In diesem Dokument werden Sie durch die erforderlichen Schritte zum Erstellen einer Pipeline geführt, die automatisch ein benutzerdefiniertes Modell trainiert, wenn neue Daten mithilfe von Vertex AI Pipelines und Cloud Functions in das Dataset eingefügt werden.
Lernziele
Dieser Vorgang wird durch folgende Schritte behandelt:
Erstellen Sie ein Dataset in BigQuery und bereiten Sie es vor.
Erstellen Sie ein benutzerdefiniertes Trainingspaket und laden Sie es hoch. Bei der Ausführung liest es Daten aus dem Dataset und trainiert das Modell.
Erstellen Sie eine Vertex AI-Pipeline. Diese Pipeline führt das benutzerdefinierte Trainingspaket aus, lädt das Modell in die Vertex AI Model Registry hoch, führt den Bewertungsjob aus und sendet eine E-Mail-Benachrichtigung.
Führen Sie die Pipeline manuell aus.
Erstellen Sie eine Cloud Functions-Funktion mit einem Eventarc-Trigger, der die Pipeline immer dann ausführt, wenn neue Daten in das BigQuery-Dataset eingefügt werden.
Vorbereitung
Richten Sie Ihr Projekt und Notebook ein.
Projekt einrichten
-
Rufen Sie in der Google Cloud Console die Seite für die Projektauswahl auf.
-
Wählen Sie ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
Notebook erstellen
In dieser Anleitung verwenden wir ein Colab Enterprise-Notebook, um einen Teil des Codes auszuführen.
Wenn Sie nicht der Projektinhaber sind, bitten Sie einen Projektinhaber, Ihnen die IAM-Rollen
roles/resourcemanager.projectIamAdminundroles/aiplatform.colabEnterpriseUserzuzuweisen.Sie benötigen diese Rollen, um Colab Enterprise zu verwenden und sich selbst und den Dienstkonten IAM-Rollen und -Berechtigungen zuzuweisen.
Rufen Sie in der Google Cloud Console die Colab Enterprise-Seite Notebooks auf.
Colab Enterprise fordert Sie auf, die folgenden erforderlichen APIs zu aktivieren, falls sie noch nicht aktiviert sind.
- Vertex AI API
- Dataform API
- Compute Engine API
Wählen Sie im Menü Region die Region aus, in der Sie Ihr Notebook erstellen möchten. Wenn Sie sich nicht sicher sind, verwenden Sie us-central1 als Region.
Verwenden Sie für alle Ressourcen in dieser Anleitung dieselbe Region.
Klicken Sie auf Neues Notebook erstellen.
Ihr neues Notebook wird auf dem Tab Meine Notebooks angezeigt. Fügen Sie eine Codezelle hinzu und klicken Sie auf die Schaltfläche Zelle ausführen, um Code in Ihrem Notebook auszuführen.
Entwicklungsumgebung einrichten
Installieren Sie in Ihrem Notebook die folgenden Python3-Pakete.
! pip3 install google-cloud-aiplatform==1.34.0 \ google-cloud-pipeline-components==2.6.0 \ kfp==2.4.0 \ scikit-learn==1.0.2 \ mlflow==2.10.0Führen Sie Folgendes aus, um das Google Cloud CLI-Projekt festzulegen:
PROJECT_ID = "PROJECT_ID" # Set the project id ! gcloud config set project {PROJECT_ID}Ersetzen Sie PROJECT_ID durch Ihre Projekt-ID. Sie finden Ihre Projekt-ID gegebenenfalls in der Google Cloud Console.
Gewähren Sie Ihrem Google-Konto Rollen:
! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/bigquery.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.user ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/storage.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/pubsub.editor ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/cloudfunctions.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.viewer ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.configWriter ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/iam.serviceAccountUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/eventarc.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.colabEnterpriseUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/artifactregistry.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/serviceusage.serviceUsageAdminAktivieren Sie folgende APIs
- Artifact Registry API
- BigQuery API
- Cloud Build API
- Cloud Functions API
- Cloud Logging API
- Pub/Sub API
- Cloud Run Admin API
- Cloud Storage API
- Eventarc API
- Service Usage API
- Vertex AI API
! gcloud services enable artifactregistry.googleapis.com bigquery.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com logging.googleapis.com pubsub.googleapis.com run.googleapis.com storage-component.googleapis.com eventarc.googleapis.com serviceusage.googleapis.com aiplatform.googleapis.comWeisen Sie den Dienstkonten Ihres Projekts Rollen zu:
Sehen Sie sich die Namen Ihrer Dienstkonten an
! gcloud iam service-accounts listNotieren Sie sich den Namen Ihres Compute-Dienst-Agents. Er sollte das Format
[email protected]haben.Weisen Sie dem Dienst-Agent die erforderlichen Rollen zu.
! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID[email protected]"" --role=roles/aiplatform.serviceAgent ! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID[email protected]"" --role=roles/eventarc.eventReceiver
Dataset abrufen und vorbereiten
In dieser Anleitung erstellen Sie ein Modell, das den Fahrpreis für eine Taxifahrt anhand von Merkmalen wie Fahrzeit, Standort und Entfernung vorhersagt. Wir verwenden Daten aus dem öffentlichen Dataset Chicago Taxi Trips. Dieses Dataset beinhaltet Taxifahrten von 2013 bis heute, die der Stadt Chicago in ihrer Rolle als Regulierungsbehörde gemeldet wurden. Um die Privatsphäre der Fahrer und Nutzer gleichzeitig zu schützen und dem Aggregator die Möglichkeit zu geben, die Daten zu analysieren, wird die Taxi-ID für jede Taxi-Medaillonnummer konsistent, ohne die Nummer zu zeigen. Erhebungsgebiete werden in einigen Fällen unterdrückt und die Zeiten werden auf die nächsten 15 Minuten aufgerundet.
Weitere Informationen finden Sie unter Chicago Taxi Trips auf Marketplace.
Erstellen Sie ein BigQuery-Dataset
Wechseln Sie in der Google Cloud Console zu BigQuery Studio.
Suchen Sie im Bereich Explorer nach Ihrem Projekt, klicken Sie auf Aktionen und dann auf Dataset erstellen.
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
mlopsein. Weitere Informationen finden Sie unter Dataset-Benennung.Wählen Sie als Standorttyp Ihren multiregionalen Standort aus. Wählen Sie beispielsweise USA (mehrere Regionen in den Vereinigten Staaten) aus, wenn Sie
us-central1verwenden. Nachdem ein Dataset erstellt wurde, kann der Standort nicht mehr geändert werden.Klicken Sie auf Dataset erstellen.
Weitere Informationen finden Sie unter Datasets erstellen.
BigQuery-Tabelle erstellen und füllen
In diesem Abschnitt erstellen Sie die Tabelle und importieren die Daten eines Jahres aus dem öffentlichen Dataset in das Dataset Ihres Projekts.
Zu BigQuery Studio
Klicken Sie auf SQL-Abfrage erstellen und führen Sie die folgende SQL-Abfrage aus. Klicken Sie dazu auf Ausführen.
CREATE OR REPLACE TABLE `PROJECT_ID.mlops.chicago` AS ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2019 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )Diese Abfrage erstellt die Tabelle
<PROJECT_ID>.mlops.chicagound füllt sie mit Daten aus der öffentlichen Tabellebigquery-public-data.chicago_taxi_trips.taxi_trips.Um das Tabellenschema aufzurufen, klicken Sie auf Zur Tabelle und dann auf den Tab Schema.
Klicken Sie auf den Tab Vorschau, um den Tabelleninhalt aufzurufen.
Benutzerdefiniertes Trainingspaket erstellen und hochladen
In diesem Abschnitt erstellen Sie ein Python-Paket, das den Code enthält, der das Dataset liest, die Daten in Trainings- und Test-Datasets aufteilt und Ihr benutzerdefiniertes Modell trainiert. Das Paket wird als eine der Aufgaben in der Pipeline ausgeführt. Weitere Informationen finden Sie unter Python-Trainingsanwendung für einen vordefinierten Container erstellen.
Benutzerdefiniertes Trainingspaket erstellen
Erstellen Sie in Ihrem Colab-Notebook übergeordnete Ordner für die Trainingsanwendung:
!mkdir -p training_package/trainerErstellen Sie mit dem folgenden Befehl in jedem Ordner eine Datei
__init__.py, um sie zu einem Paket zu machen:! touch training_package/__init__.py ! touch training_package/trainer/__init__.pyDie neuen Dateien und Ordner finden Sie im Ordner Dateien.
Erstellen Sie im Bereich Dateien eine Datei mit dem Namen
task.pyim Ordner training_package/trainer mit folgendem Inhalt.# Import the libraries from sklearn.model_selection import train_test_split, cross_val_score from sklearn.preprocessing import OneHotEncoder, StandardScaler from google.cloud import bigquery, bigquery_storage from sklearn.ensemble import RandomForestRegressor from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline from google import auth from scipy import stats import numpy as np import argparse import joblib import pickle import csv import os # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--project-id', dest='project_id', type=str, help='Project ID.') parser.add_argument('--training-dir', dest='training_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the data and the trained model.') parser.add_argument('--bq-source', dest='bq_source', type=str, help='BigQuery data source for training data.') args = parser.parse_args() # data preparation code BQ_QUERY = """ with tmp_table as ( SELECT trip_seconds, trip_miles, fare, tolls, company, pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude, DATETIME(trip_start_timestamp, 'America/Chicago') trip_start_timestamp, DATETIME(trip_end_timestamp, 'America/Chicago') trip_end_timestamp, CASE WHEN (pickup_community_area IN (56, 64, 76)) OR (dropoff_community_area IN (56, 64, 76)) THEN 1 else 0 END is_airport, FROM `{}` WHERE dropoff_latitude IS NOT NULL and dropoff_longitude IS NOT NULL and pickup_latitude IS NOT NULL and pickup_longitude IS NOT NULL and fare > 0 and trip_miles > 0 and MOD(ABS(FARM_FINGERPRINT(unique_key)), 100) between 0 and 99 ORDER BY RAND() LIMIT 10000) SELECT *, EXTRACT(YEAR FROM trip_start_timestamp) trip_start_year, EXTRACT(MONTH FROM trip_start_timestamp) trip_start_month, EXTRACT(DAY FROM trip_start_timestamp) trip_start_day, EXTRACT(HOUR FROM trip_start_timestamp) trip_start_hour, FORMAT_DATE('%a', DATE(trip_start_timestamp)) trip_start_day_of_week FROM tmp_table """.format(args.bq_source) # Get default credentials credentials, project = auth.default() bqclient = bigquery.Client(credentials=credentials, project=args.project_id) bqstorageclient = bigquery_storage.BigQueryReadClient(credentials=credentials) df = ( bqclient.query(BQ_QUERY) .result() .to_dataframe(bqstorage_client=bqstorageclient) ) # Add 'N/A' for missing 'Company' df.fillna(value={'company':'N/A','tolls':0}, inplace=True) # Drop rows containing null data. df.dropna(how='any', axis='rows', inplace=True) # Pickup and dropoff locations distance df['abs_distance'] = (np.hypot(df['dropoff_latitude']-df['pickup_latitude'], df['dropoff_longitude']-df['pickup_longitude']))*100 # Remove extremes, outliers possible_outliers_cols = ['trip_seconds', 'trip_miles', 'fare', 'abs_distance'] df=df[(np.abs(stats.zscore(df[possible_outliers_cols].astype(float))) < 3).all(axis=1)].copy() # Reduce location accuracy df=df.round({'pickup_latitude': 3, 'pickup_longitude': 3, 'dropoff_latitude':3, 'dropoff_longitude':3}) # Drop the timestamp col X=df.drop(['trip_start_timestamp', 'trip_end_timestamp'],axis=1) # Split the data into train and test X_train, X_test = train_test_split(X, test_size=0.10, random_state=123) ## Format the data for batch predictions # select string cols string_cols = X_test.select_dtypes(include='object').columns # Add quotes around string fields X_test[string_cols] = X_test[string_cols].apply(lambda x: '\"' + x + '\"') # Add quotes around column names X_test.columns = ['\"' + col + '\"' for col in X_test.columns] # Save DataFrame to csv X_test.to_csv(os.path.join(args.training_dir,"test.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Save test data without the target for batch predictions X_test.drop('\"fare\"',axis=1,inplace=True) X_test.to_csv(os.path.join(args.training_dir,"test_no_target.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Separate the target column y_train=X_train.pop('fare') # Get the column indexes col_index_dict = {col: idx for idx, col in enumerate(X_train.columns)} # Create a column transformer pipeline ct_pipe = ColumnTransformer(transformers=[ ('hourly_cat', OneHotEncoder(categories=[range(0,24)], sparse = False), [col_index_dict['trip_start_hour']]), ('dow', OneHotEncoder(categories=[['Mon', 'Tue', 'Sun', 'Wed', 'Sat', 'Fri', 'Thu']], sparse = False), [col_index_dict['trip_start_day_of_week']]), ('std_scaler', StandardScaler(), [ col_index_dict['trip_start_year'], col_index_dict['abs_distance'], col_index_dict['pickup_longitude'], col_index_dict['pickup_latitude'], col_index_dict['dropoff_longitude'], col_index_dict['dropoff_latitude'], col_index_dict['trip_miles'], col_index_dict['trip_seconds']]) ]) # Add the random-forest estimator to the pipeline rfr_pipe = Pipeline([ ('ct', ct_pipe), ('forest_reg', RandomForestRegressor( n_estimators = 20, max_features = 1.0, n_jobs = -1, random_state = 3, max_depth=None, max_leaf_nodes=None, )) ]) # train the model rfr_score = cross_val_score(rfr_pipe, X_train, y_train, scoring = 'neg_mean_squared_error', cv = 5) rfr_rmse = np.sqrt(-rfr_score) print ("Crossvalidation RMSE:",rfr_rmse.mean()) final_model=rfr_pipe.fit(X_train, y_train) # Save the model pipeline with open(os.path.join(args.training_dir,"model.pkl"), 'wb') as model_file: pickle.dump(final_model, model_file)Mit dem Code werden die folgenden Aufgaben ausgeführt:
- Auswahl von Merkmalen.
- Umwandeln der Abhol- und Ablieferungs-Datenzeit von UTC in die Ortszeit von Chicago.
- Extrahieren von Datum, Stunde, Wochentag, Monat und Jahr aus der DateTime der Abholung.
- Berechnen der Dauer der Fahrt anhand der Start- und Endzeit.
- Identifizieren und Markieren von Fahrten, die an einem Flughafen gestartet oder beendet wurden, basierend auf den Gemeindegebiete.
- Das Random Forest-Regressionsmodell wird trainiert, um den Fahrpreis der Taxifahrt mithilfe des scikit-learn-Frameworks vorherzusagen.
Das trainierte Modell wird in einer Pickle-Datei
model.pklgespeichert.Der ausgewählte Ansatz und das Feature Engineering basieren auf einer Datenexploration und -analyse zur Vorhersage von Chicago Taxi Fare.
Erstellen Sie im Bereich Dateien eine Datei mit dem Namen
setup.pyim Ordner training_package mit folgendem Inhalt.from setuptools import find_packages from setuptools import setup REQUIRED_PACKAGES=["google-cloud-bigquery[pandas]","google-cloud-bigquery-storage"] setup( name='trainer', version='0.1', install_requires=REQUIRED_PACKAGES, packages=find_packages(), include_package_data=True, description='Training application package for chicago taxi trip fare prediction.' )Führen Sie in Ihrem Notebook
setup.pyaus, um die Quelldistribution für Ihre Trainingsanwendung zu erstellen:! cd training_package && python setup.py sdist --formats=gztar && cd ..
Am Ende dieses Abschnitts sollte der Bereich Dateien die folgenden Dateien und Ordner unter training-package enthalten.
dist
trainer-0.1.tar.gz
trainer
__init__.py
task.py
trainer.egg-info
__init__.py
setup.py
Benutzerdefiniertes Trainingspaket in Cloud Storage hochladen
Cloud Storage-Bucket erstellen
REGION="REGION" BUCKET_NAME = "BUCKET_NAME" BUCKET_URI = f"gs://{BUCKET_NAME}" ! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URIErsetzen Sie die folgenden Parameterwerte:
REGION: Wählen Sie dieselbe Region aus, die Sie beim Erstellen Ihres Colab-Notebooks auswählen.BUCKET_NAME: Der Bucket-Name.
Laden Sie Ihr Trainingspaket in den Cloud Storage-Bucket hoch.
# Copy the training package to the bucket ! gsutil cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/
Pipeline erstellen
Eine Pipeline ist eine Beschreibung eines MLOps-Workflows als Grafik von Schritten, die als Pipelineaufgaben bezeichnet werden.
In diesem Abschnitt definieren Sie Ihre Pipelineaufgaben, kompilieren sie in YAML und registrieren Ihre Pipeline in Artifact Registry, damit sie der Versionskontrolle unterliegt und mehrmals ausgeführt werden kann, von einem einzelnen Nutzer oder von mehreren Nutzern.
Hier sehen Sie eine Visualisierung der Aufgaben in unserer Pipeline, darunter Modelltraining, Modellupload, Modellbewertung und E-Mail-Benachrichtigungen:
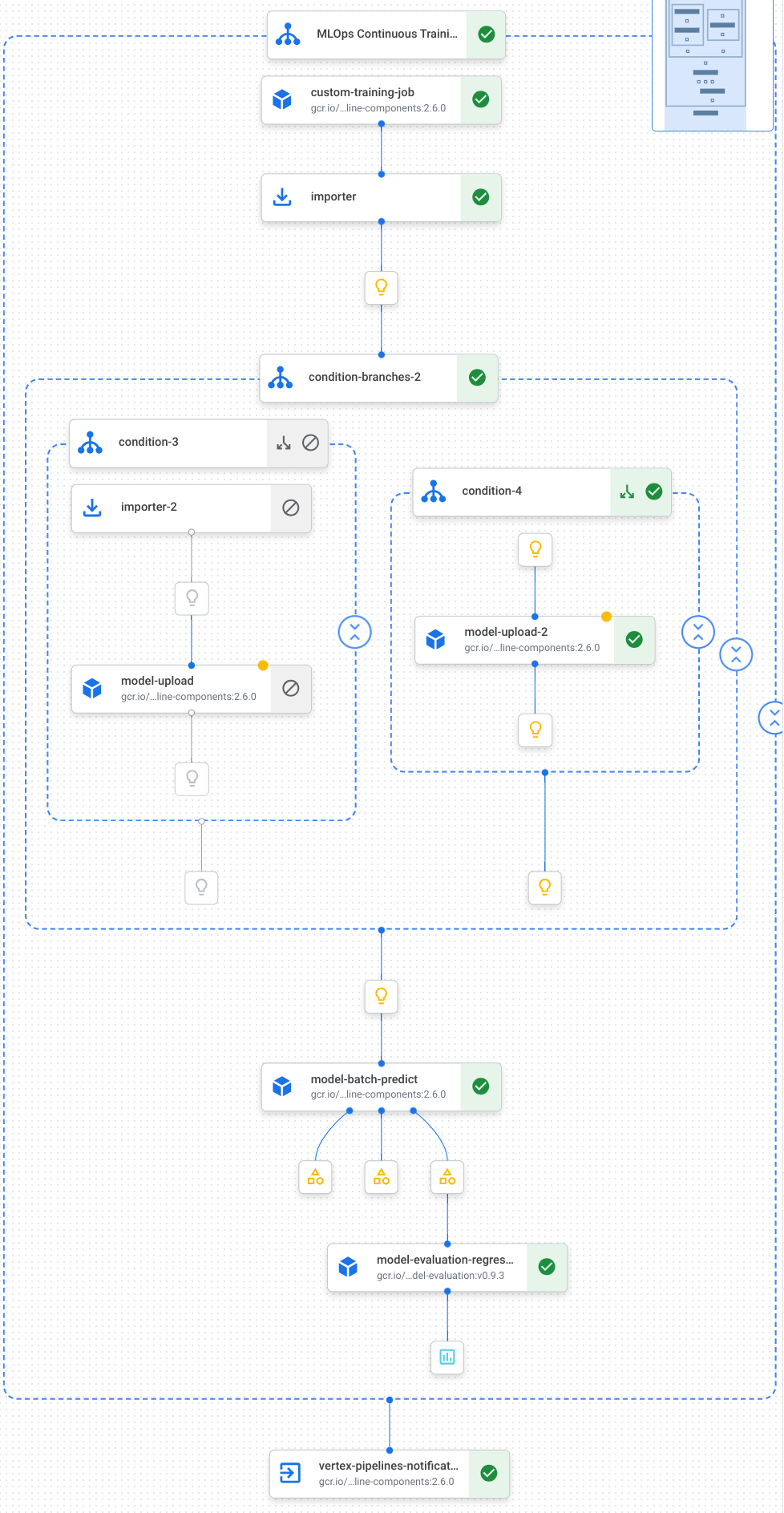
Weitere Informationen finden Sie unter Pipelinevorlagen erstellen.
Konstanten definieren und Clients initialisieren
Definieren Sie in Ihrem Notebook die Konstanten, die in späteren Schritten verwendet werden:
import os EMAIL_RECIPIENTS = [ "NOTIFY_EMAIL" ] PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-pipeline-datatrigger-tutorial" WORKING_DIR = f"{PIPELINE_ROOT}/mlops-datatrigger-tutorial" os.environ['AIP_MODEL_DIR'] = WORKING_DIR EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" PIPELINE_FILE = PIPELINE_NAME + ".yaml"Ersetzen Sie
NOTIFY_EMAILdurch eine E-Mail-Adresse. Wenn der Pipelinejob erfolgreich oder nicht erfolgreich abgeschlossen wurde, wird eine E-Mail an diese E-Mail-Adresse gesendet.Initialisieren Sie das Vertex AI SDK mit dem Projekt, dem Staging-Bucket, dem Standort und dem Test.
from google.cloud import aiplatform aiplatform.init( project=PROJECT_ID, staging_bucket=BUCKET_URI, location=REGION, experiment=EXPERIMENT_NAME) aiplatform.autolog()
Pipelineaufgaben definieren
Definieren Sie in Ihrem Notebook die Pipeline custom_model_training_evaluation_pipeline:
from kfp import dsl
from kfp.dsl import importer
from kfp.dsl import OneOf
from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp
from google_cloud_pipeline_components.types import artifact_types
from google_cloud_pipeline_components.v1.model import ModelUploadOp
from google_cloud_pipeline_components.v1.batch_predict_job import ModelBatchPredictOp
from google_cloud_pipeline_components.v1.model_evaluation import ModelEvaluationRegressionOp
from google_cloud_pipeline_components.v1.vertex_notification_email import VertexNotificationEmailOp
from google_cloud_pipeline_components.v1.endpoint import ModelDeployOp
from google_cloud_pipeline_components.v1.endpoint import EndpointCreateOp
from google.cloud import aiplatform
# define the train-deploy pipeline
@dsl.pipeline(name="custom-model-training-evaluation-pipeline")
def custom_model_training_evaluation_pipeline(
project: str,
location: str,
training_job_display_name: str,
worker_pool_specs: list,
base_output_dir: str,
prediction_container_uri: str,
model_display_name: str,
batch_prediction_job_display_name: str,
target_field_name: str,
test_data_gcs_uri: list,
ground_truth_gcs_source: list,
batch_predictions_gcs_prefix: str,
batch_predictions_input_format: str="csv",
batch_predictions_output_format: str="jsonl",
ground_truth_format: str="csv",
parent_model_resource_name: str=None,
parent_model_artifact_uri: str=None,
existing_model: bool=False
):
# Notification task
notify_task = VertexNotificationEmailOp(
recipients= EMAIL_RECIPIENTS
)
with dsl.ExitHandler(notify_task, name='MLOps Continuous Training Pipeline'):
# Train the model
custom_job_task = CustomTrainingJobOp(
project=project,
display_name=training_job_display_name,
worker_pool_specs=worker_pool_specs,
base_output_directory=base_output_dir,
location=location
)
# Import the unmanaged model
import_unmanaged_model_task = importer(
artifact_uri=base_output_dir,
artifact_class=artifact_types.UnmanagedContainerModel,
metadata={
"containerSpec": {
"imageUri": prediction_container_uri,
},
},
).after(custom_job_task)
with dsl.If(existing_model == True):
# Import the parent model to upload as a version
import_registry_model_task = importer(
artifact_uri=parent_model_artifact_uri,
artifact_class=artifact_types.VertexModel,
metadata={
"resourceName": parent_model_resource_name
},
).after(import_unmanaged_model_task)
# Upload the model as a version
model_version_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
parent_model=import_registry_model_task.outputs["artifact"],
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
with dsl.Else():
# Upload the model
model_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
# Get the model (or model version)
model_resource = OneOf(model_version_upload_op.outputs["model"], model_upload_op.outputs["model"])
# Batch prediction
batch_predict_task = ModelBatchPredictOp(
project= project,
job_display_name= batch_prediction_job_display_name,
model= model_resource,
location= location,
instances_format= batch_predictions_input_format,
predictions_format= batch_predictions_output_format,
gcs_source_uris= test_data_gcs_uri,
gcs_destination_output_uri_prefix= batch_predictions_gcs_prefix,
machine_type= 'n1-standard-2'
)
# Evaluation task
evaluation_task = ModelEvaluationRegressionOp(
project= project,
target_field_name= target_field_name,
location= location,
# model= model_resource,
predictions_format= batch_predictions_output_format,
predictions_gcs_source= batch_predict_task.outputs["gcs_output_directory"],
ground_truth_format= ground_truth_format,
ground_truth_gcs_source= ground_truth_gcs_source
)
return
Ihre Pipeline besteht aus einer Grafik von Aufgaben, die die folgenden Google Cloud-Pipeline-Komponenten verwenden:
CustomTrainingJobOp: Führt benutzerdefinierte Trainingsjobs in Vertex AI aus.ModelUploadOp: Lädt das trainierte Modell für maschinelles Lernen in die Modell-Registry hoch.ModelBatchPredictOp: Erstellt einen Batchvorhersagejob.ModelEvaluationRegressionOp: Bewertet einen Regressions-Batchjob.VertexNotificationEmailOp: Sendet E-Mail-Benachrichtigungen.
Pipeline kompilieren
Kompilieren Sie die Pipeline mithilfe des KFP-Compilers (Kubeflow Pipelines) in eine YAML-Datei, die eine hermetische Darstellung der Pipeline enthält.
from kfp import dsl
from kfp import compiler
compiler.Compiler().compile(
pipeline_func=custom_model_training_evaluation_pipeline,
package_path="{}.yaml".format(PIPELINE_NAME),
)
In Ihrem Arbeitsverzeichnis sollte eine YAML-Datei mit dem Namen vertex-pipeline-datatrigger-tutorial.yaml angezeigt werden.
Pipeline als Vorlage hochladen
Erstellen Sie in Artifact Registry ein Repository vom Typ
KFP.REPO_NAME = "mlops" # Create a repo in the artifact registry ! gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFPLaden Sie die kompilierte Pipeline in das Repository hoch.
from kfp.registry import RegistryClient host = f"http://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."}) TEMPLATE_URI = f"http://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest"Prüfen Sie in der Google Cloud Console, ob Ihre Vorlage unter Pipelinevorlagen angezeigt wird.
Pipeline manuell ausführen
Führen Sie sie manuell aus, um sicherzustellen, dass die Pipeline funktioniert.
Geben Sie in Ihrem Notebook die Parameter an, die zum Ausführen der Pipeline als Job erforderlich sind.
DATASET_NAME = "mlops" TABLE_NAME = "chicago" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID, "--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False }Erstellen Sie einen Pipelinejob und führen Sie ihn aus.
# Create a pipeline job job = aiplatform.PipelineJob( display_name="triggered_custom_regression_evaluation", template_path=TEMPLATE_URI , parameter_values=parameters, pipeline_root=BUCKET_URI, enable_caching=False ) # Run the pipeline job job.run()Der Job dauert etwa 30 Minuten.
In der Console sollte auf der Seite Pipelines eine neue Pipeline angezeigt werden:
Nach Abschluss der Pipelineausführung sollte in Vertex AI Model Registry entweder ein neues Modell mit dem Namen
taxifare-prediction-modeloder eine neue Modellversion angezeigt werden:Außerdem sollte ein neuer Batchvorhersagejob angezeigt werden:
Funktion erstellen, die Ihre Pipeline auslöst
In diesem Schritt erstellen Sie eine Cloud Functions-Funktion (2. Generation), die die Pipeline ausführt, wenn neue Daten in die BigQuery-Tabelle eingefügt werden.
Insbesondere verwenden wir einen Eventarc, um die Funktion jedes Mal auszulösen, wenn ein google.cloud.bigquery.v2.JobService.InsertJob-Ereignis auftritt. Die Funktion führt dann die Pipelinevorlage aus.
Weitere Informationen finden Sie unter Eventarc-Trigger und Unterstützte Ereignistypen.
Funktion mit Eventarc-Trigger erstellen
Wechseln Sie in der Google Cloud Console zu Cloud Functions.
Klicken Sie auf die Schaltfläche Funktion erstellen. Auf der Seite Konfiguration:
Wählen Sie als Umgebung 2. Generation aus.
Verwenden Sie für Funktionsname den Wert mlops.
Wählen Sie unter Region dieselbe Region wie Ihr Cloud Storage-Bucket und das Artifact Registry-Repository aus.
Wählen Sie für Trigger die Option Anderer Trigger aus. Der Bereich Eventarc-Trigger wird geöffnet.
Wählen Sie als Triggertyp die Option Google-Quellen aus.
Wählen Sie für Ereignisanbieter die Option BigQuery aus.
Wählen Sie
google.cloud.bigquery.v2.JobService.InsertJobals Ereignistyp aus.Wählen Sie unter Ressource die Option Bestimmte Ressource aus und geben Sie die BigQuery-Tabelle an.
projects/PROJECT_ID/datasets/mlops/tables/chicagoWählen Sie im Feld Region einen Speicherort für den Eventarc-Trigger aus, falls vorhanden. Weitere Informationen finden Sie unter Triggerstandort.
Klicken Sie auf Trigger speichern.
Wenn Sie aufgefordert werden, Dienstkonten Rollen zuzuweisen, klicken Sie auf Alle gewähren.
Klicken Sie auf Weiter, um die Seite Code aufzurufen. Auf der Seite Code:
Legen Sie als Laufzeit python 3.12 fest.
Setzen Sie den Einstiegspunkt auf
mlops_entrypoint.Öffnen Sie im Inline-Editor die Datei
main.pyund ersetzen Sie den Inhalt durch Folgendes:Ersetzen Sie
PROJECT_ID,REGION,BUCKET_NAMEdurch die Werte, die Sie zuvor verwendet haben.import json import functions_framework import requests import google.auth import google.auth.transport.requests # CloudEvent function to be triggered by an Eventarc Cloud Audit Logging trigger # Note: this is NOT designed for second-party (Cloud Audit Logs -> Pub/Sub) triggers! @functions_framework.cloud_event def mlops_entrypoint(cloudevent): # Print out the CloudEvent's (required) `type` property # See http://github.com/cloudevents/spec/blob/v1.0.1/spec.md#type print(f"Event type: {cloudevent['type']}") # Print out the CloudEvent's (optional) `subject` property # See http://github.com/cloudevents/spec/blob/v1.0.1/spec.md#subject if 'subject' in cloudevent: # CloudEvent objects don't support `get` operations. # Use the `in` operator to verify `subject` is present. print(f"Subject: {cloudevent['subject']}") # Print out details from the `protoPayload` # This field encapsulates a Cloud Audit Logging entry # See http://cloud.go888ogle.com.fqhub.com/logging/docs/audit#audit_log_entry_structure payload = cloudevent.data.get("protoPayload") if payload: print(f"API method: {payload.get('methodName')}") print(f"Resource name: {payload.get('resourceName')}") print(f"Principal: {payload.get('authenticationInfo', dict()).get('principalEmail')}") row_count = payload.get('metadata', dict()).get('tableDataChange',dict()).get('insertedRowsCount') print(f"No. of rows: {row_count} !!") if row_count: if int(row_count) > 0: print ("Pipeline trigger Condition met !!") submit_pipeline_job() else: print ("No pipeline triggered !!!") def submit_pipeline_job(): PROJECT_ID = 'PROJECT_ID' REGION = 'REGION' BUCKET_NAME = "BUCKET_NAME" DATASET_NAME = "mlops" TABLE_NAME = "chicago" base_output_dir = BUCKET_NAME BUCKET_URI = "gs://{}".format(BUCKET_NAME) PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-mlops-pipeline-tutorial" EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" REPO_NAME ="mlops" TEMPLATE_NAME="custom-model-training-evaluation-pipeline" TRAINING_JOB_DISPLAY_NAME="taxifare-prediction-training-job" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID,"--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False } TEMPLATE_URI = f"http://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest" print("TEMPLATE URI: ", TEMPLATE_URI) request_body = { "name": PIPELINE_NAME, "displayName": PIPELINE_NAME, "runtimeConfig":{ "gcsOutputDirectory": PIPELINE_ROOT, "parameterValues": parameters, }, "templateUri": TEMPLATE_URI } pipeline_url = "http://us-central1-aiplatform.googleapis.com/v1/projects/{}/locations/{}/pipelineJobs".format(PROJECT_ID, REGION) creds, project = google.auth.default() auth_req = google.auth.transport.requests.Request() creds.refresh(auth_req) headers = { 'Authorization': 'Bearer {}'.format(creds.token), 'Content-Type': 'application/json; charset=utf-8' } response = requests.request("POST", pipeline_url, headers=headers, data=json.dumps(request_body)) print(response.text)Öffnen Sie die Datei
requirements.txtund ersetzen Sie den Inhalt durch Folgendes:requests==2.31.0 google-auth==2.25.1
Klicken Sie auf Bereitstellen, um die Funktion bereitzustellen.
Daten einfügen, um die Pipeline auszulösen
Wechseln Sie in der Google Cloud Console zu BigQuery Studio.
Klicken Sie auf SQL-Abfrage erstellen und führen Sie die folgende SQL-Abfrage aus. Klicken Sie dazu auf Ausführen.
INSERT INTO `PROJECT_ID.mlops.chicago` ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2022 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )Diese SQL-Abfrage zum Einfügen neuer Zeilen in die Tabelle.
Suchen Sie im Log der Funktion nach
pipeline trigger condition met, um zu prüfen, ob das Ereignis ausgelöst wurde.Wenn die Funktion erfolgreich ausgelöst wird, sollte in Vertex AI Pipelines eine neue Pipeline ausgeführt werden. Der Pipelinejob dauert etwa 30 Minuten.
Bereinigen
Wenn Sie alle für dieses Projekt verwendeten Google Cloud-Ressourcen bereinigen möchten, können Sie das Google Cloud-Projekt löschen, das Sie für diese Anleitung verwendet haben.
Andernfalls können Sie die einzelnen Ressourcen löschen, die Sie für diese Anleitung erstellt haben.
Löschen Sie Ressourcen aus Vertex AI.
Löschen Sie Modelle aus Vertex AI Model Registry.
Die anderen Vertex AI-Ressourcen sind nur Datensätze von Jobs, die zuvor ausgeführt wurden.
Löschen Sie Pipelineausführungen:
Löschen Sie benutzerdefinierte Trainingsjobs:
Zu „Benutzerdefinierte Trainingsjobs“
Löschen Sie Batchvorhersagejobs: