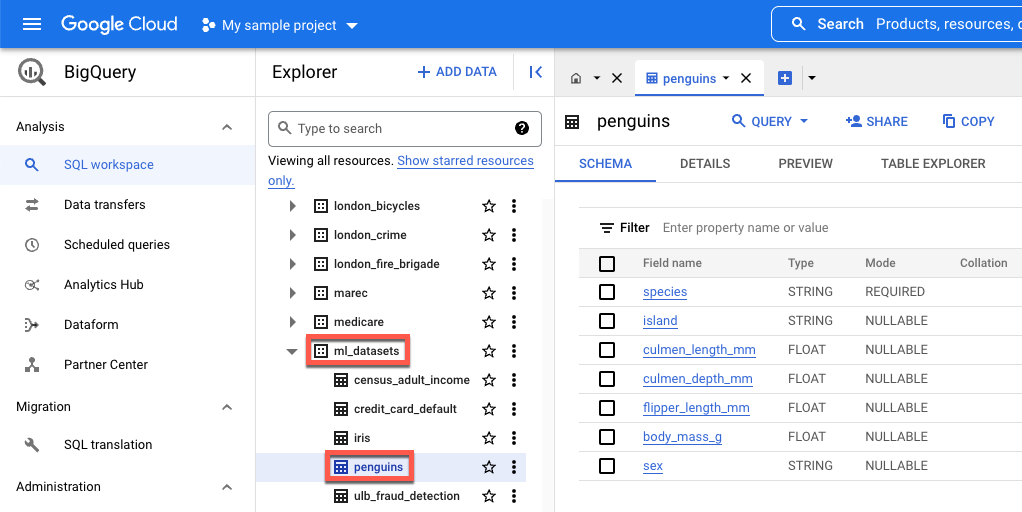
island- 펭귄의 종이 발견된 섬입니다.culmen_length_mm- 펭귄 부리 위쪽으로 이어지는 융선의 길이입니다.culmen_depth_mm- 펭귄 부리의 높이입니다.flipper_length_mm- 지느러미처럼 생긴 펭귄 날개의 길이입니다.body_mass_g- 펭귄의 체중입니다.sex- 펭귄의 성별입니다.
데이터 다운로드, 사전 처리 및 분할
이 섹션에서는 공개적으로 사용 가능한 BigQuery 데이터 세트를 다운로드하고 데이터를 준비합니다. 데이터를 준비하려면 다음을 수행하세요.
범주형 특성(숫자 대신 문자열로 설명되는 특성)을 숫자 데이터로 변환합니다. 예를 들어 세 가지 유형의 펭귄 이름을 숫자 값
0,1,2로 변환합니다.데이터 세트에서 사용하지 않는 열을 삭제합니다.
사용할 수 없는 행을 모두 삭제합니다.
데이터를 2개의 개별 데이터 세트로 분할합니다. 각 데이터 세트는 Pandas
DataFrame객체에 저장됩니다.df_trainDataFrame에는 모델을 학습시키는 데 사용되는 데이터가 포함됩니다.df_for_predictionDataFrame에는 예측을 생성하는 데 사용되는 데이터가 포함됩니다.
데이터를 처리한 후 이 코드는 범주형 3개 열의 숫자 값을 문자열 값에 매핑한 다음 데이터가 어떻게 표시되는지 확인할 수 있도록 인쇄합니다.
데이터를 다운로드하고 처리하려면 노트북에서 다음 코드를 실행합니다.
import numpy as np
import pandas as pd
LABEL_COLUMN = "species"
# Define the BigQuery source dataset
BQ_SOURCE = "bigquery-public-data.ml_datasets.penguins"
# Define NA values
NA_VALUES = ["NA", "."]
# Download a table
table = bq_client.get_table(BQ_SOURCE)
df = bq_client.list_rows(table).to_dataframe()
# Drop unusable rows
df = df.replace(to_replace=NA_VALUES, value=np.NaN).dropna()
# Convert categorical columns to numeric
df["island"], island_values = pd.factorize(df["island"])
df["species"], species_values = pd.factorize(df["species"])
df["sex"], sex_values = pd.factorize(df["sex"])
# Split into a training and holdout dataset
df_train = df.sample(frac=0.8, random_state=100)
df_for_prediction = df[~df.index.isin(df_train.index)]
# Map numeric values to string values
index_to_island = dict(enumerate(island_values))
index_to_species = dict(enumerate(species_values))
index_to_sex = dict(enumerate(sex_values))
# View the mapped island, species, and sex data
print(index_to_island)
print(index_to_species)
print(index_to_sex)
다음은 숫자가 아닌 특성에 대해 인쇄되는 매핑된 값입니다.
{0: 'Dream', 1: 'Biscoe', 2: 'Torgersen'}
{0: 'Adelie Penguin (Pygoscelis adeliae)', 1: 'Chinstrap penguin (Pygoscelis antarctica)', 2: 'Gentoo penguin (Pygoscelis papua)'}
{0: 'FEMALE', 1: 'MALE'}
처음 세 개의 값은 펭귄이 서식할 수 있는 섬입니다. 두 번째 세 값은 이 튜토리얼의 끝부분에서 받는 예측에 매핑되므로 중요합니다. 세 번째 행은 FEMALE 성별 특성을 0에 매핑하고 MALE 성별 특성을 1에 매핑합니다.
모델 학습을 위한 테이블 형식 데이터 세트 만들기
이전 단계에서 데이터를 다운로드하고 처리했습니다. 이 단계에서는 df_train DataFrame에 저장된 데이터를 BigQuery 데이터 세트에 로드합니다. 그런 다음 BigQuery 데이터 세트를 사용하여 Vertex AI 테이블 형식 데이터 세트를 만듭니다. 이 테이블 형식 데이터 세트는 모델을 학습시키는 데 사용됩니다. 자세한 내용은 관리형 데이터 세트 사용을 참조하세요.
BigQuery 데이터 세트 만들기
Vertex AI 데이터 세트를 만드는 데 사용되는 BigQuery 데이터 세트를 만들려면 다음 코드를 실행합니다. create_dataset 명령어는 새 BigQuery DataSet를 반환합니다.
# Create a BigQuery dataset
bq_dataset_id = f"{project_id}.dataset_id_unique"
bq_dataset = bigquery.Dataset(bq_dataset_id)
bq_client.create_dataset(bq_dataset, exists_ok=True)
Vertex AI 테이블 형식 데이터 세트 만들기
BigQuery 데이터 세트를 Vertex AI 테이블 형식 데이터 세트로 변환하려면 다음 코드를 실행합니다. 표 형식 데이터를 사용하여 학습을 수행하는 데 필요한 행 수에 관한 경고는 무시할 수 있습니다. 이 튜토리얼의 목적은 예측을 가져오는 방법을 빠르게 보여주기 위한 것이며, 비교적 적은 데이터 집합을 사용하여 예측을 생성하는 방법을 보여줍니다. 실제 시나리오에서는 표 형식 데이터 세트에 최소 1,000개 이상 행이 필요합니다. create_from_dataframe 명령어는 Vertex AI TabularDataset를 반환합니다.
# Create a Vertex AI tabular dataset
dataset = aiplatform.TabularDataset.create_from_dataframe(
df_source=df_train,
staging_path=f"bq://{bq_dataset_id}.table-unique",
display_name="sample-penguins",
)
이제 모델을 학습시키는 데 사용할 Vertex AI 테이블 형식 데이터 세트를 확보했습니다.
(선택사항) BigQuery에서 공개 데이터 세트 보기
이 튜토리얼에 사용된 공개 데이터를 보려면 BigQuery에서 열면 됩니다.
Google Cloud의 검색에서 BigQuery를 입력한 다음 Return 키를 누릅니다.
검색 결과에서 BigQuery를 클릭합니다.
탐색기 창에서 bigquery-public-data를 펼칩니다.
bigquery-public-data에서 ml_datasets를 펼친 후 penguins를 클릭합니다.
필드 이름에서 이름을 클릭하여 해당 필드의 데이터를 확인합니다.