이 페이지에서는 예측용 테이블 형식 워크플로를 사용하여 테이블 형식 데이터 세트에서 예측 모델을 학습시키는 방법을 보여줍니다.
이 워크플로에 사용되는 서비스 계정에 대한 자세한 내용은 테이블 형식 워크플로의 서비스 계정을 참조하세요.
예측용 테이블 형식 워크플로를 실행하는 동안 할당량과 관련된 오류가 발생하면 할당량 상향을 요청해야 할 수 있습니다. 자세한 내용은 테이블 형식 워크플로의 할당량 관리를 참조하세요.
예측용 테이블 형식 워크플로는 모델 내보내기를 지원하지 않습니다.
워크플로 API
이 워크플로에서는 다음 API를 사용합니다.
- Vertex AI
- Dataflow
- Compute Engine
- Cloud Storage
이전 초매개변수 조정 결과의 URI 가져오기
이전에 예측 실행을 위한 테이블 형식 워크플로를 완료한 경우 이전 실행의 초매개변수 조정 결과를 사용하여 학습 시간과 리소스를 절약할 수 있습니다. Google Cloud 콘솔을 사용하거나 API를 사용하여 프로그래매틱 방식으로 로드하여 이전 초매개변수 조정 결과를 찾을 수 있습니다.
Google Cloud 콘솔
Google Cloud 콘솔을 사용하여 초매개변수 조정 결과 URI를 찾으려면 다음 단계를 수행합니다.
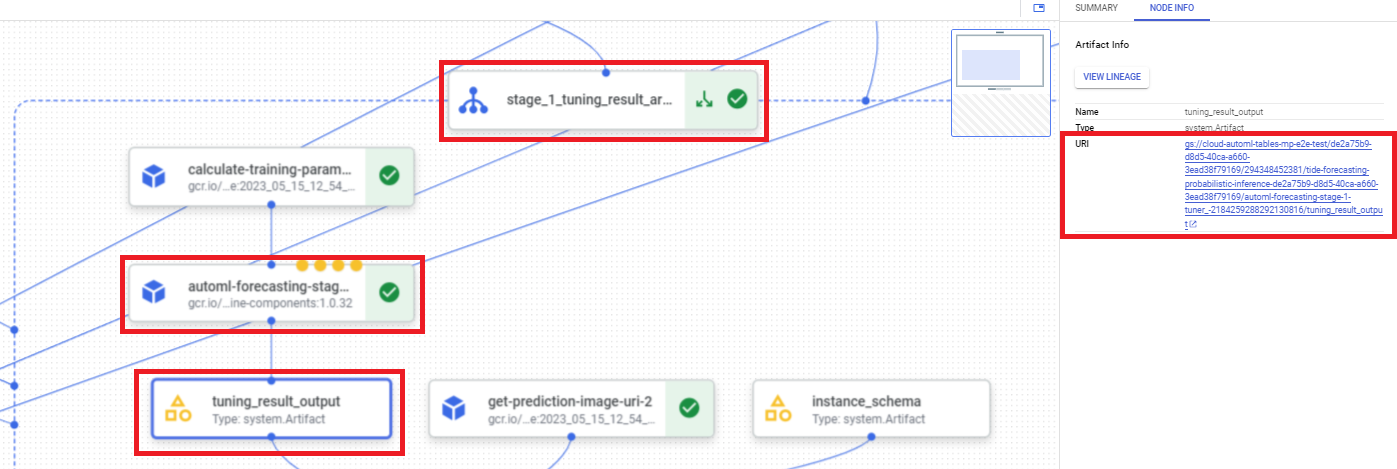
Google Cloud 콘솔의 Vertex AI 섹션에서 파이프라인 페이지로 이동합니다.
실행 탭을 선택합니다.
사용할 파이프라인 실행을 선택합니다.
아티팩트 펼치기를 선택합니다.
구성요소 exit-handler-1을 클릭합니다.
구성요소 stage_1_tuning_result_artifact_uri_empty를 클릭합니다.
구성요소 automl-forecasting-stage-1-tuner를 찾습니다.
연결된 아티팩트 tuning_result_output을 클릭합니다.
노드 정보 탭을 선택합니다.
모델 학습 단계에서 사용할 URI를 복사합니다.
API: Python
다음 샘플 코드에서는 API를 사용하여 초매개변수 조정 결과를 로드하는 방법을 보여줍니다. job 변수는 이전 모델 학습 파이프라인 실행을 나타냅니다.
def get_task_detail(
task_details: List[Dict[str, Any]], task_name: str
) -> List[Dict[str, Any]]:
for task_detail in task_details:
if task_detail.task_name == task_name:
return task_detail
pipeline_task_details = job.gca_resource.job_detail.task_details
stage_1_tuner_task = get_task_detail(
pipeline_task_details, "automl-forecasting-stage-1-tuner"
)
stage_1_tuning_result_artifact_uri = (
stage_1_tuner_task.outputs["tuning_result_output"].artifacts[0].uri
)
모델 학습
다음 샘플 코드에서는 모델 학습 파이프라인을 실행하는 방법을 보여줍니다.
job = aiplatform.PipelineJob(
...
template_path=template_path,
parameter_values=parameter_values,
...
)
job.run(service_account=SERVICE_ACCOUNT)
job.run()의 선택사항인 service_account 매개변수를 사용하면 Vertex AI Pipelines 서비스 계정을 원하는 계정으로 설정할 수 있습니다.
Vertex AI는 모델 학습을 위해 다음 방법을 지원합니다.
TiDE(Time series Dense Encoder). 이 모델 학습 방법을 사용하려면 다음 함수를 사용하여 파이프라인 및 매개변수 값을 정의합니다.
template_path, parameter_values = automl_forecasting_utils.get_time_series_dense_encoder_forecasting_pipeline_and_parameters(...)TFT(Temporal Fusion Transformer). 이 모델 학습 방법을 사용하려면 다음 함수를 사용하여 파이프라인 및 매개변수 값을 정의합니다.
template_path, parameter_values = automl_forecasting_utils.get_temporal_fusion_transformer_forecasting_pipeline_and_parameters(...)AutoML(L2L). 이 모델 학습 방법을 사용하려면 다음 함수를 사용하여 파이프라인 및 매개변수 값을 정의합니다.
template_path, parameter_values = automl_forecasting_utils.get_learn_to_learn_forecasting_pipeline_and_parameters(...)Seq2Seq+. 이 모델 학습 방법을 사용하려면 다음 함수를 사용하여 파이프라인 및 매개변수 값을 정의합니다.
template_path, parameter_values = automl_forecasting_utils.get_sequence_to_sequence_forecasting_pipeline_and_parameters(...)
자세한 내용은 모델 학습 방법을 참조하세요.
학습 데이터는 Cloud Storage의 CSV 파일이거나 BigQuery의 테이블일 수 있습니다.
다음은 모델 학습 매개변수의 하위 집합입니다.
| 매개변수 이름 | 유형 | 정의 |
|---|---|---|
optimization_objective |
문자열 | 기본적으로 Vertex AI는 평균 제곱근 오차(RMSE)를 최소화합니다. 예측 모델의 다른 최적화 목표를 원하는 경우 예측 모델의 최적화 목표에 있는 옵션 중 하나를 선택합니다. 분위수 손실을 최소화하려면 quantiles 값도 지정해야 합니다. |
enable_probabilistic_inference |
불리언 | true로 설정하면 Vertex AI에서 예측의 확률 분포를 모델링합니다. 확률적 추론은 노이즈가 많은 데이터를 처리하고 불확실성을 수치화하여 모델 품질을 향상시킬 수 있습니다. quantiles가 지정되면 Vertex AI에서 분포의 분위수를 반환합니다. 확률적 추론은 시계열 밀집 인코더(TiDE) 및 AutoML(L2L) 학습 메서드와만 호환됩니다. 확률적 추론은 minimize-quantile-loss 최적화 목표와 호환되지 않습니다. |
quantiles |
List[float] | minimize-quantile-loss 최적화 목표 및 확률적 추론에 사용할 분위수입니다. 0~1 사이의 고유 숫자 최대 5개 목록을 입력합니다. |
time_column |
문자열 | 시간 열입니다. 자세한 내용은 데이터 구조 요구사항을 참조하세요. |
time_series_identifier_columns |
목록[str] | 시계열 식별자 열입니다. 자세한 내용은 데이터 구조 요구사항을 참조하세요. |
weight_column |
문자열 | (선택사항) 가중치 열입니다. 자세한 내용은 학습 데이터에 가중치 추가를 참조하세요. |
time_series_attribute_columns |
목록[str] | (선택사항) 시계열 속성인 열의 이름입니다. 자세한 내용은 예측 시 특성 유형 및 가용성을 참조하세요. |
available_at_forecast_columns |
목록[str] | (선택사항) 예측 시 값이 알려진 공변 열의 이름입니다. 자세한 내용은 예측 시 특성 유형 및 가용성을 참조하세요. |
unavailable_at_forecast_columns |
목록[str] | (선택사항) 예측 시 값을 알 수 없는 공변 열의 이름입니다. 자세한 내용은 예측 시 특성 유형 및 가용성을 참조하세요. |
forecast_horizon |
정수 | (선택사항) 예측 범위는 모델이 예측 데이터 각 행의 타겟 값 예측을 수행할 향후 기간을 결정합니다. 자세한 내용은 예측 범위, 컨텍스트 윈도우, 예측 기간을 참조하세요. |
context_window |
정수 | (선택사항) 컨텍스트 윈도우는 학습 중(또는 예측 시) 모델이 찾을 이전 기간을 설정합니다. 즉, 각 학습 데이터 포인트의 컨텍스트 윈도우는 모델이 예측 패턴을 찾는 이전 기간의 범위를 결정합니다. 자세한 내용은 예측 범위, 컨텍스트 윈도우, 예측 기간을 참조하세요. |
window_max_count |
정수 | (선택사항) Vertex AI는 순환 기간 전략을 사용하여 입력 데이터에서 예측 기간을 생성합니다. 기본 전략은 개수입니다. 최대 구간 수의 기본값은 100,000,000입니다. 최대 구간 수에 커스텀 값을 제공하려면 이 매개변수를 설정합니다. 자세한 내용은 순환 기간 전략을 참조하세요. |
window_stride_length |
정수 | (선택사항) Vertex AI는 순환 기간 전략을 사용하여 입력 데이터에서 예측 기간을 생성합니다. 스트라이드 전략을 선택하려면 이 매개변수를 스트라이드 길이 값으로 설정합니다. 자세한 내용은 순환 기간 전략을 참조하세요. |
window_predefined_column |
문자열 | (선택사항) Vertex AI는 순환 기간 전략을 사용하여 입력 데이터에서 예측 기간을 생성합니다. 열 전략을 선택하려면 이 매개변수를 True 또는 False 값이 있는 열의 이름으로 설정합니다. 자세한 내용은 순환 기간 전략을 참조하세요. |
holiday_regions |
목록[str] | (선택사항) 하나 이상의 지리적 리전을 선택하여 휴일 효과 모델링을 사용 설정할 수 있습니다. 학습 중에 Vertex AI는 time_column의 날짜와 지정된 지리적 리전을 기준으로 모델 내에 휴일 범주형 특성을 만듭니다. 기본적으로 휴일 효과 모델링은 사용 중지됩니다. 자세한 내용은 휴일 리전을 참조하세요. |
predefined_split_key |
문자열 | (선택사항) 기본적으로 Vertex AI는 시간순 분할 알고리즘을 사용하여 예측 데이터를 데이터 분할 3개로 분리합니다. 어떤 분할에 어떤 학습 데이터 행을 사용할지를 제어하려면 데이터 분할 값(TRAIN, VALIDATION, TEST)이 포함된 열의 이름을 제공합니다. 자세한 내용은 예측을 위한 데이터 분할을 참조하세요. |
training_fraction |
부동 소수점 | (선택사항) 기본적으로 Vertex AI는 시간순 분할 알고리즘을 사용하여 예측 데이터를 데이터 분할 3개로 분리합니다. 데이터의 80%는 학습 세트에 할당되고, 10%는 검증 분할에 할당되며, 10%는 테스트 분할에 할당됩니다. 학습 세트에 할당된 데이터 비율을 맞춤설정하려는 경우 이 매개변수를 설정합니다. 자세한 내용은 예측용 데이터 분할을 참조하세요. |
validation_fraction |
부동 소수점 | (선택사항) 기본적으로 Vertex AI는 시간순 분할 알고리즘을 사용하여 예측 데이터를 데이터 분할 3개로 분리합니다. 데이터의 80%는 학습 세트에 할당되고, 10%는 검증 분할에 할당되며, 10%는 테스트 분할에 할당됩니다. 검증 세트에 할당된 데이터 비율을 맞춤설정하려면 이 매개변수를 설정합니다. 자세한 내용은 예측용 데이터 분할을 참조하세요. |
test_fraction |
부동 소수점 | (선택사항) 기본적으로 Vertex AI는 시간순 분할 알고리즘을 사용하여 예측 데이터를 데이터 분할 3개로 분리합니다. 데이터의 80%는 학습 세트에 할당되고, 10%는 검증 분할에 할당되며, 10%는 테스트 분할에 할당됩니다. 테스트 세트에 할당된 데이터 비율을 맞춤설정하려면 이 매개변수를 설정합니다. 자세한 내용은 예측용 데이터 분할을 참조하세요. |
data_source_csv_filenames |
문자열 | Cloud Storage에 저장된 CSV의 URI입니다. |
data_source_bigquery_table_path |
문자열 | BigQuery 테이블의 URI입니다. |
dataflow_service_account |
문자열 | (선택사항) Dataflow 작업을 실행하기 위한 커스텀 서비스 계정입니다. 비공개 IP와 특정 VPC 서브넷을 사용하도록 Dataflow 작업은 비공개 IP와 특정 VPC 서브넷을 사용하도록 구성할 수 있습니다. 이 매개변수는 기본 Dataflow 작업자 서비스 계정을 재정의하는 역할을 합니다. |
run_evaluation |
불리언 | True로 설정하면 Vertex AI가 테스트 분할에서 앙상블 모델을 평가합니다. |
evaluated_examples_bigquery_path |
문자열 | 모델 평가 중에 사용된 BigQuery 데이터 세트의 경로입니다. 데이터 세트는 예측된 예시의 대상으로 작동합니다. run_evaluation이 True로 설정되어 있고 bq://[PROJECT].[DATASET] 형식이어야 하는 경우 이 매개변수 값을 설정해야 합니다. |
변환
자동 또는 유형 해결의 사전 매핑을 특성 열에 제공할 수 있습니다. 지원되는 유형은 자동, 숫자, 범주형, 텍스트, 타임스탬프입니다.
| 매개변수 이름 | 유형 | 정의 |
|---|---|---|
transformations |
사전[str, 목록[str]] | 자동 또는 유형 해결의 사전 매핑 |
다음 코드는 transformations 매개변수를 채우는 도우미 함수를 제공합니다. 또한 이 함수를 사용하여 features 변수로 정의된 열 집합에 자동 변환을 적용하는 방법을 보여줍니다.
def generate_transformation(
auto_column_names: Optional[List[str]]=None,
numeric_column_names: Optional[List[str]]=None,
categorical_column_names: Optional[List[str]]=None,
text_column_names: Optional[List[str]]=None,
timestamp_column_names: Optional[List[str]]=None,
) -> List[Dict[str, Any]]:
if auto_column_names is None:
auto_column_names = []
if numeric_column_names is None:
numeric_column_names = []
if categorical_column_names is None:
categorical_column_names = []
if text_column_names is None:
text_column_names = []
if timestamp_column_names is None:
timestamp_column_names = []
return {
"auto": auto_column_names,
"numeric": numeric_column_names,
"categorical": categorical_column_names,
"text": text_column_names,
"timestamp": timestamp_column_names,
}
transformations = generate_transformation(auto_column_names=features)
변환에 대한 자세한 내용은 데이터 유형 및 변환을 참조하세요.
워크플로 맞춤설정 옵션
파이프라인 정의 중에 전달되는 인수 값을 정의하여 예측용 테이블 형식 워크플로를 맞춤설정할 수 있습니다. 다음 방법으로 워크플로를 맞춤설정할 수 있습니다.
- 하드웨어 구성
- 아키텍처 검색 건너뛰기
하드웨어 구성
다음 모델 학습 매개변수를 사용하면 머신 유형과 학습용 머신 수를 구성할 수 있습니다. 이 옵션은 대규모 데이터 세트가 있고 이에 따라 머신 하드웨어를 최적화하려는 경우에 적합합니다.
| 매개변수 이름 | 유형 | 정의 |
|---|---|---|
stage_1_tuner_worker_pool_specs_override |
사전[문자열, 무관] | (선택사항) 학습에 사용할 머신 유형과 머신 수에 대한 커스텀 구성입니다. 이 매개변수는 파이프라인의 automl-forecasting-stage-1-tuner 구성요소를 구성합니다. |
다음은 TensorFlow chief 노드의 n1-standard-8 머신 유형과 TensorFlow 평가자 노드의 n1-standard-4 머신 유형을 설정하는 방법을 보여주는 코드입니다.
worker_pool_specs_override = [
{"machine_spec": {"machine_type": "n1-standard-8"}}, # override for TF chief node
{}, # override for TF worker node, since it's not used, leave it empty
{}, # override for TF ps node, since it's not used, leave it empty
{
"machine_spec": {
"machine_type": "n1-standard-4" # override for TF evaluator node
}
}
]
아키텍처 검색 건너뛰기
다음 모델 학습 매개변수를 사용하면 아키텍처를 검색하지 않고 파이프라인을 실행하고 대신 이전 파이프라인 실행의 초매개변수 집합을 제공할 수 있습니다.
| 매개변수 이름 | 유형 | 정의 |
|---|---|---|
stage_1_tuning_result_artifact_uri |
문자열 | (선택사항) 이전 파이프라인 실행의 초매개변수 조정 결과에 대한 URI입니다. |
다음 단계
- 예측 모델의 일괄 예측 알아보기
- 모델 학습 가격 책정 알아보기