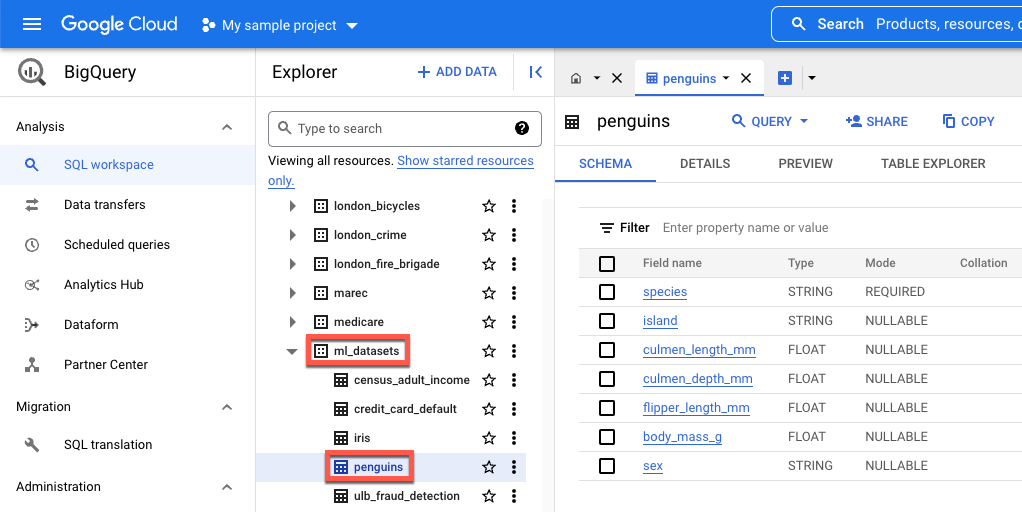
island: l'isola in cui è stata trovata una specie di pinguino.culmen_length_mm: la lunghezza del crinale lungo la sommità del becco di un pinguino.culmen_depth_mm: l'altezza del becco di un pinguino.flipper_length_mm: la lunghezza dell'ala simile a una pinna di un pinguino.body_mass_g: la massa del corpo di un pinguino.sex: il genere del pinguino.
Scaricare, pre-elaborare e suddividere i dati
In questa sezione scaricherai il set di dati BigQuery disponibile pubblicamente e preparerai i relativi dati. Per preparare i dati:
Convertire le caratteristiche categoriche (caratteristiche descritte con una stringa anziché un numero) in dati numerici. Ad esempio, convertirai i nomi dei tre tipi di pinguini nei valori numerici
0,1e2.Rimuovi nel set di dati tutte le colonne che non vengono utilizzate.
Rimuovi le righe che non possono essere utilizzate.
Suddividi i dati in due insiemi distinti di dati. Ogni set di dati viene archiviato in un oggetto panda
DataFrame.L'elemento
df_trainDataFramecontiene i dati utilizzati per addestrare il modello.l'elemento
df_for_predictionDataFramecontiene dati utilizzati per generare previsioni.
Dopo l'elaborazione dei dati, il codice mappa i valori numerici delle tre colonne categoriche ai rispettivi valori stringa, quindi li stampa in modo che tu possa vedere l'aspetto dei dati.
Per scaricare ed elaborare i dati, esegui questo codice nel blocco note:
import numpy as np
import pandas as pd
LABEL_COLUMN = "species"
# Define the BigQuery source dataset
BQ_SOURCE = "bigquery-public-data.ml_datasets.penguins"
# Define NA values
NA_VALUES = ["NA", "."]
# Download a table
table = bq_client.get_table(BQ_SOURCE)
df = bq_client.list_rows(table).to_dataframe()
# Drop unusable rows
df = df.replace(to_replace=NA_VALUES, value=np.NaN).dropna()
# Convert categorical columns to numeric
df["island"], island_values = pd.factorize(df["island"])
df["species"], species_values = pd.factorize(df["species"])
df["sex"], sex_values = pd.factorize(df["sex"])
# Split into a training and holdout dataset
df_train = df.sample(frac=0.8, random_state=100)
df_for_prediction = df[~df.index.isin(df_train.index)]
# Map numeric values to string values
index_to_island = dict(enumerate(island_values))
index_to_species = dict(enumerate(species_values))
index_to_sex = dict(enumerate(sex_values))
# View the mapped island, species, and sex data
print(index_to_island)
print(index_to_species)
print(index_to_sex)
Di seguito sono riportati i valori mappati stampati per le caratteristiche non numeriche:
{0: 'Dream', 1: 'Biscoe', 2: 'Torgersen'}
{0: 'Adelie Penguin (Pygoscelis adeliae)', 1: 'Chinstrap penguin (Pygoscelis antarctica)', 2: 'Gentoo penguin (Pygoscelis papua)'}
{0: 'FEMALE', 1: 'MALE'}
I primi tre valori sono le isole che potrebbe ospitare un pinguino. I secondi tre valori sono importanti perché corrispondono alle previsioni che ricevi alla fine di questo tutorial. La terza riga mostra la caratteristica sessuale FEMALE associata a
0 e la caratteristica MALE alla caratteristica sessuale 1.
Crea un set di dati tabulare per l'addestramento del modello
Nel passaggio precedente hai scaricato ed elaborato i tuoi dati. In questo passaggio, caricherai i dati archiviati in df_train DataFrame in un set di dati BigQuery. Poi userai il set di dati BigQuery per creare
un set di dati tabulare Vertex AI. Questo set di dati tabulare viene utilizzato
per addestrare il modello. Per ulteriori informazioni, consulta Utilizzare set di dati gestiti.
Crea un set di dati BigQuery
Per creare il set di dati BigQuery utilizzato per creare un
set di dati Vertex AI, esegui il codice seguente. Il comando create_dataset restituisce
un nuovo BigQuery DataSet.
# Create a BigQuery dataset
bq_dataset_id = f"{project_id}.dataset_id_unique"
bq_dataset = bigquery.Dataset(bq_dataset_id)
bq_client.create_dataset(bq_dataset, exists_ok=True)
Crea un set di dati tabulare Vertex AI
Per convertire il set di dati BigQuery in un set di dati tabulare
Vertex AI, esegui questo codice. Puoi ignorare l'avviso relativo al numero richiesto di righe da addestrare utilizzando i dati tabulari. Lo scopo di questo tutorial è mostrarti rapidamente come ottenere previsioni, pertanto viene utilizzato un set di dati relativamente ridotto per mostrarti come generare previsioni. In uno scenario reale, vuoi avere
almeno 1000 righe in un set di dati tabulare. Il comando create_from_dataframe restituisce un comando Vertex AI TabularDataset.
# Create a Vertex AI tabular dataset
dataset = aiplatform.TabularDataset.create_from_dataframe(
df_source=df_train,
staging_path=f"bq://{bq_dataset_id}.table-unique",
display_name="sample-penguins",
)
Ora hai il set di dati tabulare Vertex AI utilizzato per addestrare il modello.
(Facoltativo) Visualizza il set di dati pubblico in BigQuery
Se vuoi visualizzare i dati pubblici utilizzati in questo tutorial, puoi aprirli in BigQuery.
In Cerca in Google Cloud, inserisci BigQuery e premi Invio.
Nei risultati di ricerca, fai clic su BigQuery
Nella finestra Explorer, espandi bigquery-public-data.
In bigquery-public-data, espandi ml_datasets e poi fai clic su penguins.
Fai clic su uno dei nomi sotto Nome campo per visualizzare i dati del campo.