이 페이지에서는 예측 모델 학습에 사용되는 매개변수에 대한 자세한 정보를 제공합니다. 예측 모델을 학습시키는 방법은 예측 모델 학습 및 예측용 테이블 형식 워크플로를 사용한 모델 학습을 참조하세요.
모델 학습 방법
다음과 같은 모델 학습 방법 중에서 선택할 수 있습니다.
Time series Dense Encoder (TiDE): 최적화된 밀도 DNN-기반 인코더-디코더 모델입니다. 특히 긴 컨텍스트 및 호라이즌에서 빠른 학습 및 추론을 지원하는 뛰어난 모델 품질을 제공합니다. 자세히 알아보기
Temporal Fusion Transformer(TFT): 일반적인 다중 전망 예측 태스크에 모델을 맞춰 높은 정확성과 해석 가능성을 제공하도록 설계된 주의 기반 DNN 모델입니다. 자세히 알아보기
AutoML(L2L): 다양한 사용 사례에 적합합니다. 자세히 알아보기
Seq2Seq+: 실험에 적합합니다. 이 알고리즘은 아키텍처가 더 간단하고 사용하는 검색 공간이 더 작으므로 AutoML보다 빠르게 수렴할 가능성이 높습니다. 실험 결과 Seq2Seq+는 짧은 시간 예산과 1GB 미만의 데이터 세트에서 잘 작동합니다.
예측 시 특성 유형 및 가용성
예측 모델 학습에 사용되는 모든 열에는 속성 또는 공변 유형이 있어야 합니다. 예측 시점에 사용 가능하거나 사용할 수 없는 공변이 추가로 지정됩니다.
| 시리즈 유형 | 예측 시점에 사용 가능 | 설명 | 예시 | API 필드 |
|---|---|---|---|---|
| 속성 | 사용 가능 | 속성은 시간이 지남에 따라 변경되지 않는 정적 특성입니다. | 상품 색상, 제품 설명 | time_series_attribute_columns |
| 공변 | 사용 가능 |
시간이 지남에 따라 변화가 예상되는 외인적 변수입니다. 예측 시점에 사용 가능한 공변은 주요 지표입니다. 예측 범위 내 각 지점에 이 열의 예측 데이터를 제공해야 합니다. |
휴일, 예정된 프로모션 또는 이벤트 | available_at_forecast_columns |
| 공변 | 해당 없음 | 예측 시점에 공변을 사용할 수 없습니다. 예측을 만들 때 이러한 특성 값을 제공할 필요는 없습니다. | 실제 날씨입니다. | unavailable_at_forecast_columns |
특성 가용성과 예측 범위, 환경설정 기간, 예측 기간 간의 관계에 대해 자세히 알아보세요.
예측 범위, 환경설정 기간, 예측 기간
예측 특성은 정적 특성과 시간 변이 공변으로 구분됩니다.
예측 모델을 학습시킬 때는 어떤 공변 학습 데이터가 가장 중요한 캡처 대상인지 지정해야 합니다. 이는 다음으로 구성된 일련의 행인 예측 기간 형식으로 표현됩니다.
- 예측 시간까지의 컨텍스트 또는 과거 데이터
- 예측에 사용되는 범위 또는 행
종합해 보면 구간의 행은 모델 입력으로 사용되는 시계열 인스턴스를 정의합니다. 이 인스턴스는 Vertex AI가 학습하고, 평가하고, 예측에 사용하는 것입니다. 구간을 생성하는 데 사용되는 행은 범위의 첫 번째 행이며 시계열의 구간을 고유하게 식별합니다.
예측 범위는 모델이 예측 데이터 각 행의 타겟 값 예측을 수행할 향후 기간을 결정합니다.
환경설정 기간은 학습 중(또는 예측 시) 모델이 찾을 이전 기간을 설정합니다. 즉, 각 학습 데이터 포인트의 환경설정 기간은 모델이 예측 패턴을 찾는 이전 기간의 범위를 결정합니다. 환경설정 기간의 적절한 값을 찾기 위한 권장사항을 알아보세요.
예를 들어 환경설정 기간 = 14이고 예측 범위 = 7이면 각 기간 예시는 14 + 7 = 21 행을 가집니다.
예측에 사용 가능 여부
예측 공변은 예측 시 사용 가능한 공변과 예측 시 사용 불가능한 공변으로 나눌 수 있습니다.
예측 시 사용 가능한 공변을 처리할 때 Vertex AI는 학습, 평가, 예측에 환경설정 기간과 예측 범위의 공변 값을 모두 고려합니다. 예측 시 사용 불가능한 공변을 처리할 때 Vertex AI는 환경설정 기간의 공변 값을 고려하지만 예측 범위의 공변 값은 명시적으로 제외합니다.
순환 기간 전략
Vertex AI는 순환 기간 전략을 사용하여 입력 데이터에서 예측 기간을 생성합니다. 기본 전략은 개수입니다.
- 개수.
Vertex AI에서 생성된 구간 수는 사용자가 제공한 최댓값을 초과하지 않아야 합니다. 입력 데이터 세트의 행 수가 최대 구간 수보다 적으면 모든 행이 구간을 생성하는 데 사용됩니다.
그렇지 않으면 Vertex AI가 무작위 샘플링을 수행하여 행을 선택합니다.
최대 구간 수의 기본값은
100,000,000입니다. 최대 구간 수는100,000,000개를 초과할 수 없습니다. - 스트라이드.
Vertex AI는 모든 X 입력 행 중 하나를 사용하여 최대 100,000,000개의 구간을 생성합니다. 이 옵션은 계절별 또는 기간별 예측에 유용합니다. 예를 들어 스트라이드 길이 값을
7로 설정하여 예측을 특정 요일로 제한할 수 있습니다. 값은1에서1000사이일 수 있습니다. - 열.
값이
True또는False인 열을 입력 데이터에 추가할 수 있습니다. Vertex AI는 열의 값이True인 모든 입력 행의 구간을 생성합니다.True행의 총 개수가100,000,000미만이면True및False값을 원하는 순서로 설정할 수 있습니다. 부울 값이 선호되지만 문자열 값도 허용됩니다. 문자열 값은 대소문자를 구분하지 않습니다.
기본 100,000,000 구간보다 적게 생성하면 사전 처리 및 모델 평가에 필요한 시간을 줄일 수 있습니다. 또한 구간 다운샘플링을 사용하면 학습 중에 인식되는 구간의 분포를 보다 세부적으로 제어할 수 있습니다.
이 방법을 적절히 사용하면 결과의 품질과 일관성이 향상될 수 있습니다.
학습 및 예측 중에 환경설정 기간과 예측 범위가 사용되는 방식
환경설정 기간이 5개월이고 예측 범위가 5개월인 데이터가 월별로 수집된다고 가정해 보겠습니다. 12개월 간의 데이터로 모델을 학습시키면 다음과 같은 입력 및 예측 집합이 생성됩니다.
[1-5]:[6-10][2-6]:[7-11][3-7]:[8-12]
학습 후에 이 모델을 사용하여 13~17개월을 예측할 수 있습니다.
[8-12]:[13-17]
모델은 환경설정 기간에 속하는 데이터만 사용하여 예측을 수행합니다. 제공한 데이터 중 환경설정 기간을 벗어나는 모든 데이터가 무시됩니다.
13개월 차 데이터가 수집되면 이를 사용하여 18개월까지 예측할 수 있습니다.
[9-13]:[14-18]
결과가 양호한 경우 계속 진행할 수 있습니다. 결국 새 데이터로 모델을 재학습시킬 수 있습니다. 예를 들어 6개월 간의 데이터를 더 추가한 후 모델을 재학습시킨 경우 학습 데이터는 다음과 같이 사용됩니다.
[2-6]:[7-11][3-7]:[8-12][4-8]:[9-13][5-9]:[10-14][6-10]:[11-15][7-11]:[12-16][8-12]:[13-17][9-13]:[14-18]
그런 다음 모델을 사용하여 19~23개월을 예측할 수 있습니다.
[14-18]:[19-23]
예측 모델의 최적화 목표
모델을 학습시킬 때 Vertex AI는 모델 유형과 타겟 열에 사용된 데이터 유형을 기반으로 기본 최적화 목표를 선택합니다. 다음 표에서는 예측 모델이 가장 적합한 문제에 관한 몇 가지 세부정보를 제공합니다.
| 최적화 목표 | API 값 | 목표 사용 목적 |
|---|---|---|
| RMSE | minimize-rmse |
평균 제곱근 오차(RMSE)를 최소화합니다. 더 극한의 값을 정확하게 캡처하면 예측을 집계할 때 편향이 줄어듭니다. 기본값 |
| MAE | minimize-mae |
평균 절대 오차(MAE)를 최소화합니다. 극한 값을 모델에 미치는 영향이 적은 이상점으로 봅니다. |
| RMSLE | minimize-rmsle |
평균 제곱근 로그 오차(RMSLE)를 최소화합니다. 절댓값이 아닌 상대적 크기를 바탕으로 오류에 페널티를 적용합니다. 예측 값과 실제 값이 둘 다 클 때 유용합니다. |
| RMSPE | minimize-rmspe |
평균 제곱근 로그 오차(RMSPE)를 최소화합니다. 광범위한 값을 정확하게 캡처합니다. RMSE와 비슷하지만 대상의 규모를 기준으로 합니다. 값의 범위가 크면 유용합니다. |
| WAPE | minimize-wape-mae |
가중치가 적용된 절대 백분율 오차(WAPE)와 평균 절대 오차(MAE)의 조합을 최소화합니다. 실제 값이 작을 때 유용합니다. |
| 분위수 손실 | minimize-quantile-loss |
정의된 분위수의 조정된 핀볼 손실을 최소화하여 추정치의 불확실성을 수치화합니다. 분위수 예측은 예측의 불확실성을 수치화합니다. 이는 예측이 범위 내에 있을 가능성을 측정합니다. |
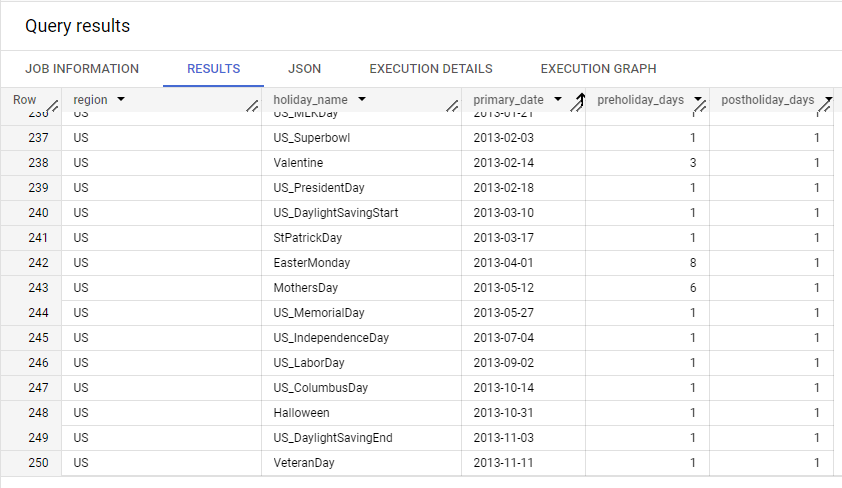
휴일 리전
특정 사용 사례에서는 리전별 휴일에 해당하는 날에 데이터 예측이 불규칙하게 작동할 수 있습니다. 모델에서 이 효과를 고려하려면 입력 데이터에 해당하는 지리적 리전을 하나 이상 선택합니다. 학습 중에 Vertex AI는 시간 열의 날짜와 지정된 지리적 리전을 기준으로 모델 내에 휴일 범주형 특성을 만듭니다.
다음은 미국의 날짜 및 휴일 범주형 특성의 일부입니다. 기본 날짜, 하나 이상의 휴일 전 날짜, 하나 이상의 휴일 후 날짜에 범주형 특성이 할당됩니다. 예를 들어 2013년 미국 어머니의 날의 기본 날짜는 5월 12일입니다. 기본 날짜, 휴일 전 6일, 휴일 후 1일에 어머니의 날 특성이 할당됩니다.
| 날짜 | 휴일 범주형 특성 |
|---|---|
| 2013-05-06 | MothersDay |
| 2013-05-07 | MothersDay |
| 2013-05-08 | MothersDay |
| 2013-05-09 | MothersDay |
| 2013-05-10 | MothersDay |
| 2013-05-11 | MothersDay |
| 2013-05-12 | MothersDay |
| 2013-05-13 | MothersDay |
| 2013-05-26 | US_MemorialDay |
| 2013-05-27 | US_MemorialDay |
| 2013-05-28 | US_MemorialDay |
휴일 리전에 허용되는 값은 다음과 같습니다.
GLOBAL: 모든 전 세계 리전의 휴일을 감지합니다.NA: 북미의 휴일을 감지합니다.JAPAC: 일본 및 아시아 태평양의 휴일을 감지합니다.EMEA: 유럽, 중동, 아프리카의 휴일을 감지합니다.LAC: 라틴 아메리카 및 카리브해의 휴일을 감지합니다.- ISO 3166-1 국가 코드: 개별 국가의 휴일을 감지합니다.
각 지리적 리전의 전체 휴일 날짜 목록을 보려면 BigQuery의 holidays_and_events_for_forecasting 테이블을 참조하세요. 다음 단계를 수행하여 Google Cloud 콘솔을 통해 이 테이블을 열 수 있습니다.
-
Google Cloud 콘솔의 BigQuery 섹션에서 BigQuery Studio 페이지로 이동합니다.
- 탐색기 패널에서
bigquery-public-data프로젝트를 엽니다. 이 프로젝트를 찾을 수 없거나 자세히 알아보려면 공개 데이터 세트 열기를 참조하세요. ml_datasets데이터 세트를 엽니다.holidays_and_events_for_forecasting테이블을 엽니다.
다음은 holidays_and_events_for_forecasting 테이블에서 발췌한 부분입니다.