JupyterLab 内から BigQuery 内のデータにクエリを実行する
このページでは、Vertex AI Workbench インスタンスの JupyterLab インターフェースから BigQuery に保存されているデータのクエリを実行する方法について説明します。
ノートブック(IPYNB)ファイルの BigQuery データのクエリを実行する方法
JupyterLab ノートブック ファイルから BigQuery データのクエリを実行するには、%%bigquery マジック コマンドと Python 用 BigQuery クライアント ライブラリを使用します。
Vertex AI Workbench インスタンスには、JupyterLab インターフェース内からデータの参照やクエリを実行できる BigQuery のインテグレーションも含まれています。
このページでは、それぞれの方法について説明します。
始める前に
まだ作成していない場合は、Vertex AI Workbench インスタンスを作成します。
必要なロール
インスタンスのサービス アカウントに BigQuery でデータのクエリを実行するために必要な権限を付与するには、プロジェクトで Service Usage ユーザー(roles/serviceusage.serviceUsageConsumer)IAM ロールをインスタンスのサービス アカウントに付与するように管理者へ依頼してください。ロールの付与の詳細については、アクセス権の管理に関する記事をご覧ください。
管理者は、インスタンスのサービス アカウントに、カスタムロールや他の事前定義ロールを使用して必要な権限を付与することもできます。
JupyterLab を開く
Google Cloud コンソールで、[インスタンス] ページに移動します。
Vertex AI Workbench インスタンス名の横にある [JupyterLab を開く] をクリックします。
Vertex AI Workbench インスタンスで JupyterLab が表示されます。
BigQuery リソースを参照する
BigQuery 統合では、アクセス可能な BigQuery リソースを表示するためのペインが提供されます。
JupyterLab のナビゲーション メニューで
 [BigQuery in Notebooks] をクリックします。
[BigQuery in Notebooks] をクリックします。[BigQuery] ペインに、使用可能なプロジェクトとデータセットが一覧表示されます。ここで、次のタスクを実行できます。
- データセットの説明を表示する。データセットの名前をダブルクリックします。
- データセットのテーブル、ビュー、モデルを表示する。データセットを開きます。
- 概要説明を JupyterLab のタブとして開く。テーブル、ビュー、またはモデルをダブルクリックします。
注: テーブルの概要説明で [Preview] タブをクリックして、テーブルデータをプレビューします。次の図は、
bigquery-public-dataプロジェクトのgoogle_trendsデータセットにあるinternational_top_termsテーブルのプレビューを示しています。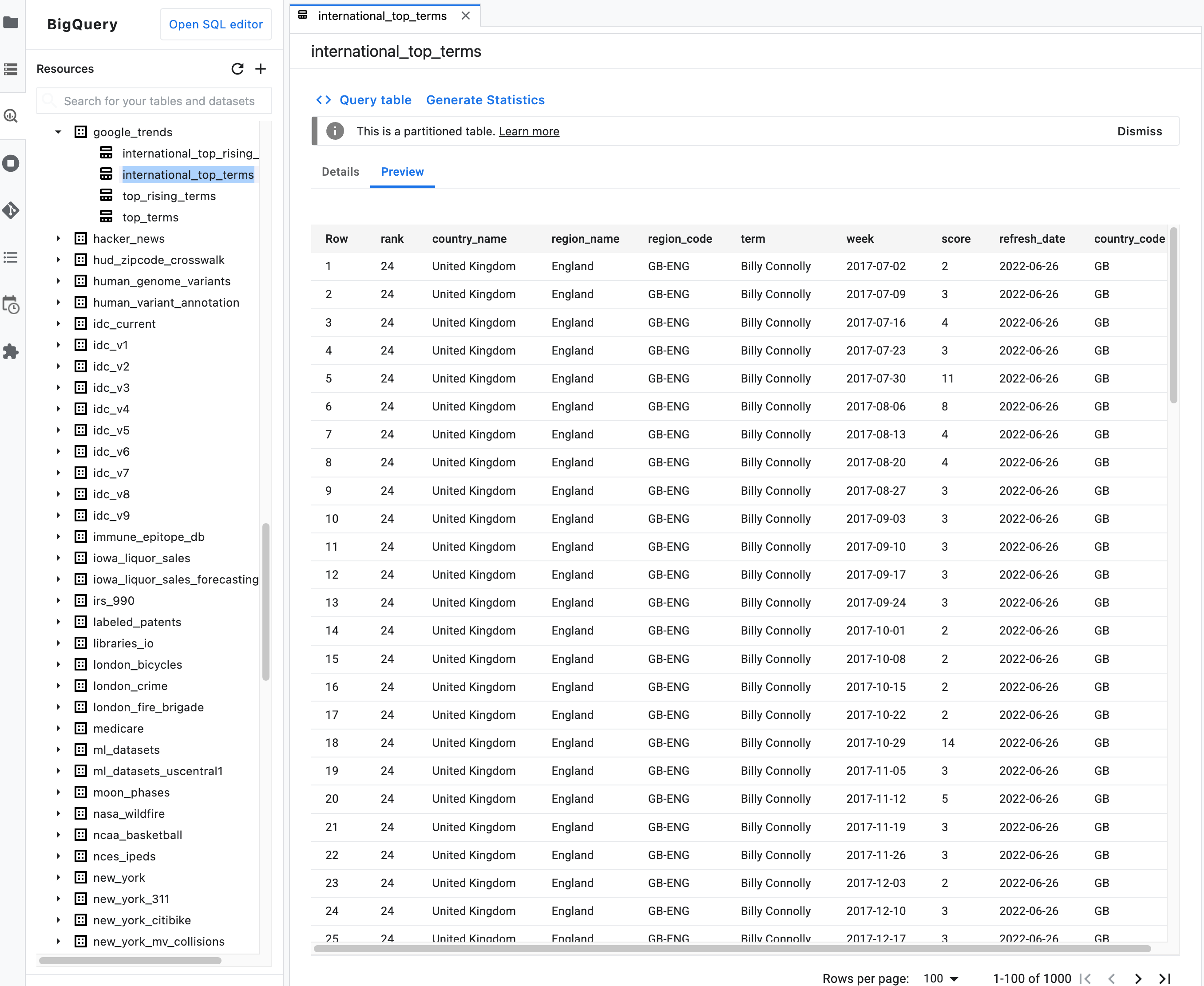
%%bigquery マジック コマンドを使用してデータのクエリを実行する
このセクションでは、ノートブック セルに SQL を直接記述し、BigQuery から Python ノートブックにデータを読み取ります。
1 個または 2 個のパーセント記号(% または %%)が付いたマジック コマンドを使用すると、ノートブック内で最小限の構文を使用して BigQuery を操作できます。Python 用の BigQuery クライアント ライブラリは、Vertex AI Workbench インスタンスに自動的にインストールされます。%%bigquery マジック コマンドは、バックグラウンドで Python 用 BigQuery クライアント ライブラリを使用して指定のクエリを実行し、結果を Pandas DataFrame に変換(オプションで結果を変数に保存)して、それを表示します。
注: google-cloud-bigquery Python パッケージのバージョン 1.26.0 では、%%bigquery マジックから結果をダウンロードする際にデフォルトで BigQuery Storage API が使用されます。
ノートブック ファイルを開くには、[File] > [New] > [Notebook] の順に選択します。
[Select Kernel] ダイアログで [Python 3] を選択し、[Select] をクリックします。
新しい IPYNB ファイルが開きます。
international_top_termsデータセット内の国別のリージョン数を取得するには、次のステートメントを入力します。%%bigquery SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
[ Run cell] をクリックします。
出力は次のようになります。
Query complete after 0.07s: 100%|██████████| 4/4 [00:00<00:00, 1440.60query/s] Downloading: 100%|██████████| 41/41 [00:02><00:00, 20.21rows/s] ... country_code country_name num_regions 0 TR Turkey 81 1 TH Thailand 77 2 VN Vietnam 63 3 JP Japan 47 4 RO Romania 42 5 NG Nigeria 37 6 IN India 36 7 ID Indonesia 34 8 CO Colombia 33 9 MX Mexico 32 10 BR Brazil 27 11 EG Egypt 27 12 UA Ukraine 27 13 CH Switzerland 26 14 AR Argentina 24 15 FR France 22 16 SE Sweden 21 17 HU Hungary 20 18 IT Italy 20 19 PT Portugal 20 20 NO Norway 19 21 FI Finland 18 22 NZ New Zealand 17 23 PH Philippines 17>
次のセル(前のセルの出力の下)で、以下のコマンドを入力して同じクエリを実行します。ただし、今回は
regions_by_countryという名前の新しい pandas DataFrame に結果を保存します。この名前は、%%bigqueryマジック コマンドで引数を使用して指定します。%%bigquery regions_by_country SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
注:
%%bigqueryコマンドで使用できる引数の詳細については、クライアント ライブラリのマジックのドキュメントをご覧ください。[ Run cell] をクリックします。
次のセルで以下のコマンドを入力すると、先ほど読み取ったクエリ結果の最初の数行が表示されます。
regions_by_country.head()[ Run cell] をクリックします。
これで、pandas DataFrame
regions_by_countryをプロットに使用する準備ができました。
BigQuery クライアント ライブラリを直接使用してデータをクエリする
このセクションでは、Python 用 BigQuery クライアント ライブラリを直接使用して Python ノートブックにデータを読み込みます。
クライアント ライブラリを使用すると、クエリをより詳細に制御できます。また、クエリとジョブでより複雑な構成を使用することもできます。ライブラリと pandas のインテグレーションにより、宣言型の SQL の機能と命令コード(Python)を組み合わせて、データの分析、可視化、変換を行うことができます。
注: Python 用にさまざまなデータ分析、データ ラングリング、可視化のライブラリが用意されています(numpy、pandas、matplotlib など)。これらのライブラリのいくつかは DataFrame オブジェクトを基盤とします。
次のセルに以下の Python コードを入力して、Python 用 BigQuery クライアント ライブラリをインポートし、クライアントを初期化します。
from google.cloud import bigquery client = bigquery.Client()BigQuery クライアントは、BigQuery API との間のメッセージの送受信に使用されます。
[ Run cell] をクリックします。
次のセルに以下のコードを入力して、米国の
top_termsで 1 日の上位語句の重なりの割合を日数差で取得します。これは、各日の上位語句が前日、2 日前、3 日前と何 % 重なっているのかを調べるものです(約 1 か月間のすべての日付ペアについて調べます)。sql = """ WITH TopTermsByDate AS ( SELECT DISTINCT refresh_date AS date, term FROM `bigquery-public-data.google_trends.top_terms` ), DistinctDates AS ( SELECT DISTINCT date FROM TopTermsByDate ) SELECT DATE_DIFF(Dates2.date, Date1Terms.date, DAY) AS days_apart, COUNT(DISTINCT (Dates2.date || Date1Terms.date)) AS num_date_pairs, COUNT(Date1Terms.term) AS num_date1_terms, SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)) AS overlap_terms, SAFE_DIVIDE( SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)), COUNT(Date1Terms.term) ) AS pct_overlap_terms FROM TopTermsByDate AS Date1Terms CROSS JOIN DistinctDates AS Dates2 LEFT JOIN TopTermsByDate AS Date2Terms ON Dates2.date = Date2Terms.date AND Date1Terms.term = Date2Terms.term WHERE Date1Terms.date <= Dates2.date GROUP BY days_apart ORDER BY days_apart; """ pct_overlap_terms_by_days_apart = client.query(sql).to_dataframe() pct_overlap_terms_by_days_apart.head()使用する SQL は Python 文字列にカプセル化されて
query()メソッドに渡され、クエリが実行されます。クエリが完了すると、to_dataframeメソッドは BigQuery Storage API を使用して結果を pandas DataFrame にダウンロードします。[ Run cell] をクリックします。
クエリ結果の最初の数行がコードセルの下に表示されます。
days_apart num_date_pairs num_date1_terms overlap_terms pct_overlap_terms 0 0 32 800 800 1.000000 1 1 31 775 203 0.261935 2 2 30 750 73 0.097333 3 3 29 725 31 0.042759 4 4 28 700 23 0.032857
BigQuery クライアント ライブラリの詳しい使用方法については、クイックスタートのクライアント ライブラリの使用をご覧ください。
Vertex AI Workbench で BigQuery のインテグレーションを使用してデータのクエリを実行する
BigQuery のインテグレーションでは、次の 2 つの方法でデータのクエリを実行できます。これらの方法は、%%bigquery マジック コマンドの使用とは異なります。
セル内クエリエディタは、ノートブック ファイル内で使用できるセルタイプです。
JupyterLab では、スタンドアロンのクエリエディタが別のタブとして開きます。
セル内
セル内クエリエディタを使用して BigQuery テーブルのデータのクエリを実行するには、次の手順を行います。
JupyterLab で、ノートブック(IPYNB)ファイルを開くか、新規に作成します。
セル内クエリエディタを作成するには、セルをクリックし、セルの右側にある [ BigQuery Integration] ボタンをクリックします。または、マークダウン セルに「
#@BigQuery」と入力します。BigQuery 統合により、セルがセル内クエリエディタに変換されます。
#@BigQueryの下の新しい行で、BigQuery でサポートされているステートメントと SQL 言語を使用してクエリを作成します。クエリ内でエラーが見つかると、クエリエディタの右上にエラー メッセージが表示されます。クエリが有効な場合は、処理される推定バイト数が表示されます。[Submit Query] をクリックします。クエリ結果が表示されます。デフォルトでは、クエリ結果は 1 ページあたり 100 行、ページあたり 1,000 行に制限されますが、この設定は結果テーブルの下部で変更できます。クエリエディタで、クエリの検証に必要なデータにクエリを限定します。このクエリをノートブック セルで再度実行します。必要に応じて上限を調整して、完全な結果セットを取得することもできます。
[Query and load as DataFrame] をクリックすると、Python 用の BigQuery クライアント ライブラリをインポートしてノートブックでクエリを実行するコード セグメントを含む新しいセルが自動的に追加されます。結果を
dfという名前の pandas データフレームに格納します。
スタンドアロン
スタンドアロン クエリエディタを使用して BigQuery テーブルのデータをクエリするには、次の手順を行います。
JupyterLab の [BigQuery in Notebooks] ペインで、テーブルを右クリックして [Query table] を選択するか、テーブルをダブルクリックして開きます。説明を入力して、[Query table] リンクをクリックします。
BigQuery でサポートされているステートメントと SQL 言語を使用してクエリを作成します。クエリ内でエラーが見つかると、クエリエディタの右上にエラー メッセージが表示されます。クエリが有効な場合は、処理される推定バイト数が表示されます。
[Submit Query] をクリックします。クエリ結果が表示されます。デフォルトでは、クエリ結果は 1 ページあたり 100 行、ページあたり 1,000 行に制限されますが、この設定は結果テーブルの下部で変更できます。クエリエディタで、クエリの検証に必要なデータにクエリを限定します。このクエリをノートブック セルで再度実行します。必要に応じて上限を調整して、完全な結果セットを取得することもできます。
[Copy code for DataFrame] をクリックすると、Python 用 BigQuery クライアント ライブラリをインポートし、ノートブック セルでクエリを実行して結果を保存するコード セグメントが
dfという名前の pandas データフレームにコピーされます。実行するノートブック セルに、このコードを貼り付けます。
クエリ履歴を表示してクエリを再利用する
JupyterLab でクエリ履歴をタブとして表示するには、次の手順に沿って操作します。
JupyterLab のナビゲーション メニューで [
BigQuery in Notebooks] をクリックして [BigQuery] ペインを開きます。[BigQuery] ペインで下にスクロールして、[Query history] をクリックします。
クエリのリストが新しいタブで開きます。ここでは、次のような操作を実行できます。
- ジョブ ID、クエリの実行日時、所要時間など、クエリの詳細を表示するには、クエリをクリックします。
- クエリの修正、再実行、または今後使用するためにノートブックにコピーするには、[Open query in editor] をクリックします。
次のステップ
BigQuery テーブルのデータを可視化する方法の例については、JupyterLab 内から BigQuery のデータを探索して可視化するをご覧ください。
BigQuery のクエリの作成について詳しくは、インタラクティブ クエリ ジョブとバッチクエリ ジョブの実行をご覧ください。
BigQuery データセットのアクセス制御の方法を学習する。