Este guia para iniciantes é uma introdução à previsão de modelos personalizados na Vertex AI.
Objetivos de aprendizado
Nível de experiência da Vertex AI: iniciante
Tempo de leitura estimado: 15 minutos
O que você vai aprender:
- Benefícios do serviço de previsão gerenciado.
- Como as previsões em lote funcionam na Vertex AI.
- Como as previsões on-line funcionam na Vertex AI.
Por que usar um serviço de previsão gerenciado?
Imagine que você tenha a tarefa de criar um modelo que usa como entrada uma imagem de uma planta e prevê a espécie. Para isso, comece treinando um modelo em um notebook, testando hiperparâmetros e arquiteturas diferentes. Quando você tiver um modelo treinado, será possível chamar o método predict no framework de ML de sua escolha e testar a qualidade do modelo.
Esse fluxo de trabalho é ótimo para experimentação, mas quando você quiser usar o modelo para receber previsões sobre muitos dados ou para receber previsões de baixa latência em tempo real, precisará de algo mais do que um notebook. Por exemplo, digamos que você esteja tentando medir a biodiversidade de um determinado ecossistema. Em vez de fazer com que os seres humanos identifiquem e contem manualmente espécies de plantas na natureza, você usa esse modelo de ML para classificar grandes lotes de imagens. Se você estiver usando um notebook, pode atingir as restrições de memória. Além disso, receber previsões para todos esses dados provavelmente é um job de longa duração que pode expirar no notebook.
E se você quiser usar esse modelo em um aplicativo em que os usuários possam fazer upload de imagens de plantas e fazer com que elas sejam identificadas imediatamente? Você precisará de um lugar para hospedar o modelo que existe fora de um notebook que o aplicativo pode chamar para uma previsão. Além disso, é improvável que você tenha tráfego consistente no seu modelo. Por isso, é recomendável ter um serviço com escalonamento automático quando necessário.
Em todos esses casos, um serviço de previsão gerenciado vai reduzir o atrito da hospedagem e do uso de modelos de ML. Neste guia, apresentamos uma introdução à previsão de modelos de ML na Vertex AI. Há outras personalizações, recursos e maneiras de interagir com o serviço que não são abordados aqui. O objetivo deste guia é fornecer uma visão geral. Para mais detalhes, consulte a documentação de treinamento da Vertex AI.
Visão geral do serviço de previsão gerenciado
A Vertex AI oferece suporte para previsões on-line e em lote.
A previsão em lote é uma solicitação assíncrona. É uma boa opção quando você não precisa de uma resposta imediata e quer processar dados acumulados em uma única solicitação. No exemplo discutido na introdução, esse seria o caso de uso de biodiversidade.
Se quiser receber previsões de baixa latência de dados transmitidos ao modelo em tempo real, use a Previsão on-line. No exemplo discutido na introdução, este seria o caso de uso em que você quer incorporar o modelo a um app que ajude os usuários a identificar as espécies de plantas imediatamente.
Fazer upload do modelo para o Vertex AI Model Registry
Para usar o serviço de previsão, a primeira etapa é fazer upload do modelo de ML treinado para o Vertex AI Model Registry. Esse é um registro em que é possível gerenciar o ciclo de vida dos modelos.
Criar um recurso de modelo
Ao treinar modelos com o serviço de treinamento personalizado da Vertex AI, é possível importar o modelo automaticamente para o registro após a conclusão do job de treinamento. Se você pulou essa etapa ou treinou seu modelo fora da Vertex AI, é possível fazer upload manualmente pelo console do Google Cloud ou do SDK da Vertex AI para Python. Para isso, aponte para um local do Cloud Storage com os artefatos de modelo salvos. O formato desses artefatos de modelo pode ser savedmodel.pb, model.joblib, model.pkl etc., dependendo do framework de ML que você está usando.
O upload de artefatos para o Vertex AI Model Registry cria um recurso Model, que é visível no console do Google Cloud, conforme mostrado abaixo.
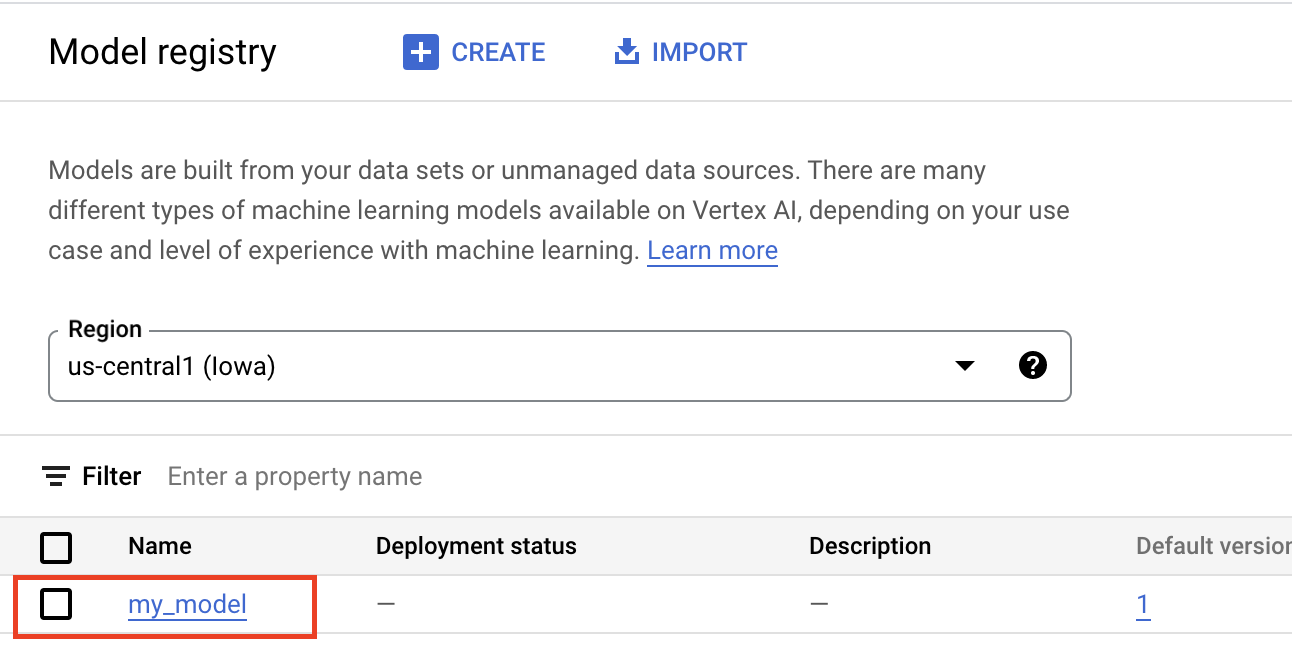
Selecionar um contêiner.
Ao importar um modelo para o Vertex AI Model Registry, é necessário associá-lo a um contêiner para que a Vertex AI exiba solicitações de previsão.
Contêineres pré-criados
A Vertex AI oferece contêineres pré-criados que podem ser usados para previsões. Os contêineres pré-criados são organizados por framework de ML e versão de framework e oferecem servidores de previsão HTTP que podem ser usados para exibir previsões com uma configuração mínima. Eles executam apenas a operação de previsão do framework de machine learning. Portanto, se você precisar pré-processar seus dados, isso precisará acontecer antes da solicitação de previsão. Da mesma forma, qualquer pós-processamento precisa acontecer depois da solicitação de previsão. Para um exemplo de uso de um contêiner pré-criado, consulte o notebook Como exibir modelos de imagem do PyTorch com contêineres pré-criados na Vertex AI
Contêineres personalizados
Se seu caso de uso exigir bibliotecas que não estão incluídas nos contêineres pré-criados ou se você tiver transformações de dados personalizadas que queira executar como parte da solicitação de previsão, use um contêiner personalizado que você{101 }criar e enviar para o Artifact Registry. Os contêineres personalizados permitem uma maior personalização, mas precisam executar um servidor HTTP. Especificamente o contêiner precisa detectar e responder a verificações de atividade, verificações de integridade e solicitações de previsão. Na maioria dos casos, usar um contêiner pré-criado, se possível, é a opção recomendada e mais simples. Para um exemplo de uso de um contêiner personalizado, consulte o notebook GPU única para classificação de imagem PyTorch usando o Vertex Training com contêiner personalizado
Rotinas de previsão personalizadas
Caso seu caso de uso precise de transformações personalizadas de pré e pós-processamento e você não quiser sobrecarregar a criação e a manutenção de um contêiner personalizado, use as Rotinas de previsão personalizadas. Com as rotinas de previsão personalizadas, é possível fornecer transformações de dados como código Python e, em segundo plano, o SDK da Vertex AI para Python vai criar um contêiner personalizado que pode ser testado localmente e implantado na Vertex AI. Para ver um exemplo de como usar as rotinas de previsão personalizadas, consulte o notebook Rotinas de previsão personalizadas com Sklearn.
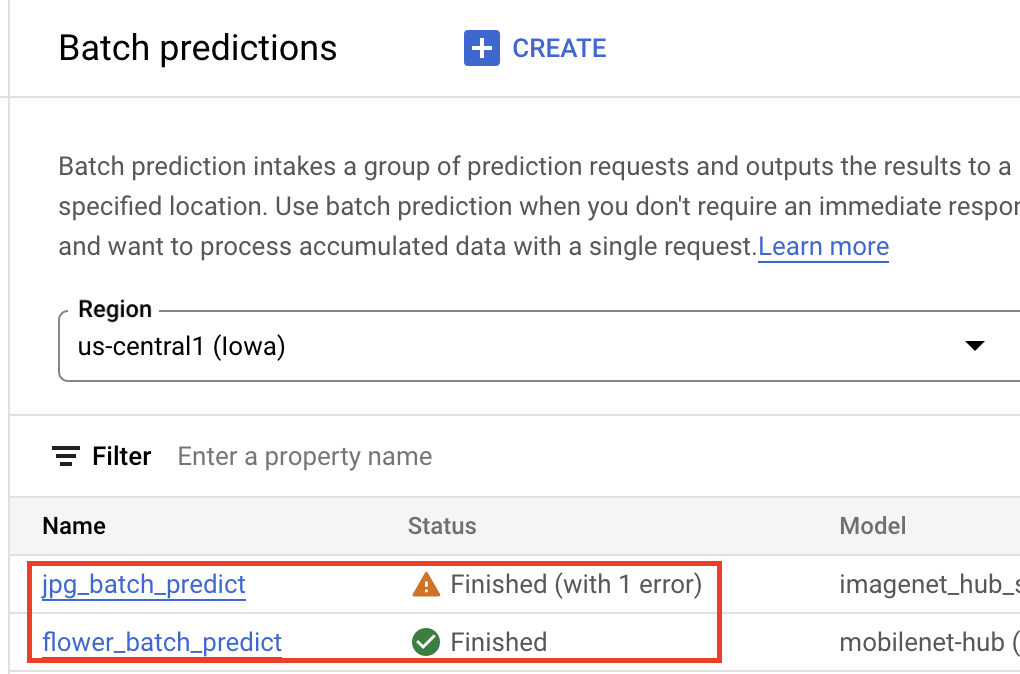
Receber previsões em lote
Depois que o modelo estiver no Vertex AI Model Registry, envie um job de previsão em lote pelo console do Google Cloud ou SDK da Vertex AI para Python. Especifique o local dos dados de origem e o local no Cloud Storage ou no BigQuery em que você quer que os resultados sejam salvos. Também é possível especificar o tipo de máquina em que esse job será executado e os aceleradores opcionais. Como o serviço de treinamento é totalmente gerenciado, a Vertex AI provisiona automaticamente os recursos de computação, executa a tarefa de treinamento e garante a exclusão de recursos de computação quando o job de treinamento é concluído. O status dos jobs de previsão em lote pode ser rastreado no Console do Google Cloud.
Receber previsões on-line
Se quiser receber previsões on-line, você precisa realizar a etapa extra de implantação do seu modelo em um endpoint da Vertex AI.
Isso associa os artefatos do modelo aos recursos físicos para baixa latência e cria um recurso DeployedModel.
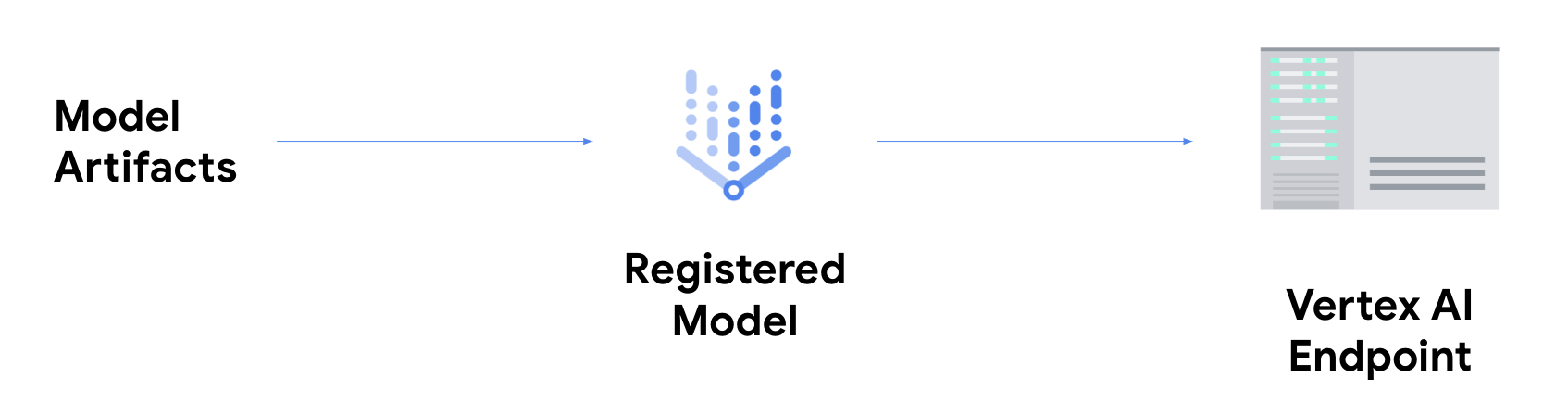
Depois que o modelo é implantado em um endpoint, ele aceita solicitações como qualquer outro endpoint REST, o que significa que é possível chamá-lo de uma função do Cloud, chatbot, app da Web etc. Observe que é possível implantar vários modelos em um único endpoint, dividindo o tráfego entre eles. Essa funcionalidade é útil, por exemplo, quando você quer lançar uma nova versão do modelo e não quer direcionar todo o tráfego para o novo modelo de forma imediata. Também é possível implantar o mesmo modelo em várias operações.
Recursos para receber previsões de modelos personalizados na Vertex AI
Para saber mais sobre como hospedar e exibir modelos na Vertex AI, consulte os recursos abaixo ou o repositório do GitHub de amostras da Vertex AI.
- Vídeo sobre como receber previsões
- Treinar e exibir um modelo do TensorFlow usando um contêiner pré-criado
- Como disponibilizar modelos de imagem do PyTorch com contêineres predefinidos na Vertex AI
- Exibir um modelo de difusão estável usando um contêiner pré-criado
- Rotinas de previsão personalizadas com o Sklearn