CustomTrainingJob.
Quando crei un CustomTrainingJob, definisci una pipeline di addestramento in background. Vertex AI utilizza la pipeline di addestramento e il codice nello
script di addestramento Python per addestrare e creare il modello. Per ulteriori informazioni, consulta Creare pipeline di addestramento.
Definisci la pipeline di addestramento
Per creare una pipeline di addestramento, devi creare un oggetto CustomTrainingJob. Nel
passaggio successivo, utilizzerai il comando run di CustomTrainingJob per creare e
addestrare il modello. Per creare un CustomTrainingJob, devi passare i seguenti parametri
al suo costruttore:
display_name: la variabileJOB_NAMEche hai creato quando hai definito gli argomenti dei comandi per lo script di addestramento Python.script_path: il percorso dello script di addestramento Python che hai creato in precedenza in questo tutorial.container_url: l'URI di un'immagine container Docker utilizzata per addestrare il modello.requirements: l'elenco delle dipendenze del pacchetto Python dello script.model_serving_container_image_uri: l'URI di un'immagine container Docker che fornisce previsioni per il tuo modello. Può essere un container predefinito o una tua immagine personalizzata. Questo tutorial utilizza un container predefinito.
Esegui il codice seguente per creare la pipeline di addestramento. Il metodo CustomTrainingJob utilizza lo script di addestramento Python nel file task.py per creare una CustomTrainingJob.
job = aiplatform.CustomTrainingJob(
display_name=JOB_NAME,
script_path="task.py",
container_uri="us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8:latest",
requirements=["google-cloud-bigquery>=2.20.0", "db-dtypes", "protobuf<3.20.0"],
model_serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest",
)
Crea e addestra il modello
Nel passaggio precedente hai creato un elemento CustomTrainingJob denominato job. Per creare e addestrare il modello, chiama il metodo run sul tuo
oggetto CustomTrainingJob e trasmettilo i seguenti parametri:
dataset: il set di dati tabulare creato in precedenza in questo tutorial. Questo parametro può essere un set di dati tabulare, di immagine, video o testuale.model_display_name: il nome del modello.bigquery_destination: una stringa che specifica la posizione del tuo set di dati BigQuery.args: gli argomenti della riga di comando passati allo script di addestramento Python.
Per iniziare ad addestrare i dati e creare il modello, esegui il codice seguente nel blocco note:
MODEL_DISPLAY_NAME = "penguins_model_unique"
# Start the training and create your model
model = job.run(
dataset=dataset,
model_display_name=MODEL_DISPLAY_NAME,
bigquery_destination=f"bq://{project_id}",
args=CMDARGS,
)
Prima di procedere con il passaggio successivo, assicurati che nell'output del comando job.run venga visualizzato quanto segue:
CustomTrainingJob run completed.
Al termine del job di addestramento, puoi eseguire il deployment del modello.
Esegui il deployment del modello
Quando esegui il deployment del modello, crei anche una risorsa Endpoint che viene utilizzata per fare previsioni. Per eseguire il deployment del modello e creare un endpoint, esegui questo codice nel tuo blocco note:
DEPLOYED_NAME = "penguins_deployed_unique"
endpoint = model.deploy(deployed_model_display_name=DEPLOYED_NAME)
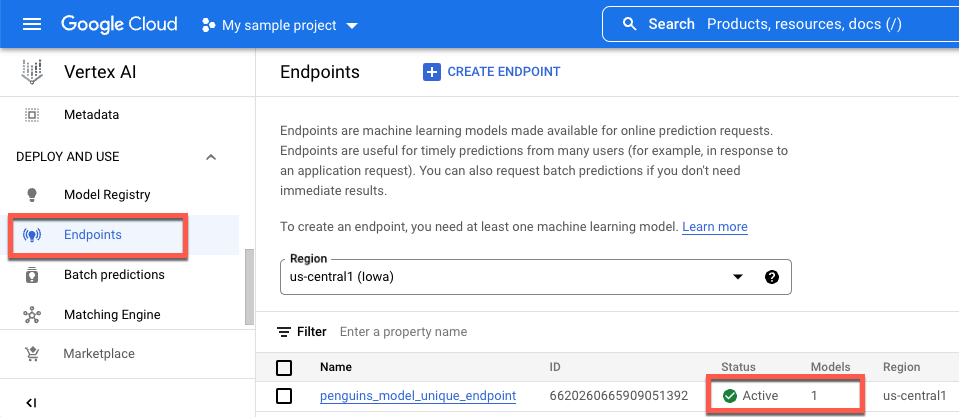
Attendi il deployment del modello prima di andare al passaggio successivo. Dopo il deployment del modello, l'output include il testo Endpoint model deployed. Puoi anche fare clic su Endpoint nel riquadro di navigazione a sinistra della console Vertex AI e monitorare il relativo valore in Modelli. Il valore è 0 dopo la creazione dell'endpoint e prima del deployment del modello. Dopo il deployment del modello, il valore
viene aggiornato a 1.
Di seguito viene mostrato un endpoint dopo la creazione e prima del deployment di un modello.
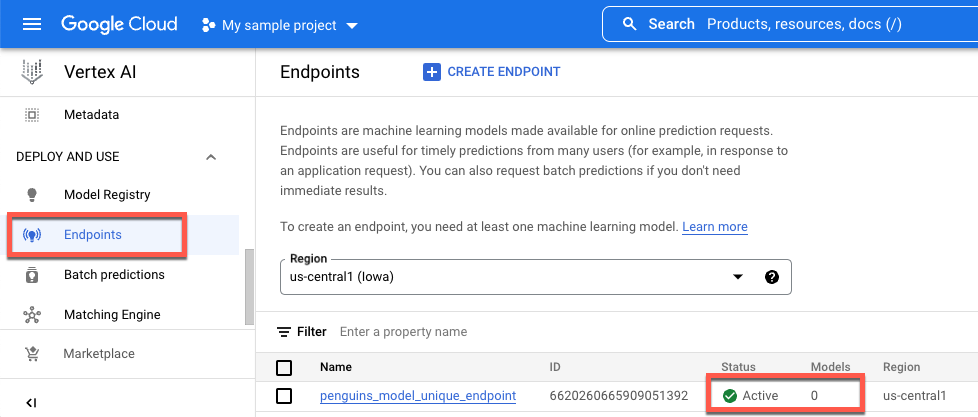
Di seguito viene mostrato un endpoint dopo la creazione e il deployment di un modello.