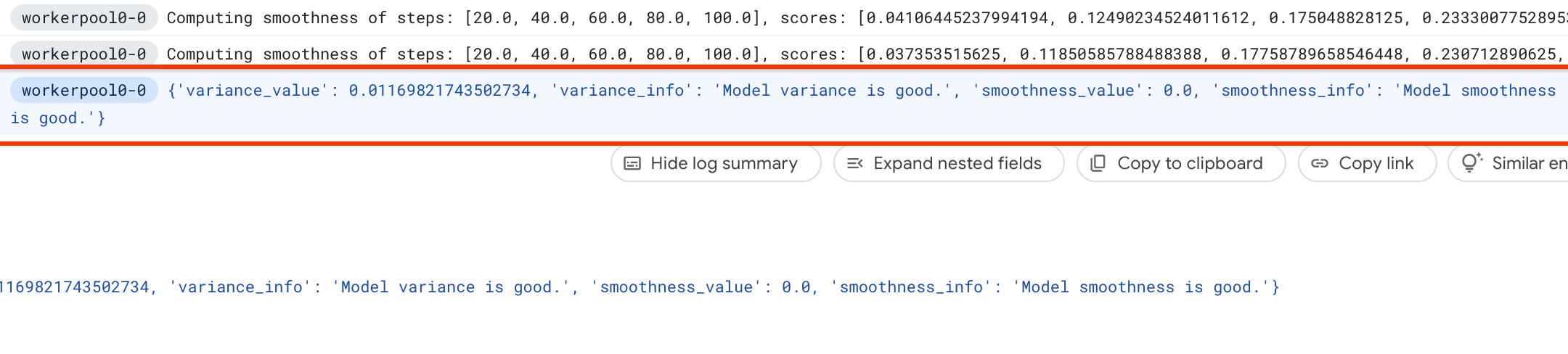
Jika varians tinggi, Anda dapat mempelajari teknik yang tercantum di sini.
Pemilihan model
Setelah memverifikasi bahwa pelatih Anda tidak memiliki varians tinggi, langkah berikutnya adalah:
- menemukan ~10 model kandidat korelasi
- menghitung skor pelatihan penuhnya yang akan berfungsi sebagai referensi saat Anda menghitung skor korelasi tugas proxy untuk berbagai opsi tugas proxy nanti.
Alat kami secara otomatis dan efisien menemukan model kandidat korelasi ini dan memastikannya memiliki distribusi skor yang baik untuk akurasi dan latensi, sehingga komputasi korelasi di masa mendatang memiliki dasar yang baik. Untuk melakukannya, alat tersebut akan melakukan hal berikut:
- Mengambil sampel model
N_beginsecara acak dari ruang penelusuran Anda. Untuk contoh di sini, mari kita asumsikanN_begin = 30. Alat tersebut akan melatih model selama 1/30 waktu pelatihan penuh. - Menolak lima dari 30 model, yang tidak menambah lebih banyak distribusi akurasi dan latensi. Gambar berikut menampilkan hal ini sebagai contoh. Model yang ditolak ditampilkan sebagai titik merah:
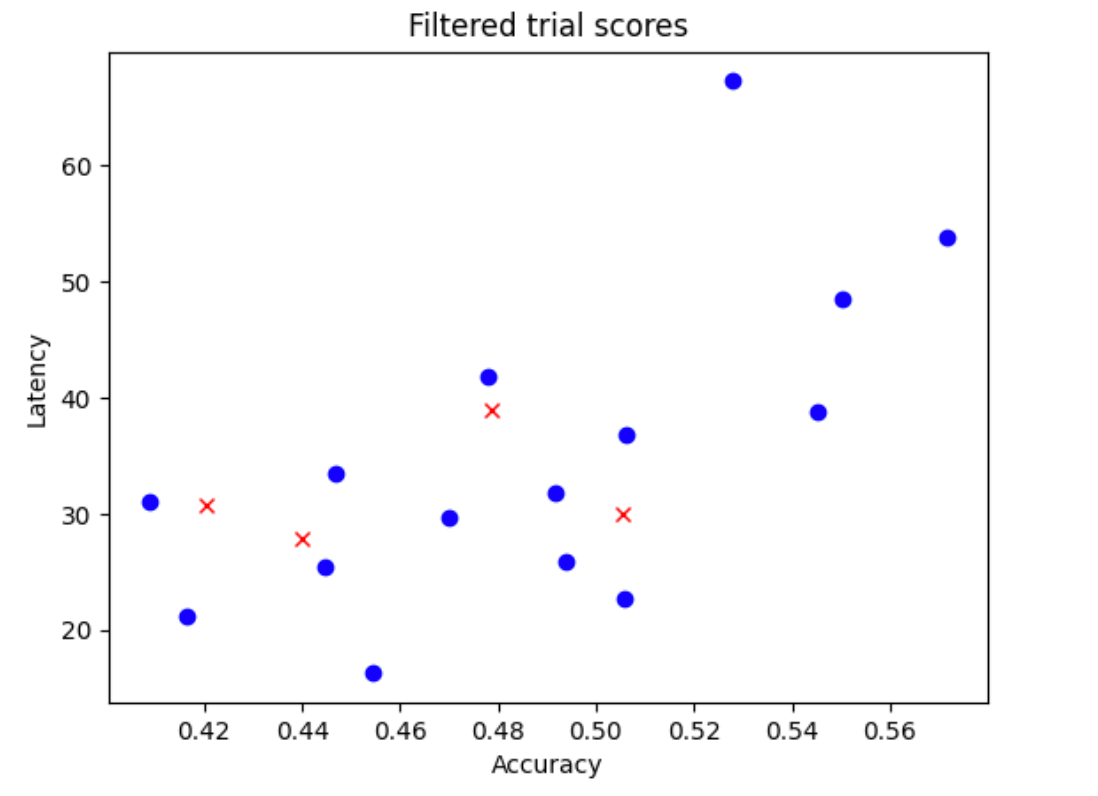
- Melatih 25 model yang dipilih selama 1/25 waktu pelatihan penuh, lalu menolak lima model lainnya berdasarkan skor sejauh ini. Perhatikan bahwa pelatihan 25 model dilanjutkan dari checkpoint sebelumnya.
- Mengulangi proses ini sampai hanya tersisa
Nmodel dengan distribusi baik. - Melatih
Nmodel terakhir ini hingga selesai.
Setelan default untuk N_begin adalah 30 dan dapat ditemukan sebagai START_NUM_MODELS
dalam file proxy_task/proxy_task_model_selection_lib_constants.py.
Setelan default untuk N adalah 10 dan dapat ditemukan sebagai FINAL_NUM_MODELS
dalam file proxy_task/proxy_task_model_selection_lib_constants.py.
Biaya tambahan proses pemilihan model ini dihitung sebagai berikut:
= (30*1/30 + 25*1/25 + 20*1/20 + 15*1/15 + 10*(remaining-training-time-fraction)) * full-training-time
= (4 + 10*(0.81)) * full-training-time
~= 12 * full-training-time
Namun, pastikan tetap di atas setelan N=10. Alat penelusuran tugas proxy kemudian
menjalankan model N ini secara paralel. Oleh karena itu, pastikan
Anda memiliki kuota GPU yang cukup untuk ini. Misalnya, jika
tugas proxy Anda menggunakan dua GPU untuk satu model, Anda harus
memiliki kuota minimal 2*N GPU.
Untuk tugas pemilihan model, gunakan partisi set data yang sama dengan tugas pelatihan penuh tahap 2, dan gunakan konfigurasi pelatih yang sama untuk pelatihan penuh dasar pengukuran Anda.
Sekarang Anda siap meluncurkan tugas pemilihan model dengan menjalankan perintah berikut (Anda memerlukan akun layanan):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task model-selection related parameters ######
proxy_task_model_selection_docker_id=${USER}_model_selection_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
# The value below depends on your accelerator quota. By default
# the model-selection job runs 30 trials. However, depending on
# your quota, you can choose to only run 10 trials in parallel at a time.
# However, lowering this number can increase the overall runtime for the job.
max_parallel_nas_trial=<num parallel trials>
# The value below is the 'metric-id' corresponding to the accuracy ONLY
# metric reported by your trainer. Note that this metric may
# be different from the 'reward'.
accuracy_metric_id=<set accuracy metric id used by your trainer>
latency_metric_id=<set latency metric id used by your trainer>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py select_proxy_task_models \
--service_account=${service_account} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--max_parallel_nas_trial=${max_parallel_nas_trial} \
--accuracy_metric_id=${accuracy_metric_id} \
--latency_metric_id=${latency_metric_id} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Setelah Anda meluncurkan tugas pengontrol pemilihan model ini, link tugas akan diterima. Nama
pekerjaan dimulai dengan awalan Model_Selection_. Contoh UI tugas
ditampilkan di bawah ini:
model_selection_dir berisi semua output. Periksa log
dengan mengklik link View logs.
Tugas pengontrol pemilihan model ini secara default menggunakan
satu CPU di Google Cloud untuk berjalan di latar belakang
sebagai tugas kustom lalu meluncurkan dan mengelola tugas
NAS turunan untuk setiap iterasi pemilihan model.
Setiap tugas NAS turunan
memiliki nama seperti <your_job_name>_iter_3 (kecuali untuk iterasi 0).
Hanya satu iterasi yang berjalan dalam satu waktu. Pada setiap iterasi, jumlah
model (jumlah uji coba) berkurang dan durasi pelatihan
meningkat. Pada akhir setiap iterasi, setiap tugas NAS menyimpan
file gs://<job-output-dir>/search/filtered_trial_scores.png
yang secara visual menunjukkan model yang ditolak pada iterasi ini.
Anda juga dapat menjalankan perintah berikut:
gsutil cat gs://<path to 'model_selection_dir'>/MODEL_SELECTION_STATE.json
yang menunjukkan ringkasan iterasi dan status saat ini dari tugas pengontrol pemilihan model, nama tugas, dan link untuk setiap iterasi:
{
"start_num_models": 30,
"final_num_models": 10,
"num_models_to_remove_per_iter": 5,
"accuracy_metric_id": "top_1_accuracy_without_latency",
"latency_metric_id": "latency_milli_seconds",
"iterations": [
{
"num_trials": 30,
"trials_to_retrain": [
"27",
"16",
...,
"14"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2111217356469436416",
"search_job_link": "http://console.cloud.go888ogle.com.fqhub.com/vertex-ai/locations/europe-west4/training/2111217356469436416/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/6909239809479278592",
"latency_calculator_job_link": "http://console.cloud.go888ogle.com.fqhub.com/vertex-ai/locations/europe-west4/training/6909239809479278592/cpu?project=my-project",
"desired_training_step_pct": 2.0
},
...,
{
"num_trials": 15,
"trials_to_retrain": [
"14",
...,
"5"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/7045544066951413760",
"search_job_link": "http://console.cloud.go888ogle.com.fqhub.com/vertex-ai/locations/europe-west4/training/7045544066951413760/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/2790768318993137664",
"latency_calculator_job_link": "http://console.cloud.go888ogle.com.fqhub.com/vertex-ai/locations/europe-west4/training/2790768318993137664/cpu?project=my-project",
"desired_training_step_pct": 28.57936507936508
},
{
"num_trials": 10,
"trials_to_retrain": [],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2742864796394192896",
"search_job_link": "http://console.cloud.go888ogle.com.fqhub.com/vertex-ai/locations/europe-west4/training/2742864796394192896/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/1490864099985195008",
"latency_calculator_job_link": "http://console.cloud.go888ogle.com.fqhub.com/vertex-ai/locations/europe-west4/training/1490864099985195008/cpu?project=my-project",
"desired_training_step_pct": 101.0
}
]
}
Iterasi terakhir memiliki jumlah akhir model referensi dengan distribusi skor yang baik. Model ini dan skornya digunakan untuk penelusuran tugas proxy di langkah berikutnya. Jika rentang skor akurasi dan latensi akhir untuk model referensi terlihat lebih baik atau mendekati model dasar pengukuran yang ada, hal ini memberikan indikasi awal yang baik tentang ruang penelusuran Anda. Jika rentang skor akurasi dan latensi akhir jauh lebih buruk daripada dasar pengukuran, kunjungi kembali ruang penelusuran Anda.
Perhatikan bahwa jika lebih dari 20% uji coba Anda pada iterasi pertama gagal, batalkan tugas pemilihan model Anda dan identifikasi penyebab utama kegagalan. Mungkin ada masalah pada ruang penelusuran atau setelan ukuran batch dan kecepatan pembelajaran Anda.
Menggunakan perangkat latensi lokal untuk pemilihan model
Agar dapat menggunakan perangkat latensi lokal untuk pemilihan model, jalankan
perintah select_proxy_task_models tanpa docker latensi dan
flag docker latensi, karena Anda tidak ingin meluncurkan docker latensi
di Google Cloud. Selanjutnya, gunakan perintah run_latency_calculator_local yang dijelaskan dalam
Tutorial 4
untuk meluncurkan tugas kalkulator latensi lokal. Dibandingkan meneruskan
flag --search_job_id, teruskan flag --controller_job_id dengan
ID tugas pemilihan model numerik yang Anda dapatkan setelah menjalankan
perintah select_proxy_task_models.
Melanjutkan tugas pengontrol pemilihan model
Situasi berikut mengharuskan Anda melanjutkan tugas pengontrol pemilihan model:
- Tugas pengontrol pemilihan model induk mati (kasus yang jarang terjadi).
- Anda tidak sengaja membatalkan tugas pengontrol pemilihan model.
Pertama, jangan batalkan tugas iterasi NAS turunan (tab NAS)
jika sudah berjalan. Kemudian, untuk melanjutkan
tugas pengontrol pemilihan model induk,
jalankan perintah select_proxy_task_models seperti sebelumnya, tetapi kali ini teruskan
flag --previous_model_selection_dir, dan tetapkan ke
direktori output untuk tugas pengontrol pemilihan model sebelumnya. Tugas
pengontrol pemilihan model yang dilanjutkan memuat status sebelumnya
dari direktori dan terus berfungsi seperti sebelumnya.
Penelusuran tugas proxy
Setelah menemukan model kandidat korelasi dan skor pelatihan penuhnya, langkah berikutnya adalah menggunakannya untuk mengevaluasi skor korelasi untuk berbagai pilihan tugas proxy, dan memilih tugas proxy yang optimal. Alat penelusuran tugas proxy kami dapat menemukan tugas proxy secara otomatis, yang menawarkan hal berikut:
- Biaya penelusuran NAS terendah.
- Memenuhi batas persyaratan korelasi minimum setelah memberinya definisi ruang penelusuran proxy-task.
Ingat kembali, ada tiga dimensi umum untuk menelusuri tugas proxy yang optimal, yang meliputi:
- Pengurangan jumlah langkah pelatihan.
- Pengurangan jumlah data pelatihan.
- Pengurangan skala model.
Anda dapat membuat ruang penelusuran tugas proxy terpisah dengan mengambil sampel dimensi ini seperti yang ditunjukkan di sini:
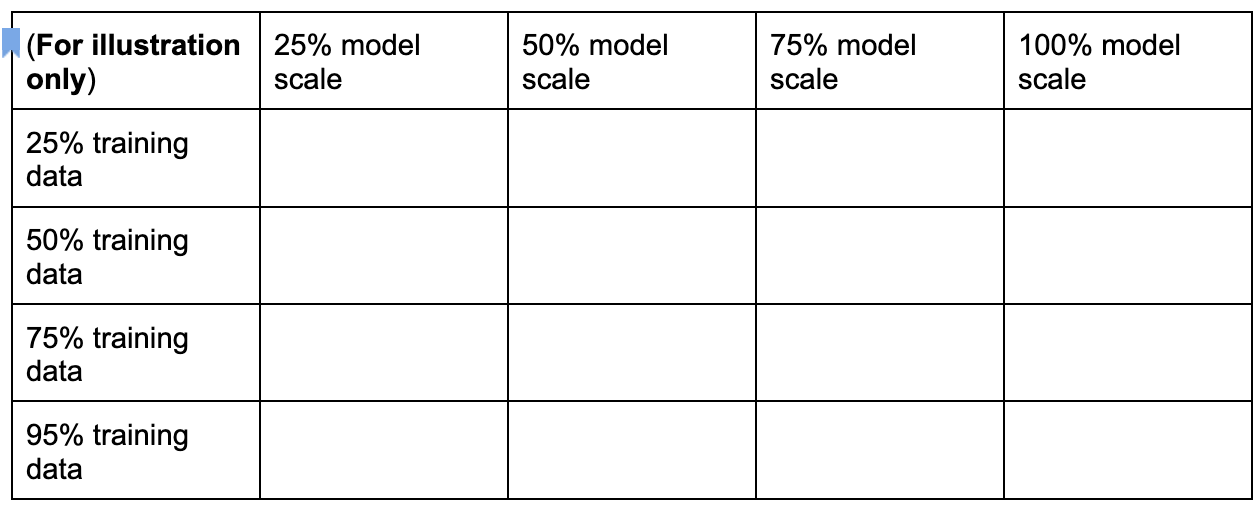
Angka persentase di atas hanya ditetapkan sebagai perkiraan saran
dan contoh. Dalam praktiknya, Anda dapat memilih berbagai pilihan terpisah.
Perhatikan bahwa kita belum menyertakan dimensi langkah pelatihan dalam
ruang penelusuran di atas. Hal ini karena alat penelusuran tugas proxy
menentukan langkah pelatihan yang optimal berdasarkan pilihan tugas proxy.
Pertimbangkan pilihan tugas proxy
[50% training data, 25% model scale]. Tetapkan
langkah pelatihan dengan jumlah yang sama seperti untuk pelatihan dasar pengukuran penuh.
Saat mengevaluasi tugas proxy ini, alat penelusuran tugas proxy
akan meluncurkan pelatihan untuk model kandidat korelasi, memantau
skor akurasinya saat ini, dan terus menghitung
skor korelasi peringkat
(menggunakan skor pelatihan penuh untuk model referensi):
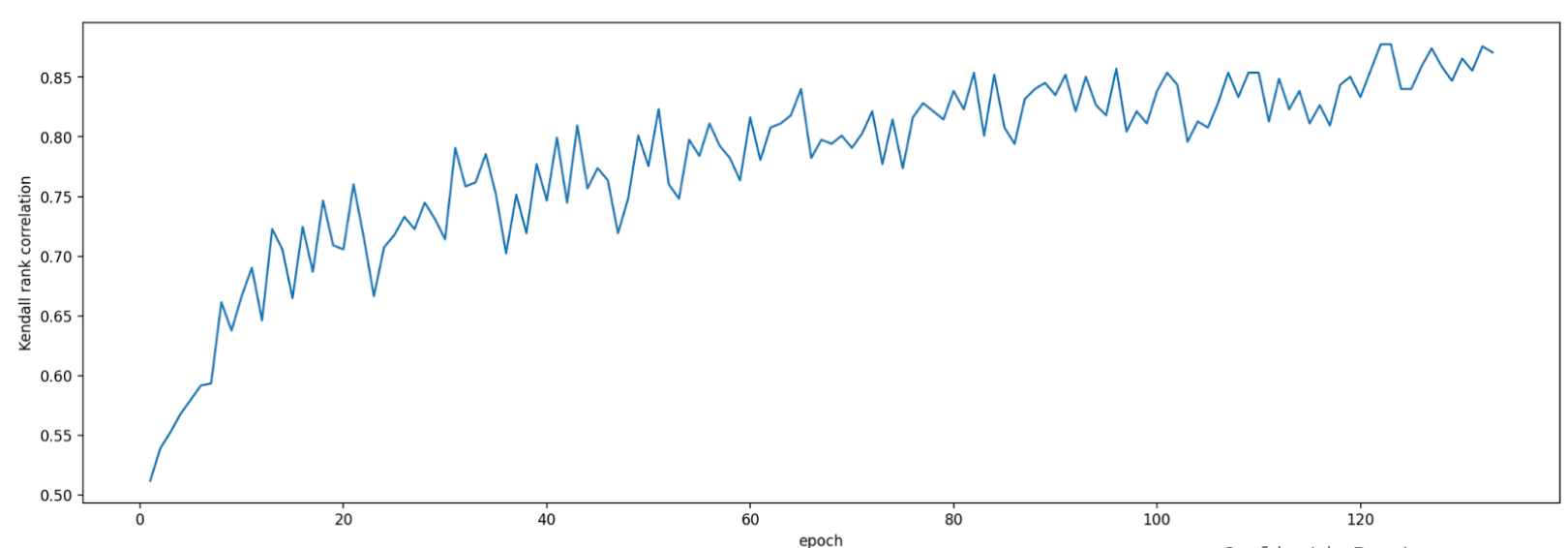
Dengan demikian, alat penelusuran tugas proxy dapat menghentikan pelatihan tugas proxy setelah korelasi yang diinginkan (seperti 0,65) diperoleh atau juga dapat berhenti lebih awal jika kuota biaya penelusuran (seperti 3 batas jam per tugas proxy) terlampaui. Oleh karena itu, Anda tidak perlu melakukan penelusuran secara eksplisit pada langkah pelatihan. Alat penelusuran tugas proxy mengevaluasi setiap tugas proxy dari ruang penelusuran terpisah sebagai penelusuran grid dan memberikan opsi terbaik kepada Anda.
Berikut adalah contoh definisi ruang penelusuran tugas proxy MnasNet
mnasnet_proxy_task_config_generator,
yang didefinisikan dalam file proxy_task/proxy_task_search_spaces.py,
untuk menunjukkan cara menentukan ruang penelusuran Anda sendiri:
# MNasnet training-data size choices.
MNASNET_TRAINING_DATA_PCT_LIST = [25, 50, 75, 95]
# Training data path regex pattern.
_TRAINING_DATA_PATH_REGEX = r"gs://.*/.*"
def update_mnasnet_proxy_training_data(
baseline_docker_args_map: Dict[str, Any],
training_data_pct: int) -> Optional[Dict[str, Any]]:
"""Updates MNasnet baseline docker to use a certain training_data_pct."""
proxy_task_docker_args_map = copy.deepcopy(baseline_docker_args_map)
# Imagenet training data path looks like:
# gs://<path to imagenet data>/train-00[0-7]??-of-01024.
if not re.match(_TRAINING_DATA_PATH_REGEX,
baseline_docker_args_map["training_data_path"]):
raise ValueError(
"Training data path %s does not match the desired pattern." %
baseline_docker_args_map["training_data_path"])
root_path, _ = baseline_docker_args_map["training_data_path"].rsplit("/", 1)
if training_data_% == 25:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-1][0-4]?-of-01024*")
elif training_data_% == 50:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-4]??-of-01024*")
elif training_data_% == 75:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-6][0-4]?-of-01024*")
elif training_data_% == 95:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-8][0-4]?-of-01024*")
else:
logging.warning("Mnasnet training_data_% %d is not supported.",
training_data_pct)
return None
proxy_task_docker_args_map["validation_data_path"] = os.path.join(
root_path, "train-009[0-4]?-of-01024")
return proxy_task_docker_args_map
def mnasnet_proxy_task_config_generator(
baseline_docker_args_map: Dict[str, Any]
) -> List[proxy_task_utils.ProxyTaskConfig]:
"""Returns a list of proxy-task configs to be evaluated for MNasnet.
Args:
baseline_docker_args_map: A set of baseline training-docker arguments in
the form of a dictionary of {'key', val}. The different proxy-task
configs to try can be built by modifying this baseline.
Returns:
A list of proxy-task configs to be evaluated for this
proxy-task search space.
"""
proxy_task_config_list = []
# NOTE: Will not search over model-scale for MNasnet.
for training_data_% in MNASNET_TRAINING_DATA_PCT_LIST:
proxy_task_docker_args_map = update_mnasnet_proxy_training_data(
baseline_docker_args_map=baseline_docker_args_map,
training_data_pct=training_data_pct)
if not proxy_task_docker_args_map:
continue
proxy_task_name = "mnasnet_proxy_training_data_pct_{}".format(
training_data_pct)
proxy_task_config_list.append(
proxy_task_utils.ProxyTaskConfig(
name=proxy_task_name, docker_args_map=proxy_task_docker_args_map))
return proxy_task_config_list
Dalam contoh ini, kita membuat ruang penelusuran sederhana untuk data pelatihan
25, 50, 75, dan 95 persen (Perhatikan bahwa data pelatihan 100 persen
tidak digunakan untuk penelusuran tahap 1 ).
Fungsi mnasnet_proxy_task_config_generator mengambil
template dasar pengukuran umum dari argumen docker pelatihan, lalu
mengubah argumen ini untuk setiap ukuran data pelatihan
tugas proxy yang diinginkan. Kemudian, metode ini menampilkan daftar
proxy-task-config yang
kemudian diproses oleh alat penelusuran tugas proxy satu per satu
dalam urutan yang sama. Setiap konfigurasi tugas proxy
memiliki name dan docker_args_map, yang merupakan peta nilai kunci untuk
argumen docker tugas proxy.
Anda bebas menerapkan definisi ruang penelusuran sesuai kebutuhan dan mendesain ruang penelusuran tugas proxy Anda sendiri, bahkan untuk lebih dari dua dimensi data pelatihan yang dikurangi atau skala model yang dikurangi. Namun, Anda tidak disarankan untuk menelusuri langkah pelatihan secara eksplisit karena akan melibatkan komputasi berulang yang sia-sia. Biarkan alat penelusuran tugas proxy menangani dimensi ini untuk Anda.
Untuk penelusuran tugas proxy pertama, Anda dapat mencoba
mengurangi data pelatihan saja (seperti contoh MnasNet)
dan melewati skala model yang dikurangi karena penskalaan model dapat melibatkan
beberapa parameter pada image-size, num-filters, atau num-blocks.
Dalam sebagian besar kasus, data pelatihan yang dikurangi (dan penelusuran implisit pada
langkah pelatihan yang dikurangi) sudah cukup untuk menemukan tugas proxy yang baik.
Tetapkan jumlah langkah pelatihan
ke jumlah yang digunakan dalam pelatihan dasar pengukuran penuh.
Ada perbedaan antara konfigurasi pelatihan penuh tahap 2
dan konfigurasi pelatihan tugas proxy tahap 1. Untuk tugas proxy,
Anda harus mengurangi batch-size dibandingkan dengan
konfigurasi pelatihan dasar pengukuran penuh agar hanya menggunakan 2 GPU atau 4 GPU.
Biasanya, pelatihan penuh menggunakan 4 GPU, 8 GPU, atau lebih, tetapi
tugas proxy hanya menggunakan 2 GPU atau 4 GPU.
Perbedaan lainnya adalah
pemisahan pelatihan dan validasi.
Berikut adalah contoh perubahan
untuk konfigurasi MnasNet yang beralih dari 4 GPU untuk pelatihan penuh tahap 2 menjadi
2 GPU dan pemisahan validasi yang berbeda untuk penelusuran tugas proxy:
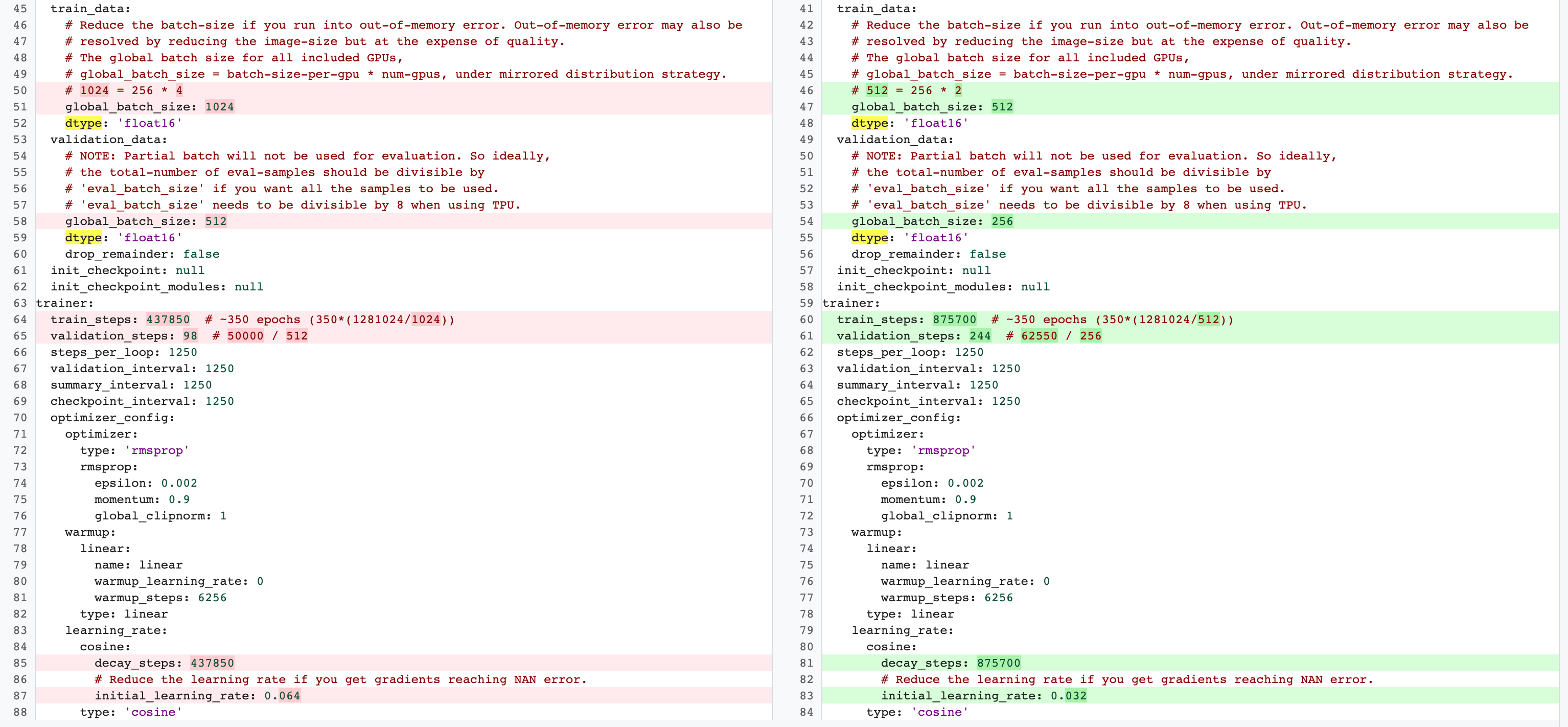
Luncurkan tugas pengontrol penelusuran tugas proxy dengan menjalankan perintah berikut (Anda memerlukan akun layanan):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your NAS job search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task search related parameters ######
proxy_task_search_controller_docker_id=${USER}_proxy_task_search_${DATE}
job_name=<your job name>
# Path to your proxy task search space definition. For ex:
# 'proxy_task.proxy_task_search_spaces.mnasnet_proxy_task_config_generator'
proxy_task_config_generator_module=<path to your proxy task config generator module>
# The previous model-slection job provides the candidate-correlation-models
# and their scores.
proxy_task_model_selection_job_id=<Numeric job id of your previous model-selection>
# During proxy-task search, the proxy-task training is stopped
# when the following correlation score is achieved.
desired_accuracy_correlation=0.65
# During proxy-task search, the proxy-task training is stopped
# if the runtime exceeds this limit: 4 hrs.
training_time_hrs_limit=4
# The proxy-task is marked a good candidate only if the latency
# correlation is also above the required threshold.
# Note: This won't be used if you do not have a latency job.
desired_latency_correlation=0.65
# Early stop a proxy-task evaluation if you already have a better candidate.
# If False, evaluate all proxy-taask candidates.
early_stop_proxy_task_if_not_best=False
# Use the service account that you set-up for your project.
service_account=<your service account>
###################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py search_proxy_task \
--service_account=${service_account} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id} \
--proxy_task_config_generator_module=${proxy_task_config_generator_module} \
--proxy_task_model_selection_job_id=${proxy_task_model_selection_job_id} \
--proxy_task_model_selection_job_region=${region} \
--desired_accuracy_correlation={$desired_accuracy_correlation}\
--training_time_hrs_limit=${training_time_hrs_limit} \
--desired_latency_correlation=${desired_latency_correlation} \
--early_stop_proxy_task_if_not_best=${early_stop_proxy_task_if_not_best} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Setelah Anda meluncurkan tugas pengontrol penelusuran tugas proxy ini,
link tugas akan diterima. Nama
pekerjaan dimulai dengan awalan Search_controller_. Contoh UI tugas
ditampilkan di bawah ini:
search_controller_dir akan berisi semua output dan Anda
dapat memeriksa log dengan mengklik link View logs.
Tugas ini secara default menggunakan satu CPU di cloud untuk berjalan di latar belakang
sebagai tugas kustom, lalu meluncurkan dan mengelola tugas
NAS turunan untuk setiap evaluasi tugas proxy.
Setiap tugas NAS tugas proxy
memiliki nama seperti ProxyTask_<your-job-name>_<proxy-task-name>,
dengan <proxy-task-name> yang disediakan
oleh modul generator konfigurasi tugas proxy untuk setiap tugas. Hanya
satu evaluasi tugas proxy yang berjalan pada satu waktu.
Anda juga dapat menjalankan perintah berikut:
gsutil cat gs://<path to 'search_controller_dir'>/SEARCH_CONTROLLER_STATE.json
Perintah ini menampilkan ringkasan semua evaluasi tugas proxy dan status tugas pengontrol penelusuran, nama tugas, dan link saat ini untuk setiap evaluasi:
{
"proxy_tasks_map": {
"mnasnet_proxy_training_data_pct_25": {
"proxy_task_stats": {
"training_steps": [
1249,
2499,
...,
18749
],
"accuracy_correlation_over_step": [
-0.06666666666666667,
-0.6,
...,
0.7857142857142856
],
"accuracy_correlation_p_value_over_step": [
0.8618005952380953,
0.016666115520282188,
...,
0.005505952380952381
],
"median_accuracy_over_step": [
0.011478611268103123,
0.04956454783678055,
...,
0.32932570576667786
],
"median_training_time_hrs_over_step": [
0.11611097933475001,
0.22913257125276987,
...,
1.6682701704073444
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.6675102778428197,
"final_training_steps": 18512
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_25",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/4173661476642357248",
"search_job_link": "http://console.cloud.go888ogle.com.fqhub.com/vertex-ai/locations/europe-west4/training/4173661476642357248/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/8785347495069745152",
"latency_calculator_job_link": "http://console.cloud.go888ogle.com.fqhub.com/vertex-ai/locations/europe-west4/training/8785347495069745152/cpu?project=my-project"
},
...,
"mnasnet_proxy_training_data_pct_95": {
"proxy_task_stats": {
"training_steps": [
1249,
...,
18749
],
"accuracy_correlation_over_step": [
-0.3333333333333333,
...,
0.7857142857142856,
-5.0
],
"accuracy_correlation_p_value_over_step": [
0.21637345679012346,
...,
0.005505952380952381,
-5.0
],
"median_accuracy_over_step": [
0.01120645459741354,
...,
0.38238024711608887,
-1.0
],
"median_training_time_hrs_over_step": [
0.11385884770307843,
...,
1.5466042930547819,
-1.0
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.533235285929564,
"final_training_steps": 17108
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_95",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2341822328209408000",
"search_job_link": "http://console.cloud.go888ogle.com.fqhub.com/vertex-ai/locations/europe-west4/training/2341822328209408000/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/7575005095213924352",
"latency_calculator_job_link": "http://console.cloud.go888ogle.com.fqhub.com/vertex-ai/locations/europe-west4/training/7575005095213924352/cpu?project=my-project"
}
},
"best_proxy_task_name": "mnasnet_proxy_training_data_pct_75"
}
proxy_tasks_map menyimpan output untuk setiap evaluasi
tugas proxy dan best_proxy_task_name mencatat tugas proxy terbaik
untuk penelusuran. Setiap entri tugas proxy memiliki data tambahan seperti
proxy_task_stats, yang mencatat progres
korelasi akurasi, nilai p-nya, akurasi median,
dan waktu pelatihan median selama langkah pelatihan. Data ini juga mencatat
korelasi terkait latensi jika berlaku dan mencatat alasan penghentian
tugas ini (seperti batas waktu pelatihan terlampaui) dan
langkah pelatihan yang menyebabkan tugas tersebut dihentikan. Anda juga dapat melihat statistik ini
sebagai plot dengan menyalin konten search_controller_dir ke
folder lokal Anda dengan menjalankan perintah berikut:
gsutil -m cp gs://<path to 'search_controller_dir'>/* /your/local/dir
dan memeriksa gambar plot. Misalnya, plot berikut menunjukkan korelasi akurasi vs waktu pelatihan untuk tugas proxy terbaik:
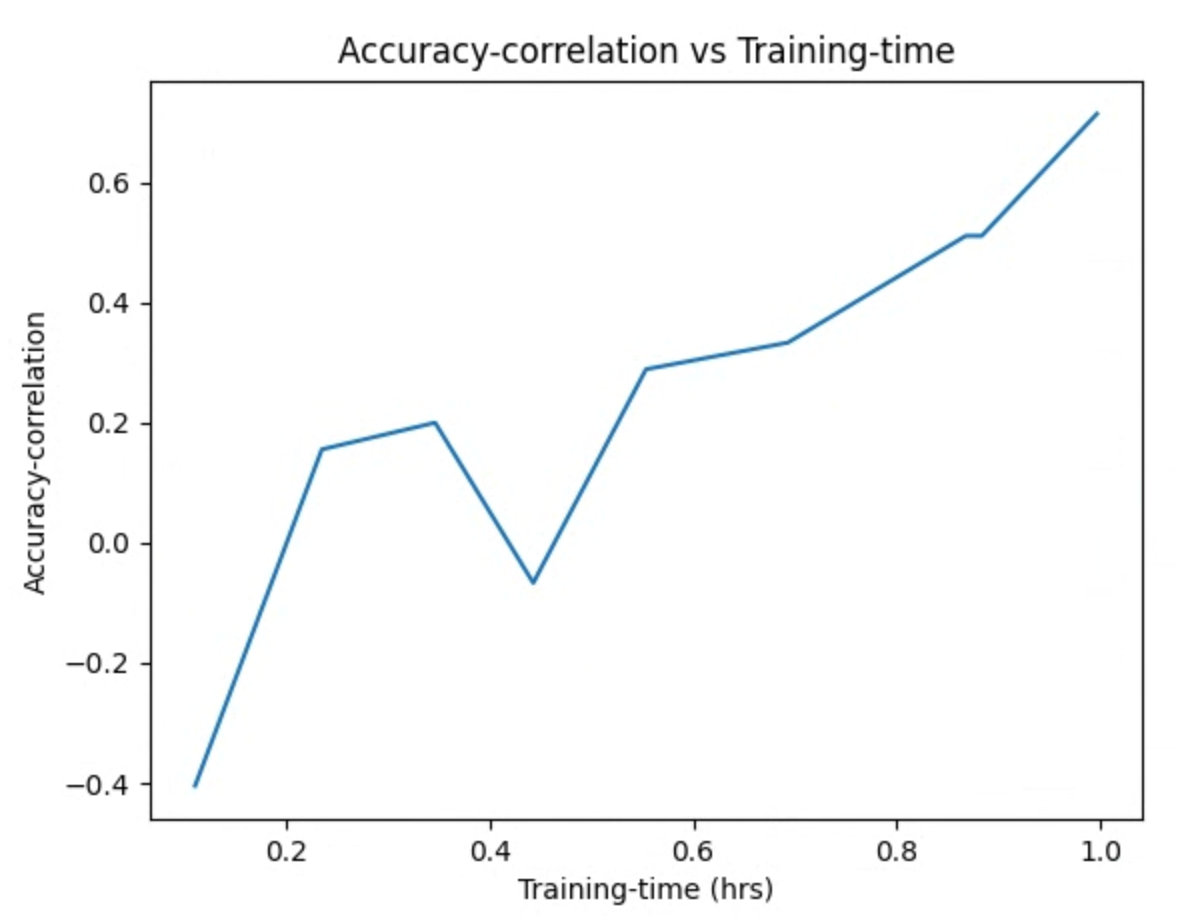
Penelusuran selesai, dan setelah menemukan konfigurasi tugas proxy terbaik, Anda harus melakukan hal berikut:
- Tetapkan jumlah langkah pelatihan ke
final_training_stepsdari tugas proxy terbaik. - Tetapkan langkah-langkah peluruhan kosinus yang sama seperti
final_training_stepssehingga kecepatan pembelajaran hampir nol menjelang akhir. - [Opsional] Lakukan satu evaluasi skor validasi di akhir pelatihan, sehingga menghemat beberapa biaya evaluasi.
Menggunakan perangkat latensi lokal untuk penelusuran tugas proxy
Agar dapat menggunakan perangkat latensi lokal untuk penelusuran tugas proxy, jalankan
perintah search_proxy_task tanpa docker latensi dan
flag docker latensi, karena Anda tidak ingin meluncurkan docker latensi
di Google Cloud. Selanjutnya, gunakan perintah run_latency_calculator_local yang dijelaskan dalam
Tutorial 4
untuk meluncurkan tugas kalkulator latensi lokal. Dibandingkan meneruskan
flag --search_job_id, teruskan flag --controller_job_id dengan
ID tugas penelusuran tugas proxy numerik yang Anda dapatkan setelah menjalankan
perintah search_proxy_task.
Melanjutkan tugas pengontrol penelusuran tugas proxy
Situasi berikut mengharuskan Anda melanjutkan tugas pengontrol penelusuran tugas proxy:
- Tugas pengontrol penelusuran tugas proxy induk mati (kasus yang jarang terjadi).
- Anda tidak sengaja membatalkan tugas pengontrol penelusuran tugas proxy.
- Anda ingin memperluas ruang penelusuran tugas proxy di lain waktu (bahkan setelah beberapa hari).
Pertama, jangan batalkan tugas iterasi NAS turunan (tab NAS)
jika sudah berjalan. Kemudian, untuk melanjutkan
tugas pengontrol penelusuran tugas proxy induk,
jalankan perintah search_proxy_task seperti sebelumnya, tetapi kali ini teruskan
flag --previous_proxy_task_search_dir, dan tetapkan ke
direktori output untuk tugas pengontrol penelusuran tugas proxy sebelumnya. Tugas
pengontrol penelusuran tugas proxy yang dilanjutkan memuat status sebelumnya
dari direktori dan terus berfungsi seperti sebelumnya.
Pemeriksaan terakhir
Dua pemeriksaan terakhir untuk tugas proxy Anda mencakup rentang reward dan penyimpanan data untuk analisis pasca-penelusuran.
Rentang reward
Reward yang dilaporkan kepada pengontrol harus dalam rentang [1e-3, 10]. Jika hal ini tidak benar, Anda dapat menskalakan reward dengan cara yang tidak semestinya untuk mencapai target ini.
Menyimpan data untuk analisis pasca-penelusuran
Kode tugas proxy Anda akan menyimpan metrik dan data tambahan
ke lokasi penyimpanan cloud, yang mungkin akan berguna untuk
menganalisis ruang penelusuran Anda nanti. Platform Penelusuran Arsitektur Neural kami hanya mendukung hingga lima floating point other_metrics untuk direkam.
Metrik tambahan apa pun harus disimpan ke lokasi
penyimpanan cloud untuk analisis nanti.