Supponendo che tu abbia già eseguito i tutorial, questa pagina descrive le best practice per Neural Architecture Search (NAS). La prima sezione riassume un flusso di lavoro completo che puoi seguire per il job di ricerca dell'architettura neurale. Le altre sezioni seguenti forniscono una descrizione dettagliata di ogni passaggio. Ti consigliamo vivamente di esaminare l'intera pagina prima di eseguire il tuo primo job di Neural Architecture Search (NAS).
Flusso di lavoro suggerito
Di seguito riepiloghiamo un flusso di lavoro suggerito per Neural Architecture Search (NAS) e forniamo link alle sezioni corrispondenti per ulteriori dettagli:
- Suddividi il set di dati di addestramento per la ricerca fase 1.
- Assicurati che il tuo spazio di ricerca rispetti le nostre linee guida.
- Esegui l'addestramento completo con il tuo modello di riferimento e ottieni una curva di convalida.
- Esegui gli strumenti di progettazione per le attività proxy per trovare l'attività proxy migliore.
- Esegui i controlli finali per l'attività proxy.
- Imposta il numero corretto di prove totali e prove parallele, quindi avvia la ricerca.
- Monitora il grafico di ricerca e interrompilo quando converge, mostra un numero elevato di errori o non mostra alcun segno di convergenza.
- Esegui un corso di formazione completo con le prime 10 prove principali scelte in base alla tua ricerca per ottenere il risultato finale. Per l'allenamento completo, puoi utilizzare più aumenti o pesi preaddestrati per ottenere le migliori prestazioni possibili.
- Analizzare le metriche/i dati salvati dalla ricerca e trarre conclusioni per future iterazioni dello spazio di ricerca.
Ricerca tipica dell'architettura neurale
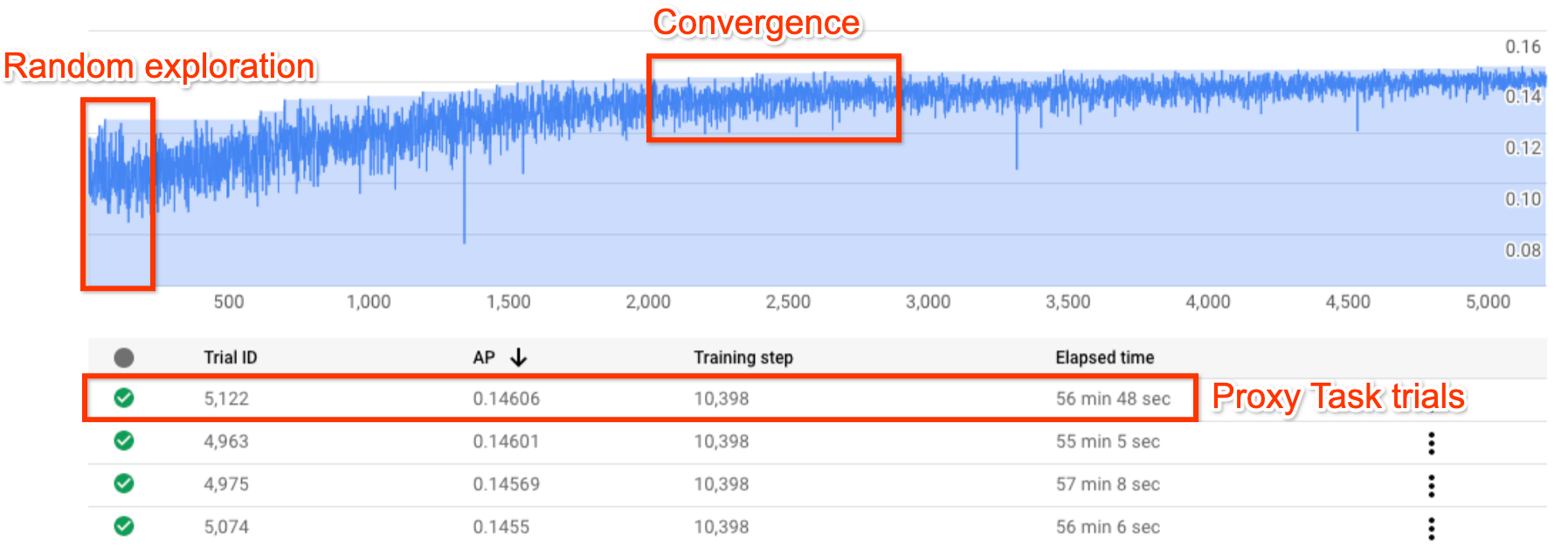
La figura sopra mostra una tipica curva di Neural Architecture Search (NAS).
Y-axis mostra le prove a premi, mentre X-axis indica il numero di prove lanciate finora.
Le prime 100-200 prove sono per lo più esplorazioni casuali dello spazio di ricerca da parte del controller.
Durante queste esplorazioni iniziali, i premi mostrano
una grande variazione perché vengono provati molti tipi di modelli nello
spazio di ricerca.
Man mano che il numero di prove aumenta, il controller inizia a trovare modelli migliori. Pertanto, prima la ricompensa inizia ad aumentare, poi la variazione della ricompensa e la crescita della ricompensa inizia a diminuire, mostrando così una convergenza. Il numero di prove in cui avviene la convergenza può variare in base alle dimensioni dello spazio di ricerca, ma in genere è dell'ordine di circa 2000 prove.
Due fasi di Neural Architecture Search (NAS): attività proxy e addestramento completo
Neural Architecture Search opera in due fasi:
La ricerca Stage1 utilizza una rappresentazione molto più ridotta dell'addestramento completo, che in genere termina entro 1-2 ore circa. Questa rappresentazione è chiamata attività proxy e consente di mantenere basso il costo di ricerca.
L'addestramento completo di Stage2 prevede un addestramento completo per i primi 10 modelli di punteggio principali della fase di ricerca della fase 1. A causa della natura stocastica della ricerca, il modello più alto di stage1-search potrebbe non essere il modello più alto durante la fase 2-addestramento completo e, di conseguenza, è importante selezionare un pool di modelli per l'addestramento completo.
Poiché il controller riceve l'indicatore di ricompensa dall'attività proxy più piccola anziché dall'addestramento completo, è importante trovare un'attività proxy ottimale per l'attività.
Costo di Neural Architecture Search
Il costo di Neural Architecture Search è dato da:
search-cost = num-trials-to-converge * avg-proxy-task-cost.
Supponendo che il tempo di calcolo dell'attività proxy sia circa 1/30 del tempo di addestramento completo e che il numero di prove necessarie per convergere sia circa 2000, il costo di ricerca diventa di circa 67 * full-training-cost.
Poiché i costi di Neural Architecture Search sono elevati, ti consigliamo di dedicare del tempo all'ottimizzazione dell'attività proxy e di utilizzare uno spazio di ricerca più ridotto per la prima ricerca.
Set di dati suddiviso tra due fasi di Neural Architecture Search
Supponendo che tu disponga già di training-data e validation-data per l'addestramento di base, la seguente suddivisione del set di dati è consigliata per le due fasi di NAS Neural Architecture Search.
- Formazione sulla ricerca fase 1: circa il 90% dei dati di addestramento
Convalida della ricerca fase 1: circa il 10% dei dati di addestramento
Formazione Stage2-full: 100% dei dati di addestramento
Convalida dell'addestramento completo della fase 2: 100% dei dati di convalida
La suddivisione dei dati stage2-full-training è uguale a quella dell'addestramento standard. Tuttavia, la ricerca fase 1 utilizza una suddivisione dei dati di addestramento per la convalida. L'utilizzo di dati di convalida diversi nello stage1 e in stage2 aiuta a rilevare eventuali bias di ricerca del modello dovuti alla suddivisione del set di dati. Assicurati che la suddivisione dei dati di addestramento sia corretta prima di procedere con il partizionamento e che la suddivisione finale dei dati di addestramento al 10% abbia una distribuzione simile ai dati di convalida originali.
Dati ridotti o non bilanciati
La ricerca dell'architettura non è consigliata con dati di addestramento limitati o per set di dati altamente sbilanciati in cui alcune classi sono molto rare. Se utilizzi già aumenti intensivi per l'addestramento di base a causa della mancanza di dati, la ricerca dei modelli non è consigliata.
In questo caso puoi eseguire solo la ricerca di aumento per cercare il criterio di aumento migliore anziché cercare un'architettura ottimale.
Progettazione dello spazio di ricerca
La ricerca dell'architettura non deve essere combinata con la ricerca di aumento o la ricerca degli iperparametri (ad esempio, tasso di apprendimento o impostazioni dell'ottimizzatore). L'obiettivo della ricerca dell'architettura è confrontare le prestazioni del modello A con il modello B quando esistono solo differenze basate sull'architettura. Pertanto, le impostazioni di incremento e di iperparametri dovrebbero rimanere invariate.
La ricerca di aumento può essere eseguita in una fase diversa dopo la ricerca dell'architettura.
Neural Architecture Search (NAS) può arrivare fino a 10^20 nelle dimensioni dello spazio di ricerca. Tuttavia, se lo spazio di ricerca è più ampio, puoi dividerlo in parti che si escludono a vicenda. Ad esempio, puoi cercare l'encoder separatamente dal decoder o dall'elemento head. Se vuoi comunque eseguire una ricerca congiunta su tutte le opzioni, puoi creare uno spazio di ricerca più ridotto attorno alle singole opzioni migliori trovate in precedenza.
(Facoltativo) Puoi scalare i modelli da block-design durante la progettazione di uno spazio di ricerca. La ricerca basata sulla struttura a blocchi dovrebbe essere eseguita prima con un modello ridimensionato. In questo modo il costo del runtime delle attività proxy è molto più basso. Puoi quindi eseguire una ricerca separata per scalare il modello. Per maggiori informazioni, consulta
Examples of scaled down models.
Ottimizzare i tempi di addestramento e ricerca
Prima di eseguire Neural Architecture Search (NAS), è importante ottimizzare il tempo di addestramento del modello di base. In questo modo puoi risparmiare sul lungo periodo. Ecco alcune delle opzioni per ottimizzare la formazione:
- Massimizza la velocità di caricamento dei dati:
- Assicurati che il bucket in cui si trovano i tuoi dati si trovi nella stessa regione del job.
- Se utilizzi TensorFlow, consulta
Best practice summary. Puoi anche provare a utilizzare il formato TFRecord per i tuoi dati. - Se utilizzi PyTorch, segui le linee guida per un addestramento efficiente di PyTorch.
- Utilizza l'addestramento distribuito per sfruttare più acceleratori o più macchine.
- Utilizza l'addestramento di precisione misto
per accelerare e ridurre l'utilizzo della memoria.
Per l'addestramento di precisione misto TensorFlow,
consulta
Mixed Precision. - Alcuni acceleratori (come A100) sono generalmente più efficienti in termini di costi.
- Ottimizza le dimensioni del batch per assicurarti di massimizzare l'utilizzo della GPU.
Il grafico seguente mostra il sottoutilizzo delle GPU (al 50%).
 Aumentare le dimensioni del batch può aiutare a utilizzare di più le GPU. Tuttavia, le dimensioni del batch devono essere aumentate attentamente in quanto possono aumentare gli errori di esaurimento della memoria durante la ricerca.
Aumentare le dimensioni del batch può aiutare a utilizzare di più le GPU. Tuttavia, le dimensioni del batch devono essere aumentate attentamente in quanto possono aumentare gli errori di esaurimento della memoria durante la ricerca. - Se alcuni blocchi dell'architettura sono indipendenti dallo spazio di ricerca, puoi provare a caricare i checkpoint preaddestrati per questi blocchi per un addestramento più rapido. I checkpoint preaddestrati devono essere gli stessi nello spazio di ricerca e non devono introdurre un bias. Ad esempio, se lo spazio di ricerca è solo per il decoder, l'encoder può utilizzare checkpoint preaddestrati.
Numero di GPU per ogni prova di ricerca
Utilizza un numero inferiore di GPU per prova in modo da ridurre il tempo di avvio. Ad esempio, 2 GPU richiedono 5 minuti per l'avvio, mentre 8 GPU richiedono 20 minuti. È più efficiente utilizzare 2 GPU per prova per eseguire un'attività proxy per job di ricerca dell'architettura neurale.
Prove totali e prove parallele per la ricerca
Impostazioni di prova totali
Dopo aver cercato e selezionato l'attività proxy migliore, puoi avviare una ricerca completa. Non è possibile sapere in anticipo quante prove serviranno per convergere. Il numero di prove in cui avviene la convergenza può variare in base alle dimensioni dello spazio di ricerca, ma in genere si tratta dell'ordine di circa 2000 prove.
Consigliamo un'impostazione molto alta
per --max_nas_trial: circa 5000-10.000 e poi
annullare prima il job di ricerca se
il grafico di ricerca mostra la convergenza.
Puoi anche riprendere un job di ricerca precedente utilizzando il comando search_resume.
Tuttavia, non puoi riprendere la ricerca da un altro job di ripristino della ricerca.
Di conseguenza, puoi riprendere un job di ricerca originale solo una volta.
Impostazione delle prove parallele
Il job di ricerca fase 1 esegue l'elaborazione batch eseguendo --max_parallel_nas_trial di prove in parallelo alla volta. Questo è fondamentale per ridurre il tempo di esecuzione
complessivo del job di ricerca. Puoi calcolare il numero previsto di giorni per la ricerca:
days-required-for-search = (trials-to-converge / max-parallel-nas-trial) * (avg-trial-duration-in-hours / 24)
Nota: inizialmente puoi utilizzare 3000 come stima approssimativa di trials-to-converge, che corrisponde al limite massimo iniziale. Inizialmente puoi utilizzare 2 ore come stima approssimativa di avg-trial-duration-in-hours, che rappresenta un buon limite superiore per il tempo impiegato da ogni attività proxy.
Ti consigliamo di
utilizzare l'impostazione --max_parallel_nas_trial compresa
~20-50, a seconda della quota di acceleratori
di cui dispone il progetto e
days-required-for-search.
Ad esempio, se imposti --max_parallel_nas_trial su 20 e ogni attività proxy utilizza due GPU NVIDIA T4, dovresti aver prenotato una quota di almeno 40 GPU NVIDIA T4. L'impostazione --max_parallel_nas_trial non influisce sul risultato di ricerca complessivo, ma influisce su days-required-for-search.
È possibile anche un'impostazione più piccola per max_parallel_nas_trial, ad esempio circa 10 (20 GPU), ma poi dovresti stimare approssimativamente il valore days-required-for-search e assicurarti che rientri nel limite di timeout del job.
Il job di addestramento stage2 in genere addestra tutte le prove in parallelo per impostazione predefinita. In genere, si tratta delle prime 10 prove in parallelo. Tuttavia, se ogni prova di addestramento completo di fase 2 utilizza troppe GPU (ad esempio, otto GPU ciascuna) per il tuo caso d'uso e non disponi di una quota sufficiente, puoi eseguire manualmente i job di fase 2 in batch, ad esempio eseguire prima un addestramento stage2 completo per solo cinque prove e poi eseguire un altro addestramento stage2 completo per le 5 prove successive.
Timeout job predefinito
Il timeout predefinito del job NAS è impostato su 14 giorni, dopodiché il job viene annullato. Se prevedi di eseguire il job per un periodo più lungo, puoi provare a ripristinarlo solo una volta per altri 14 giorni. Nel complesso, puoi eseguire un job di ricerca per 28 giorni, incluso il curriculum.
Impostazione del numero massimo di prove non riuscite
Il numero massimo di prove non riuscite deve essere impostato a circa 1/3 dell'impostazione di max_nas_trial. Il job verrà annullato quando il numero di prove non riuscite raggiungerà questo limite.
Quando interrompere la ricerca
Dovresti interrompere la ricerca quando:
La curva di ricerca inizia a convergere (la varianza diminuisce):
Nota: se non viene utilizzato alcun vincolo di latenza o se viene utilizzato un vincolo di latenza rigido con un limite di latenza allentato, la curva potrebbe non mostrare un aumento del premio, ma dovrebbe comunque mostrare convergenza. Il motivo è che il titolare del trattamento potrebbe aver già rilevato buone imprecisioni nelle ricerche.Oltre il 20% delle tue prove mostra premi non validi (errori):

La curva di ricerca non aumenta né converge (come mostrato sopra) anche dopo circa 500 prove. Se invece mostra un aumento o una diminuzione della variazione del premio, puoi continuare.